Capítulo 6 Sesgo e Inequidad
Machine Learning por naturaleza es discriminante, pues justo lo que hacemos es discriminar datos a través del uso de la estadística. Sin embargo, esta discriminación puede ser un problema cuando brinda ventajas sistemáticas a grupos privilegiados y desventajas sistemáticas a grupos no privilegiados. Por ejemplo: Privilegiar la atención médica a pacientes blancos sobre pacientes afroamericanos.
Un sesgo en el conjunto de entrenamiento ya sea por prejuicio o por un sobre/sub muestreo lleva a tener modelos sesgados.

Un mal entendido común al hacer modelos de machine learning consiste en evitar utilizar características que pueden generar una inquedidad por ejemplo: sexo, edad, etnia, etc. Sin embargo, no ocuparlos nos lleva a tener puntos ciegos en nuestros modelos para cuantificar si efectivamente tenemos un sesgo o inequidad en algunos grupos.
Deberemos de ocupar estas características en los modelos, justo porque queremos evitar estos sesgos. Para ello, identificaremos y cuantificaremos estos sesgos e inequedades en diferentes grupos para después mitigarlos y cuantificar la consecuencia en nuestras métricas de desempelo off line.
6.1 Propósito Vs Error
El siguiente árbol de decisión está desarrollado pensando desde el punto de vista del tomador de decisiones -operativas- al que ayudamos desarrollando un modelo de machine learning para identificar en qué métricas deberíamos de concentrarnos para cuantificar el sesgo y la inequidad (bias y fairness).
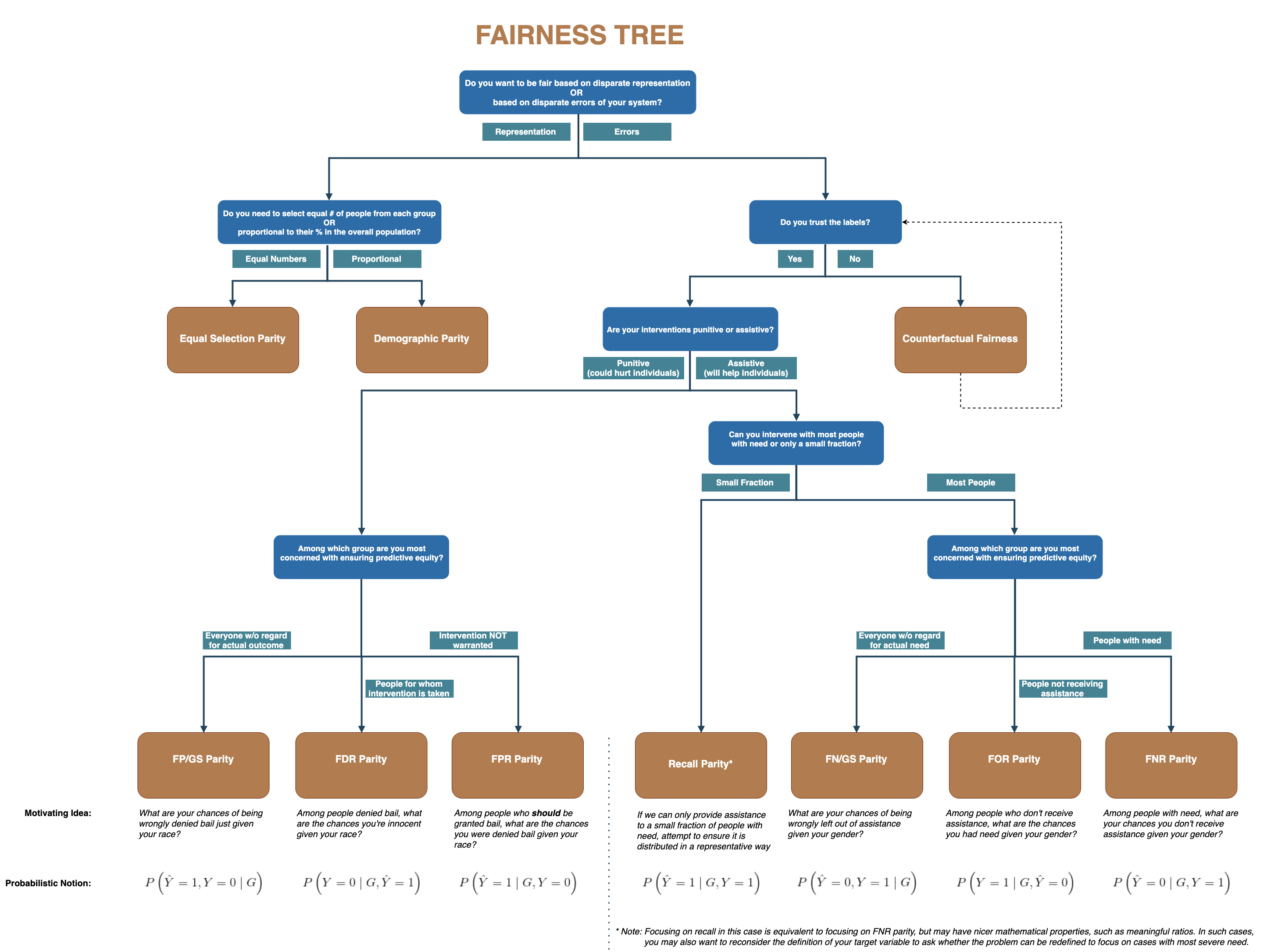
Métricas
FP/GS: False Positive over Group Size. Es el riesgo de ser incorrectamente clasificado como positivo, dado el grupo de pertenencia
FDR: False Discovery Rate. Es similar al error tipo 1 en pruebas de hipótesis estadísticas.
FPR: False Positive Rate.
Recall: Cobertura del modelo respecto al total de positivos.
FN/GS: False Negative over Group Size. Es el riesgo de ser incorrectamente clasificado como negativo, dado el grupo de pertenencia
FOR: False Omission Rate. Similar al error tipo 2 en pruebas de hipótesis estadísticas.
FNR: False Negative Rate
Tipo de modelo | Aplicación
Modelo Punitivo: Corresponde a modelos en donde al menos una de las acciones asociadas a nuestro modelo de predicción está relacionada con un “castigo.” Por ejemplo: Algoritmos donde se predice la probabilidad de reincidencia en algún delito y que es tomada como variable para decidir si dan libertad provisional o no.
Modelo Asistivo: Corresponde a modelos en donde la acción asociada al modelo son del estilo de preventivo. Por ejemplo: Priorización de inspecciones a realizar: médicas, a hogares, a estaciones de generación de energía, etc.
RECORDATORIO
| PREDICTED | REAL | |
|---|---|---|
| TP | 1 | 1 |
| FP | 1 | 0 |
| TN | 0 | 0 |
| FN | 0 | 1 |
\[(1-\tau) \leq \text{Medida de disparidad}_\text{grupo i} \leq \frac{1}{(1 - \tau)}, \]
donde \(\tau\) es el fairness threshold definido por nosotros. En los siguientes ejemplos utilizaremos \(\tau=20%\) por lo que cualquier métrica de paridad que se encuentre entre \(0.8\) y \(1.25\) va a ser tratado como justo (sin sesgo).
6.2 Métricas
El paquete fairness implementa \(11\) métricas de equidad. Muchos de estos son mutuamente excluyentes: los resultados para un problema de clasificación, a menudo no pueden ser justos en términos de todas las métricas. Dependiendo del contexto, es importante seleccionar una métrica adecuada para evaluar la equidad.
A continuación, se describen las funciones utilizadas para calcular las métricas implementadas. Cada función tiene un conjunto similar de argumentos:
data:data.frameque contiene los datos de entrada y las predicciones del modelogrupo: nombre de la columna que indica el grupo base (variable de factor)base: nivel base del grupo base para el cálculo de métricas de equidadresultado: nombre de la columna que indica la variable de resultado binariaresult_base: nivel base de la variable de resultado (es decir, clase negativa) para el cálculo de métricas de equidad
También necesitamos proporcionar predicciones de modelos, estas predicciones se pueden agregar al data.frame original o se pueden proporcionar como un vector. Cuando se trabaja con predicciones probabilísticas, algunas métricas requieren un valor de corte para convertir probabilidades en predicciones de clase proporcionadas como límite.
6.2.1 Equal Parity or Demographic or Statistical Parity
Cuando nos interesa que cada grupo de la variable “protegida” tenga la misma proporción de etiquetas positivas predichas (TP). Por ejemplo: En un modelo que predice si darte o no un crédito, nos gustaría que sin importar el género de la persona tuvieran la misma oportunidad.
La paridad demográfica se calcula en base a la comparación del número absoluto de todos los individuos clasificados positivamente en todos los subgrupos de datos. En el resiltado del vector con nombres, al grupo de referencia se le asignará 1, mientras que a todos los demás grupos se les asignarán valores según si su proporción de observaciones pronosticadas positivamente es menor o mayor en comparación con el grupo de referencia. Las proporciones más bajas se reflejarán en números inferiores a 1 en el vector con resultado de nombre.
Fórmula: \(TP + FP\)
Se utiliza esta métrica cuando:
- Queremos cambiar el estado actual para “mejorarlo.” Por ejemplo: Ver más personas de grupos desfavorecidos con mayor oportunidad de tener un préstamo.
- Conocemos que ha habido una ventaja histórica que afecta los datos con los que construiremos el modelo.
Al querer eliminar las desventajas podríamos poner en más desventaja al grupo que históricamente ha tenido desventaja, ya que no está preparado (literalmente) para recibir esa ventaja. Por ejemplo, si damos créditos a grupos a los que antes de hacer fairness no lo hacíamos, sin ninguna educación financiera o apoyo de educación financiera de nuestra parte, muy probablemente esas personas caerán en default aumentando el sesgo que ya teníamos inicialmente.
library(tidymodels)
library(fairness)
library(magrittr)
data(compas)
compas %<>%
mutate(Two_yr_Recidivism_01 = if_else(Two_yr_Recidivism == 'yes', 1, 0))
glimpse(compas)## Rows: 6,172
## Columns: 10
## $ Two_yr_Recidivism <fct> no, yes, no, no, no, no, yes, yes, yes, no, no, n…
## $ Number_of_Priors <dbl> -0.6843578, 2.2668817, -0.6843578, -0.6843578, -0…
## $ Age_Above_FourtyFive <fct> no, no, no, no, no, no, no, no, no, no, no, no, n…
## $ Age_Below_TwentyFive <fct> no, no, no, no, no, no, no, no, no, yes, no, no, …
## $ Female <fct> Male, Male, Female, Male, Male, Male, Male, Male,…
## $ Misdemeanor <fct> yes, no, yes, no, yes, yes, no, no, no, no, no, y…
## $ ethnicity <fct> Other, Caucasian, Caucasian, African_American, Hi…
## $ probability <dbl> 0.3151557, 0.8854616, 0.2552680, 0.4173908, 0.320…
## $ predicted <dbl> 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1…
## $ Two_yr_Recidivism_01 <dbl> 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1…dem_parity(
data = compas,
outcome = 'Two_yr_Recidivism_01',
group = 'ethnicity',
probs = 'probability',
cutoff = 0.4,
base = 'Caucasian'
)## $Metric
## Caucasian African_American Asian Hispanic
## Positively classified 1070 2599.000000 7.000000000 214.0
## Demographic Parity 1 2.428972 0.006542056 0.2
## Group size 2103 3175.000000 31.000000000 509.0
## Native_American Other
## Positively classified 7.000000000 152.0000000
## Demographic Parity 0.006542056 0.1420561
## Group size 11.000000000 343.0000000
##
## $Metric_plot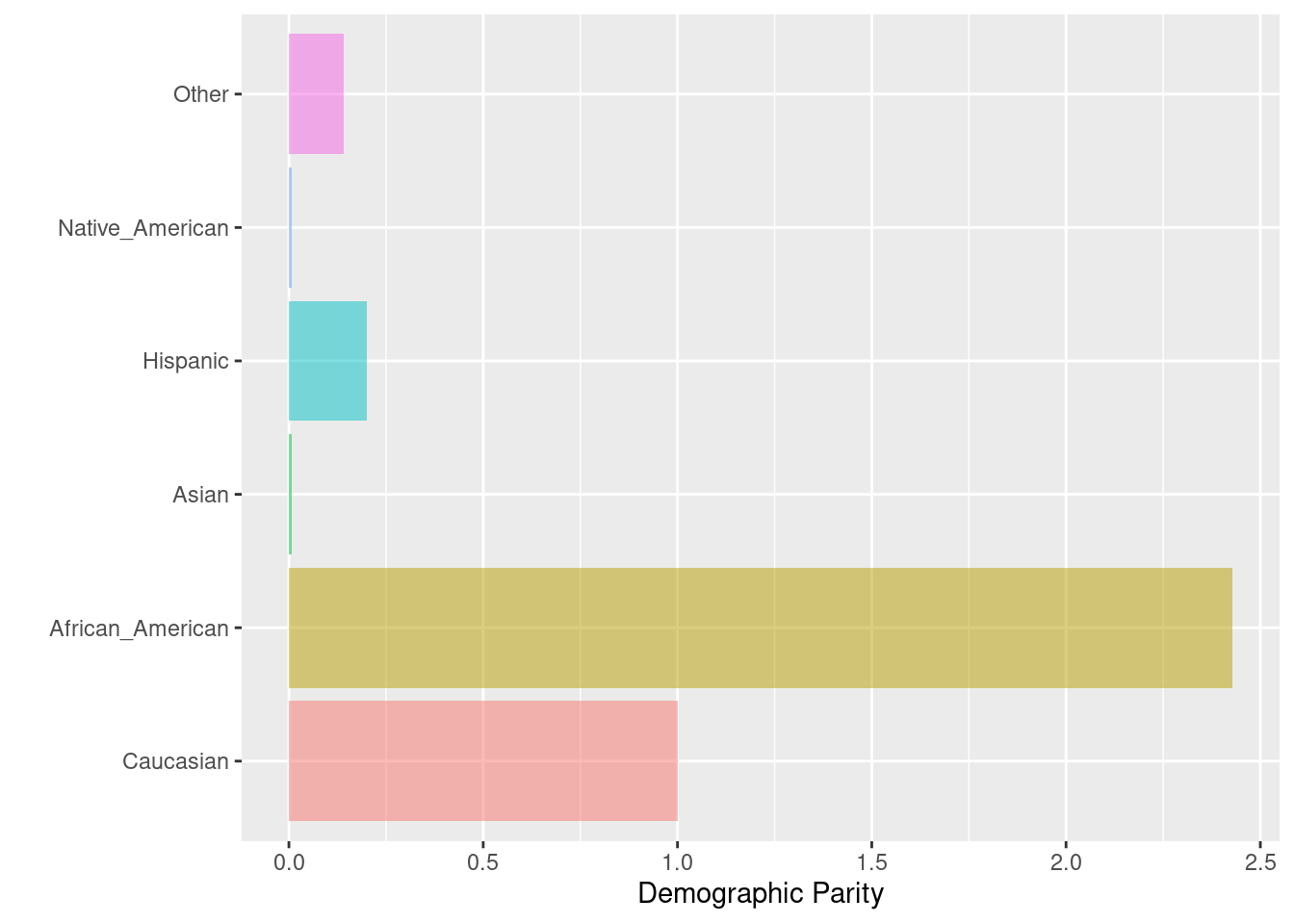
##
## $Probability_plot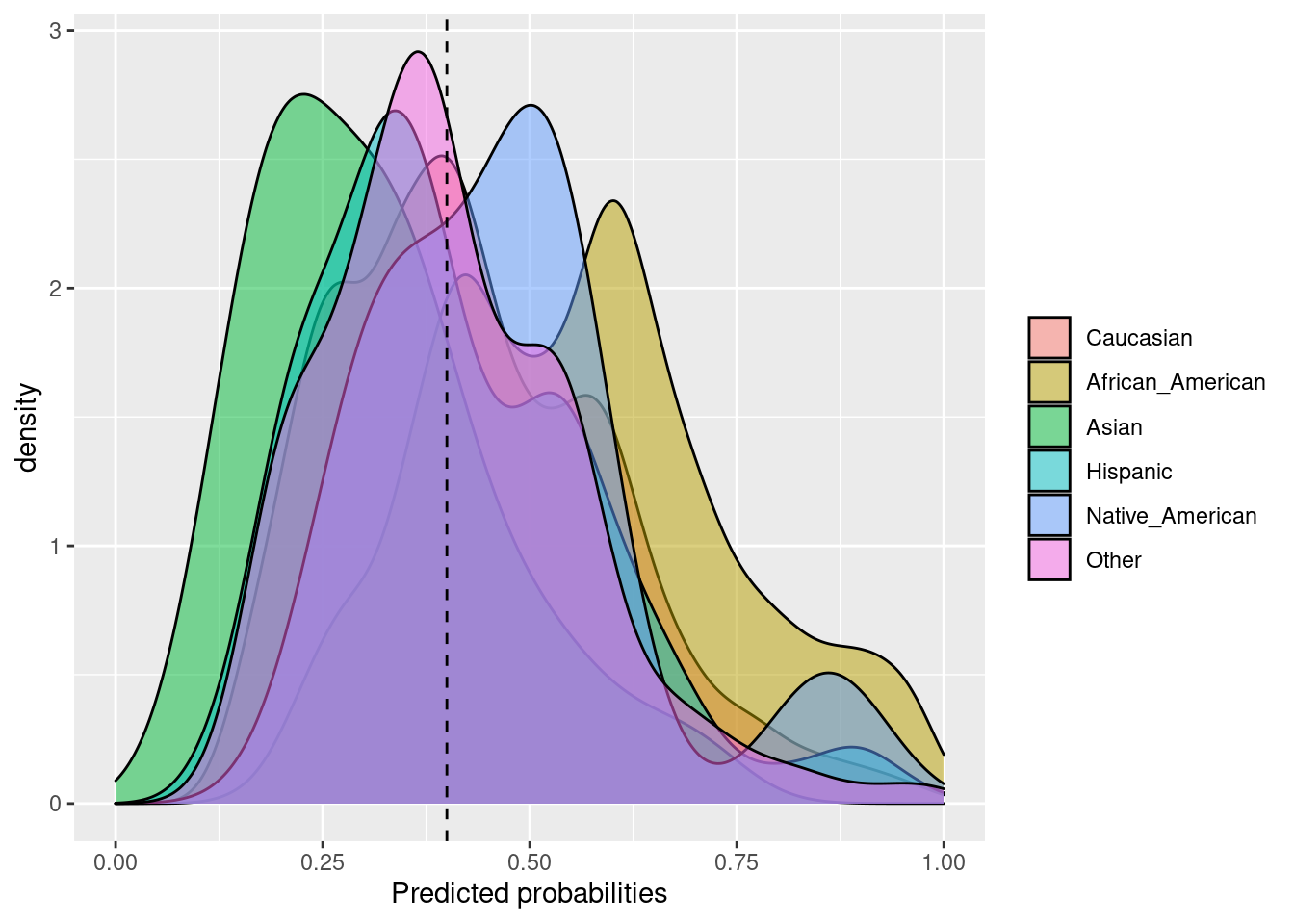
6.2.2 Proportional Parity o Impact Parity o Minimizing Disparate Impact
Cuando nos interesa que cada grupo de la variable “protegida” tenga el mismo impacto. La paridad proporcional se logra si la proporción de predicciones positivas en los subgrupos es cercana entre sí. Similar a la paridad demográfica, esta medida tampoco depende de las etiquetas verdaderas.
Fórmula: \(\frac{TP + FP}{TP + FP + TN + FN}\)
prop_parity(
data = compas,
outcome = 'Two_yr_Recidivism_01',
group = 'ethnicity',
probs = 'probability',
cutoff = 0.4,
base = 'Caucasian'
)## $Metric
## Caucasian African_American Asian Hispanic
## Proportion 0.508797 0.8185827 0.2258065 0.4204322
## Proportional Parity 1.000000 1.6088592 0.4438046 0.8263261
## Group size 2103.000000 3175.0000000 31.0000000 509.0000000
## Native_American Other
## Proportion 0.6363636 0.4431487
## Proportional Parity 1.2507222 0.8709735
## Group size 11.0000000 343.0000000
##
## $Metric_plot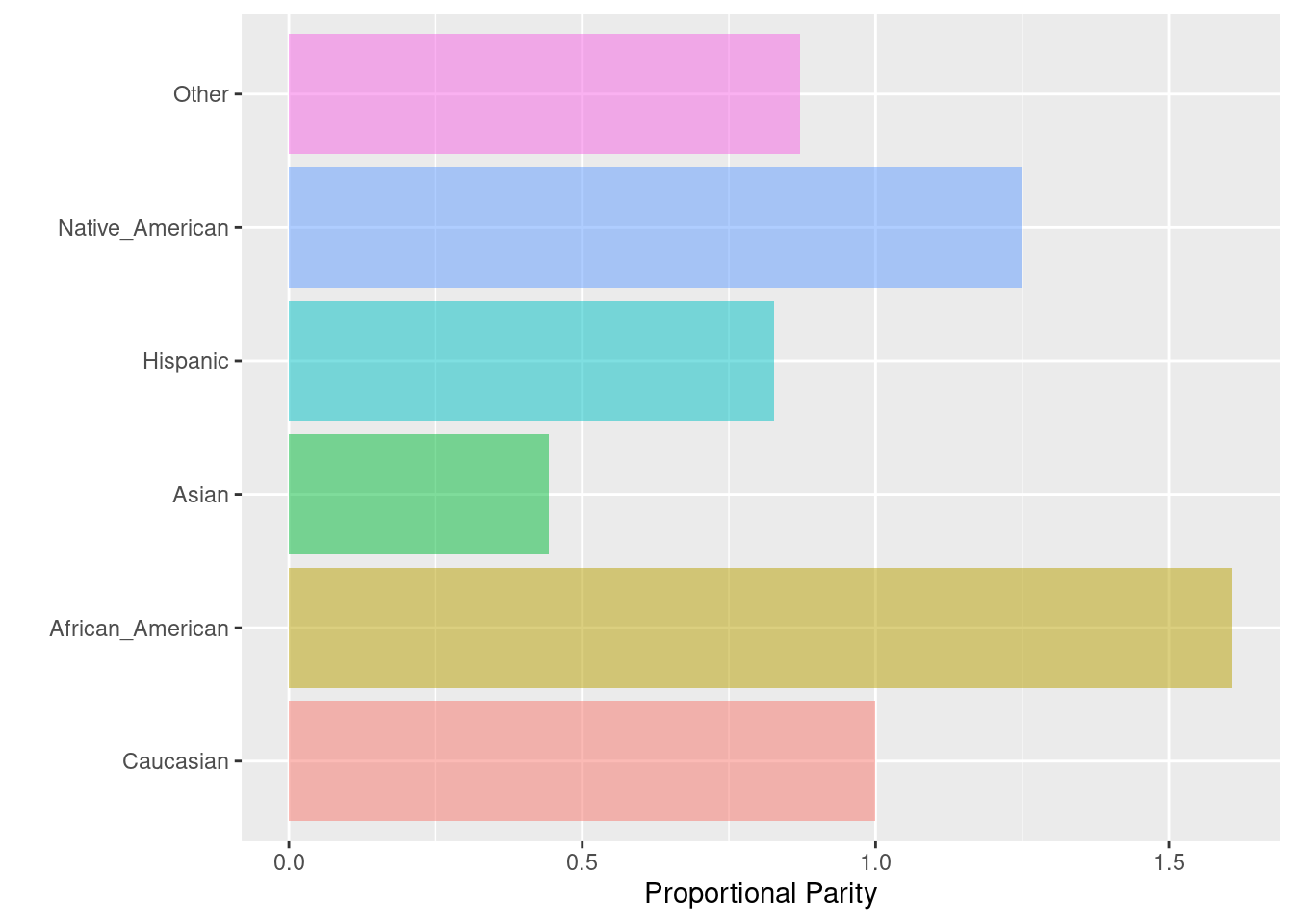
##
## $Probability_plot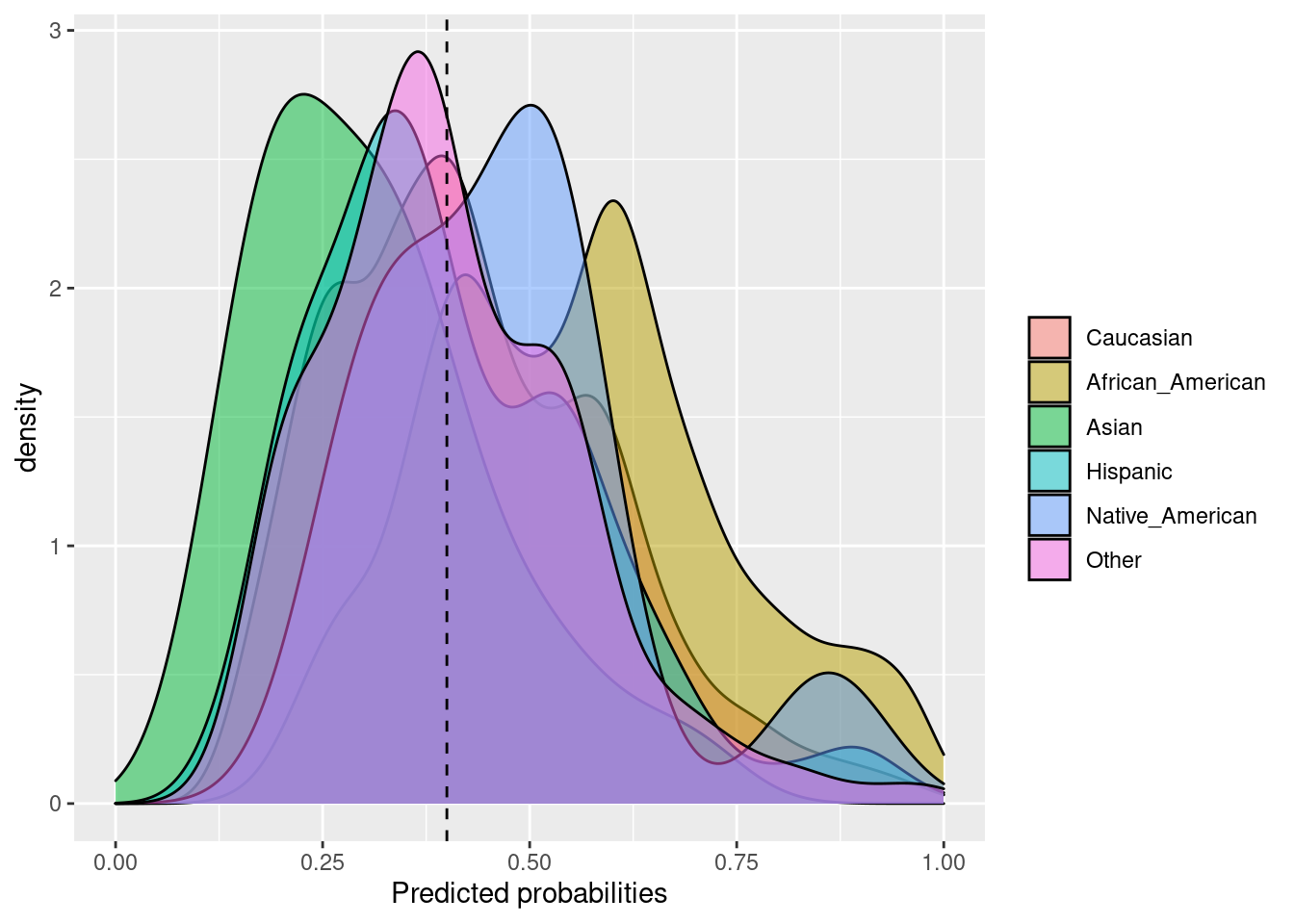
6.2.3 Equalized odds
Las probabilidades igualadas se logran si las sensibilidades en los subgrupos están cerca unas de otras. Las sensibilidades específicas del grupo indican el número de verdaderos positivos dividido por el número total de positivos en ese grupo.
Fórmula: \(\frac{TP}{TP + FN}\)
equal_odds(
data = compas,
outcome = 'Two_yr_Recidivism_01',
group = 'ethnicity',
probs = 'probability',
cutoff = 0.4,
base = 'Caucasian'
)## $Metric
## Caucasian African_American Asian Hispanic
## Sensitivity 0.676399 0.910295 0.2500000 0.5978836
## Equalized odds 1.000000 1.345796 0.3696043 0.8839214
## Group size 2103.000000 3175.000000 31.0000000 509.0000000
## Native_American Other
## Sensitivity 0.6000000 0.6532258
## Equalized odds 0.8870504 0.9657403
## Group size 11.0000000 343.0000000
##
## $Metric_plot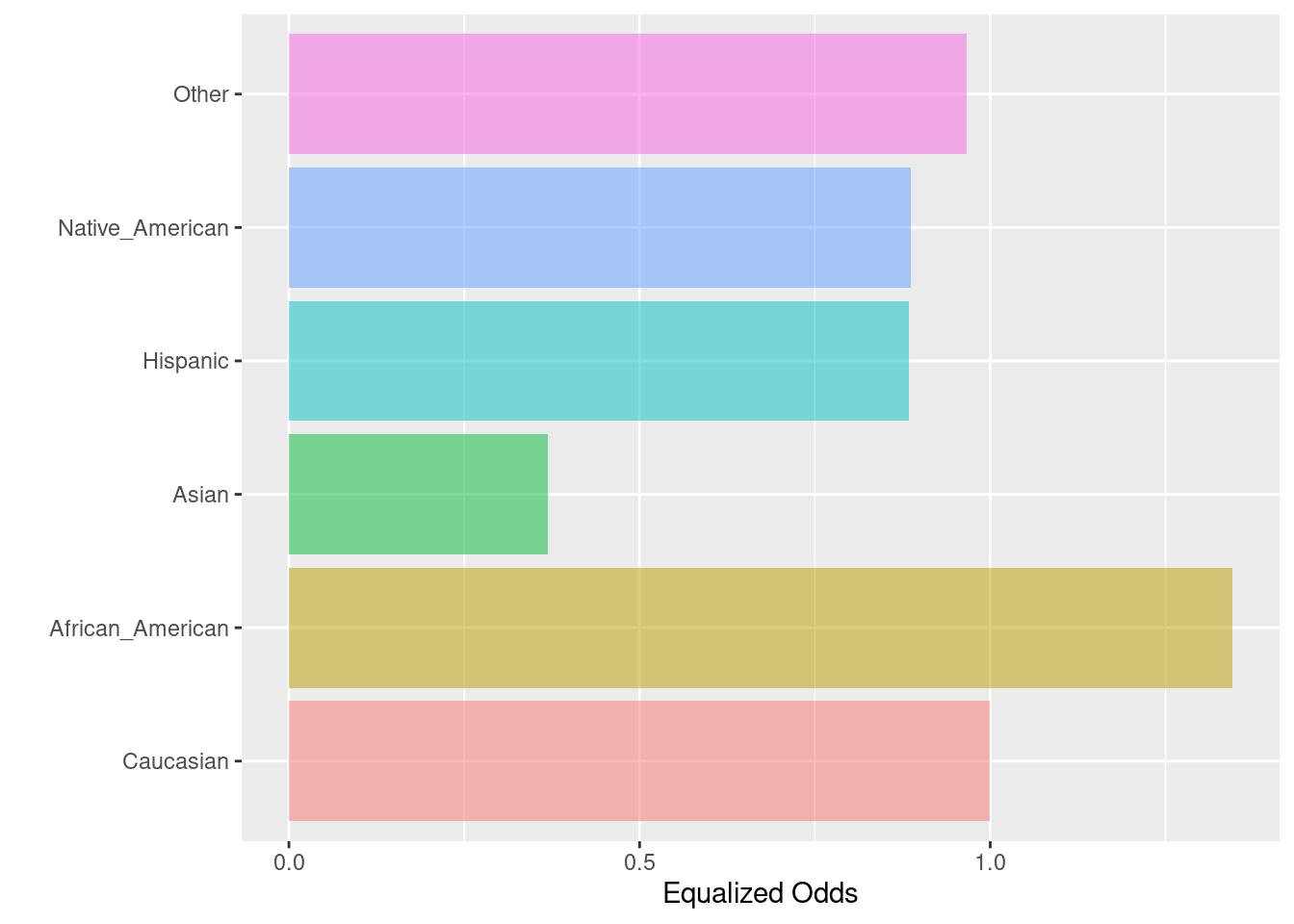
##
## $Probability_plot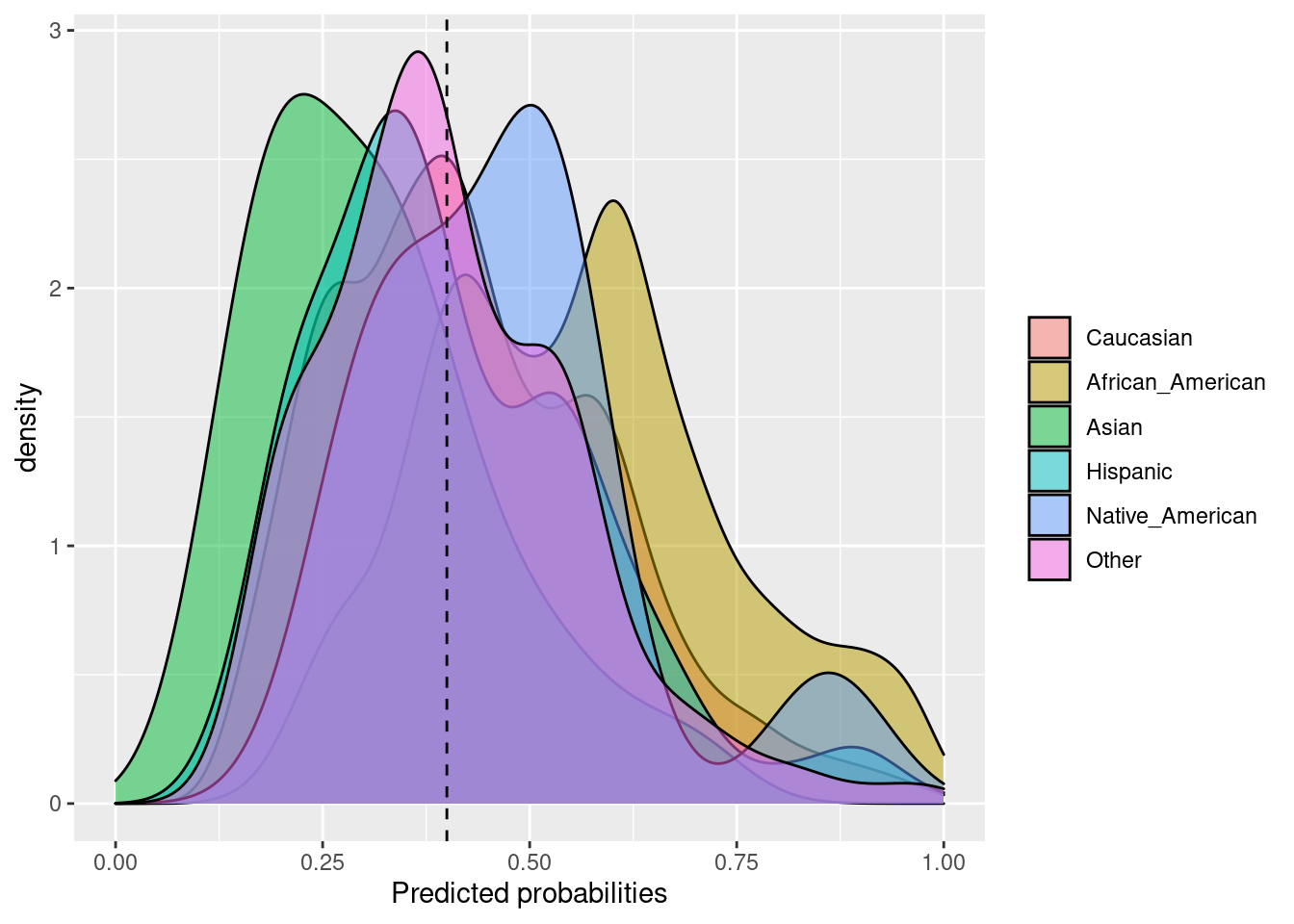
6.2.4 Predictive rate parity
La paridad de tasa predictiva se logra si las precisiones (o valores predictivos positivos) en los subgrupos están cerca unas de otras. La precisión representa el número de verdaderos positivos dividido por el número total de ejemplos predichos positivos dentro de un grupo.
Fórmula: \(\frac{TP}{TP + FP}\)
pred_rate_parity(
data = compas,
outcome = 'Two_yr_Recidivism_01',
group = 'ethnicity',
probs = 'probability',
cutoff = 0.4,
base = 'Caucasian'
)## $Metric
## Caucasian African_American Asian Hispanic
## Precision 0.5196262 0.5817622 0.2857143 0.5280374
## Predictive Rate Parity 1.0000000 1.1195784 0.5498458 1.0161871
## Group size 2103.0000000 3175.0000000 31.0000000 509.0000000
## Native_American Other
## Precision 0.4285714 0.5328947
## Predictive Rate Parity 0.8247688 1.0255348
## Group size 11.0000000 343.0000000
##
## $Metric_plot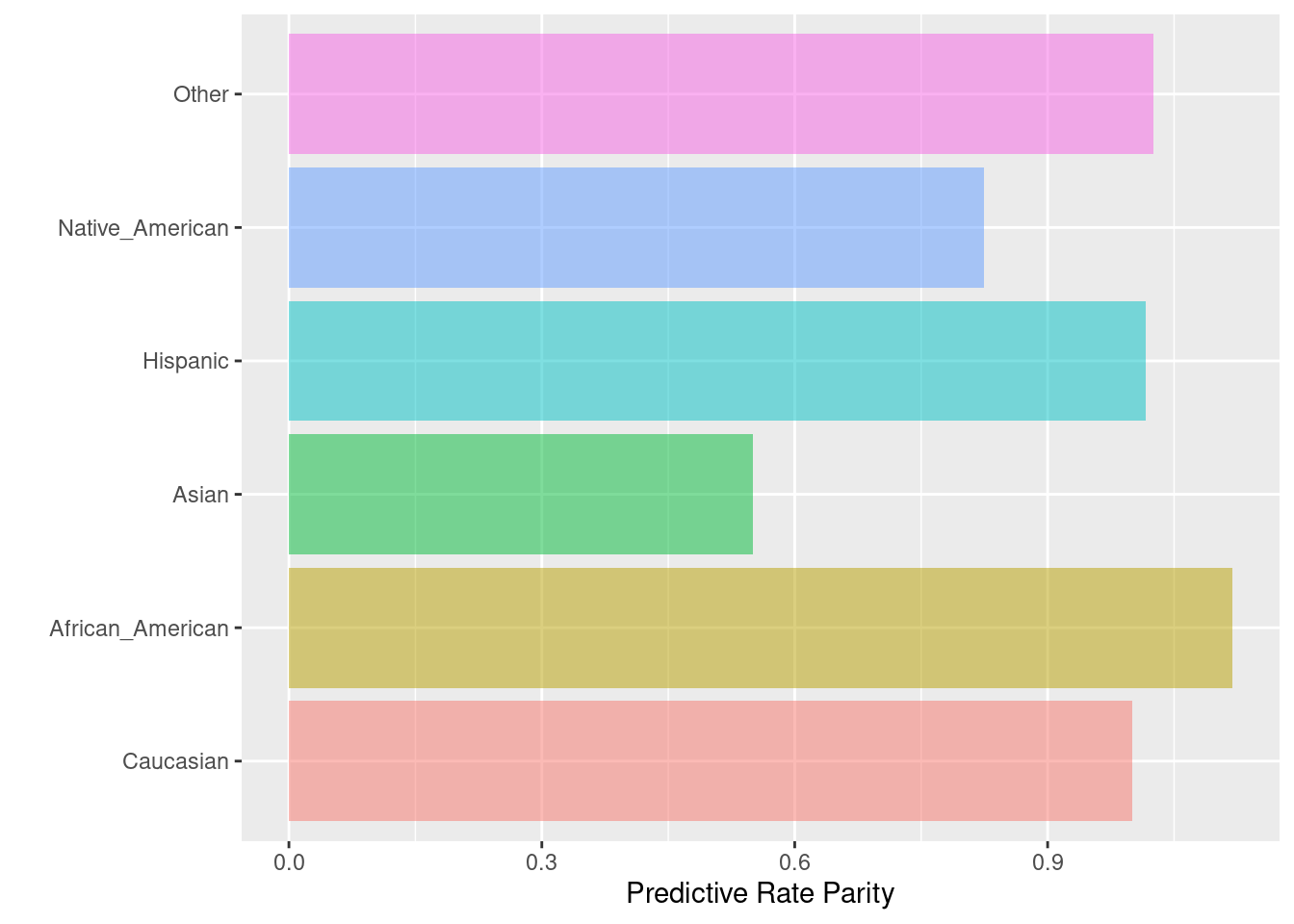
##
## $Probability_plot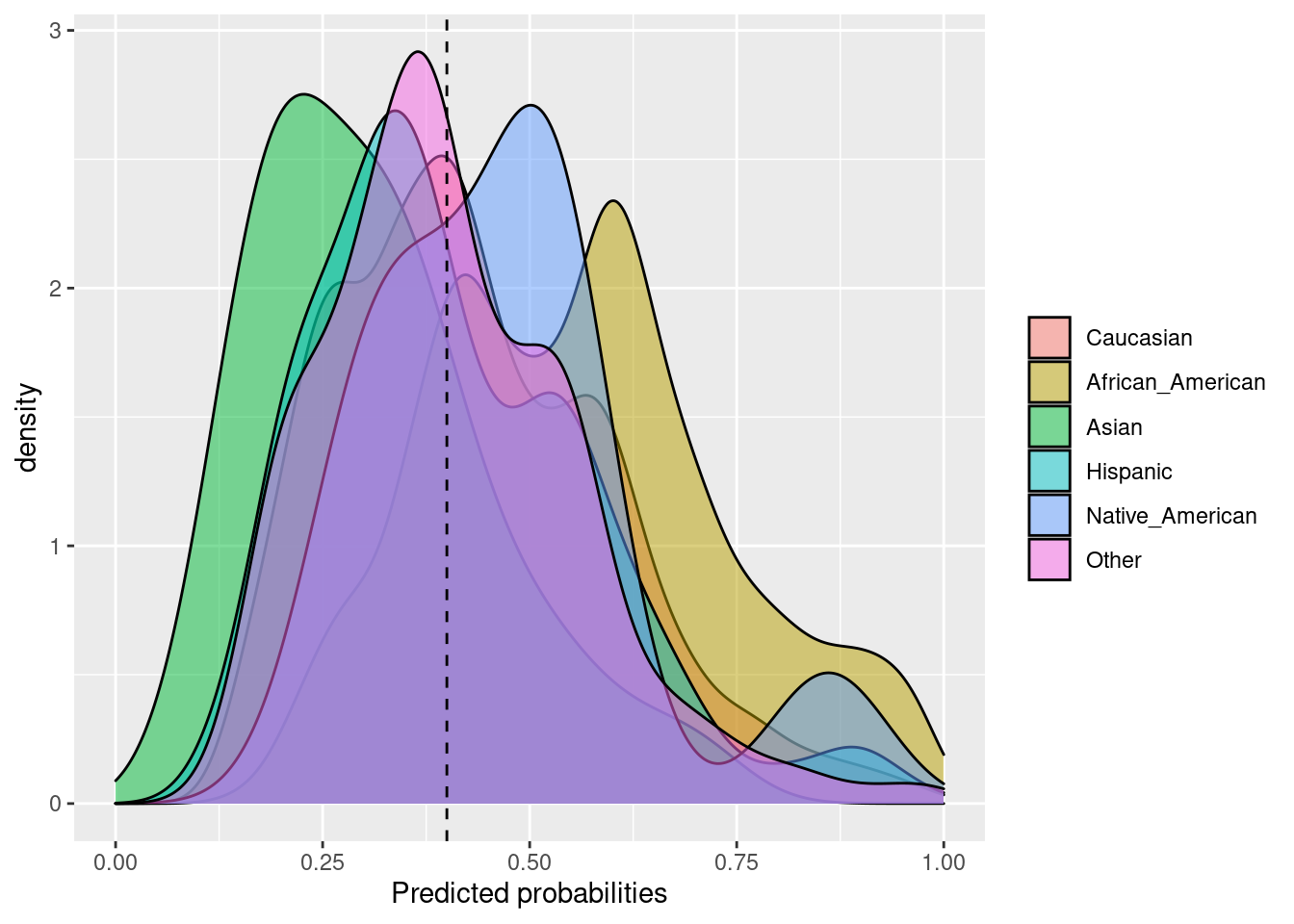
6.2.5 Accuracy parity
La paridad de precisión se logra si las precisiones (todos los ejemplos clasificados con precisión divididos por el número total de ejemplos) en los subgrupos están cerca entre sí.
Fórmula: \(\frac{TP + TN}{TP + FP + TN + FN}\)
acc_parity(
data = compas,
outcome = 'Two_yr_Recidivism_01',
group = 'ethnicity',
probs = 'probability',
cutoff = 0.4,
base = 'Caucasian'
)## $Metric
## Caucasian African_American Asian Hispanic
## Accuracy 0.6291013 0.6107087 0.6451613 0.6522593
## Accuracy Parity 1.0000000 0.9707637 1.0255285 1.0368113
## Group size 2103.0000000 3175.0000000 31.0000000 509.0000000
## Native_American Other
## Accuracy 0.4545455 0.6676385
## Accuracy Parity 0.7225314 1.0612575
## Group size 11.0000000 343.0000000
##
## $Metric_plot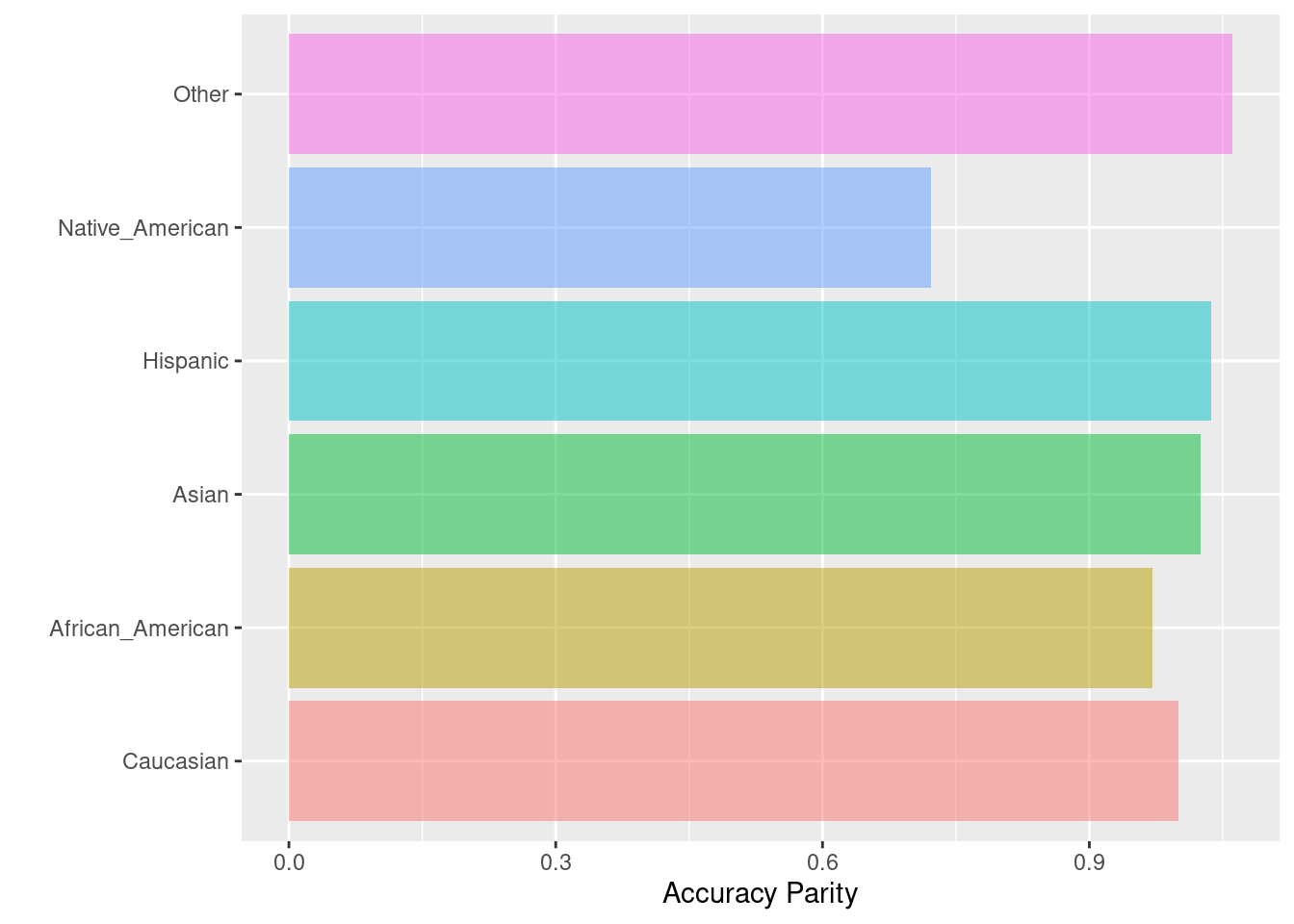
##
## $Probability_plot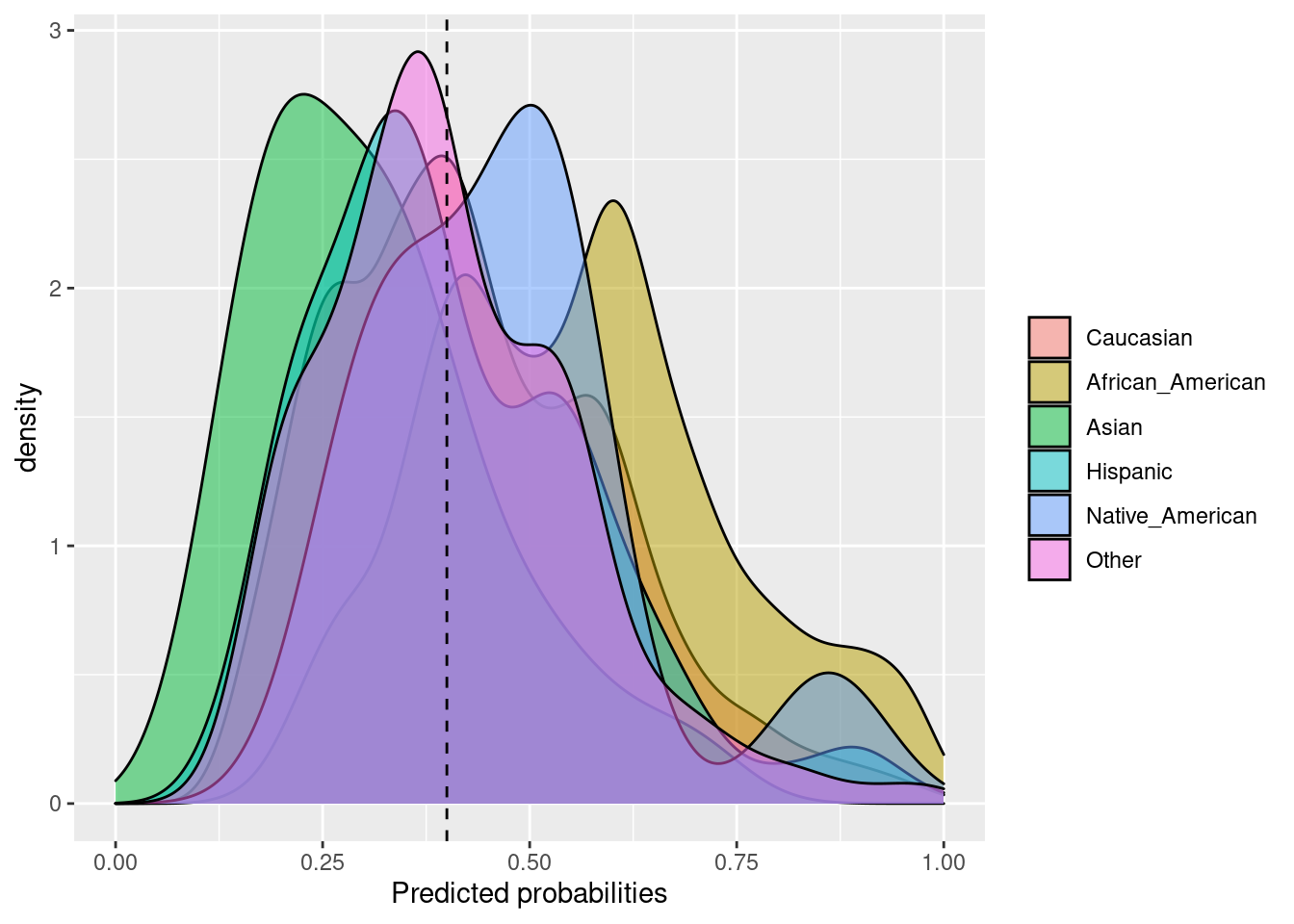
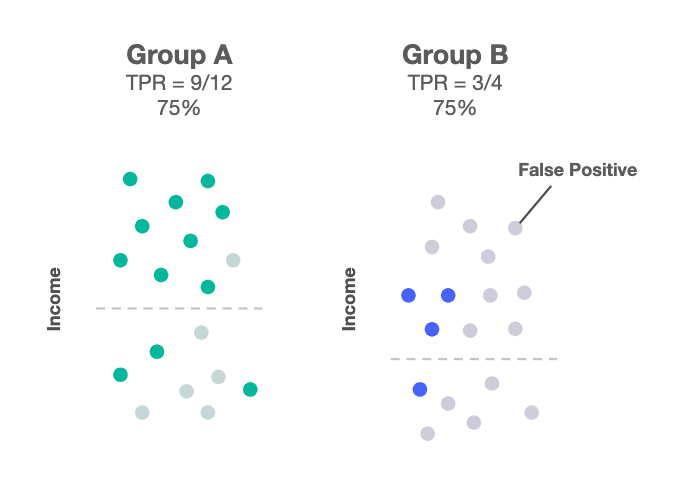
6.2.6 False Negative Parity o Equal Oppportunity
La paridad de tasas de falsos negativos se logra si las tasas de falsos negativos (la relación entre el número de falsos negativos y el número total de positivos) en los subgrupos están cerca entre sí.
Fórmula: \(\frac{FN}{TP + FN}\)
Se utiliza esta métrica cuando:
- El modelo necesita ser muy bueno en detectar la etiqueta positiva.
- No hay -mucho- costo en introducir falsos negativos al sistema -tanto al usuario como a la empresa-. Por ejemplo: Generar FPs en tarjeta de crédito.
- La definición de la variable target no es subjetiva. Por ejemplo: Fraude o No Fraude no es algo subjetivo, buen empleado o no, puede ser muy subjetivo.
Para poder cumplir con tener el mismo porcentaje de TPR en todos los grupos de la variable protegida, incurriremos en agregar más falsos positivos, lo que puede afectar más a ese grupo a largo plazo.
fnr_parity(
data = compas,
outcome = 'Two_yr_Recidivism_01',
group = 'ethnicity',
probs = 'probability',
cutoff = 0.4,
base = 'Caucasian'
)## $Metric
## Caucasian African_American Asian Hispanic Native_American
## FNR 0.323601 0.0897050 0.750000 0.4021164 0.40000
## FNR Parity 1.000000 0.2772087 2.317669 1.2426304 1.23609
## Group size 2103.000000 3175.0000000 31.000000 509.0000000 11.00000
## Other
## FNR 0.3467742
## FNR Parity 1.0716105
## Group size 343.0000000
##
## $Metric_plot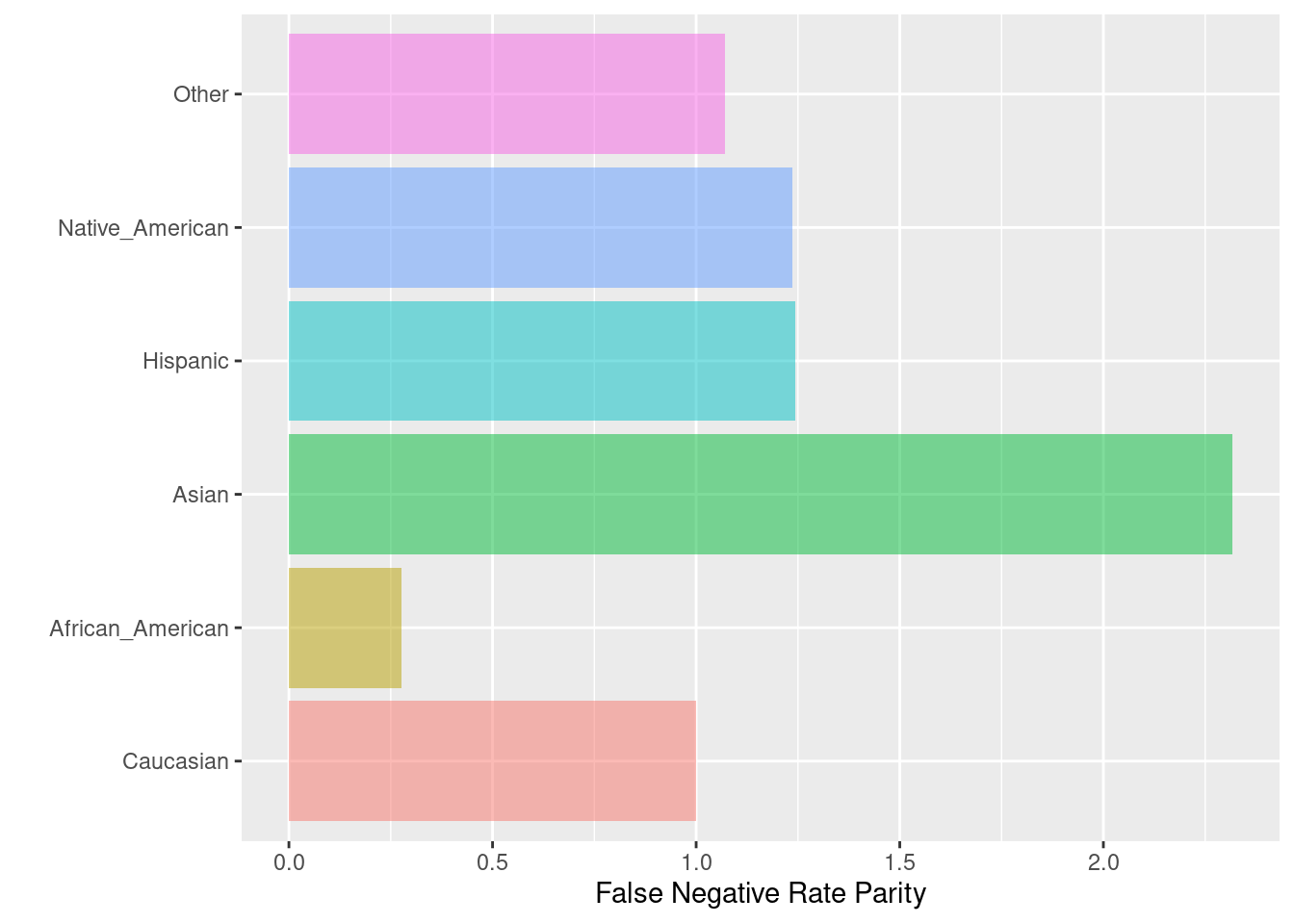
##
## $Probability_plot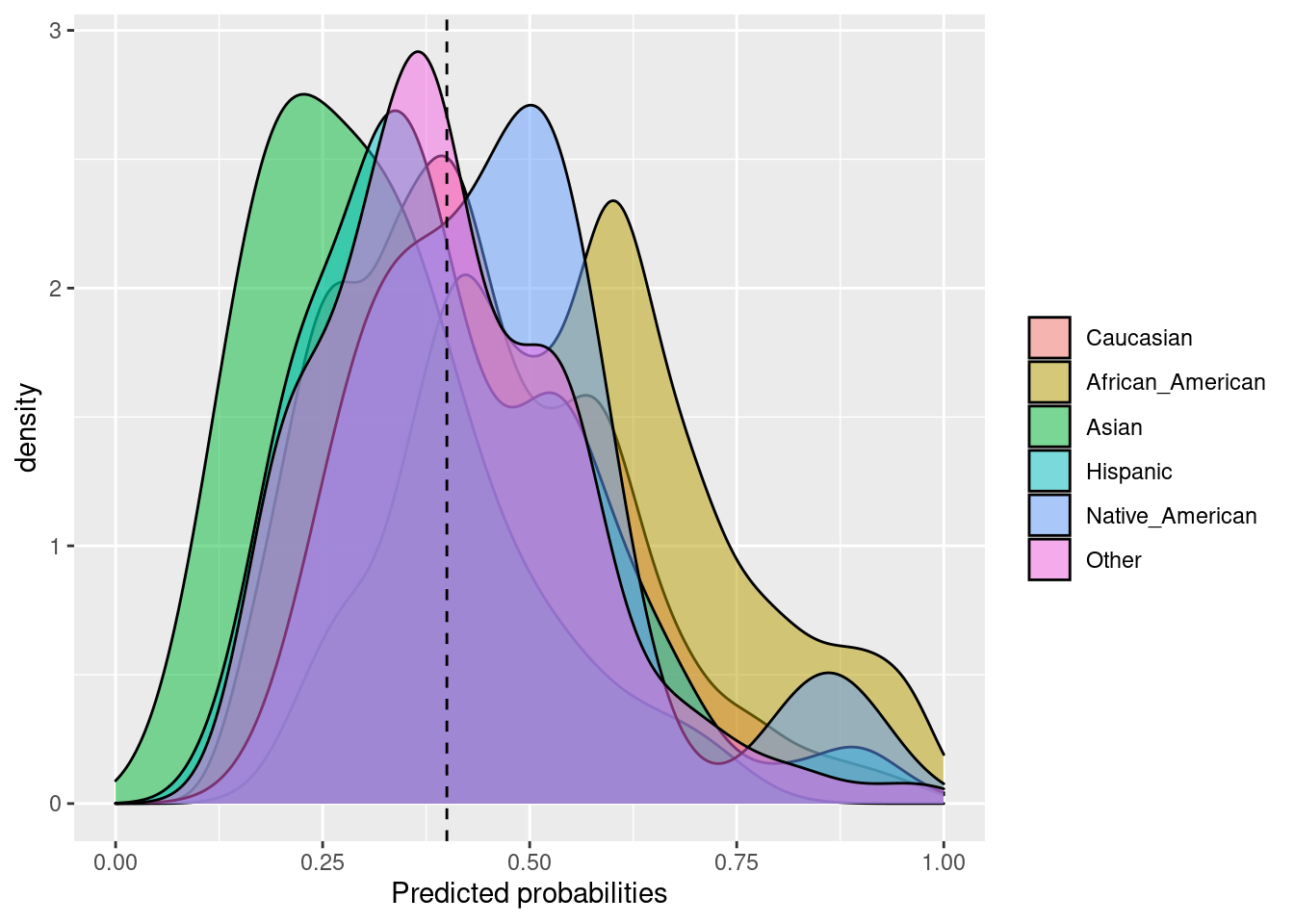
6.2.7 False Positive Parity
Cuando queremos que todos los grupos de la variable protegida tengan la misma tasa de falsos positivos. Es decir, nos equivocamos en las mismas proporciones para etiquetas positivas que eran negativas.
Fórmula: \(\frac{FP}{TN + FP}\)
fpr_parity(
data = compas,
outcome = 'Two_yr_Recidivism_01',
group = 'ethnicity',
probs = 'probability',
cutoff = 0.4,
base = 'Caucasian'
)## $Metric
## Caucasian African_American Asian Hispanic Native_American
## FPR 0.401249 0.7179657 0.2173913 0.3156250 0.6666667
## FPR Parity 1.000000 1.7893269 0.5417865 0.7866063 1.6614786
## Group size 2103.000000 3175.0000000 31.0000000 509.0000000 11.0000000
## Other
## FPR 0.3242009
## FPR Parity 0.8079793
## Group size 343.0000000
##
## $Metric_plot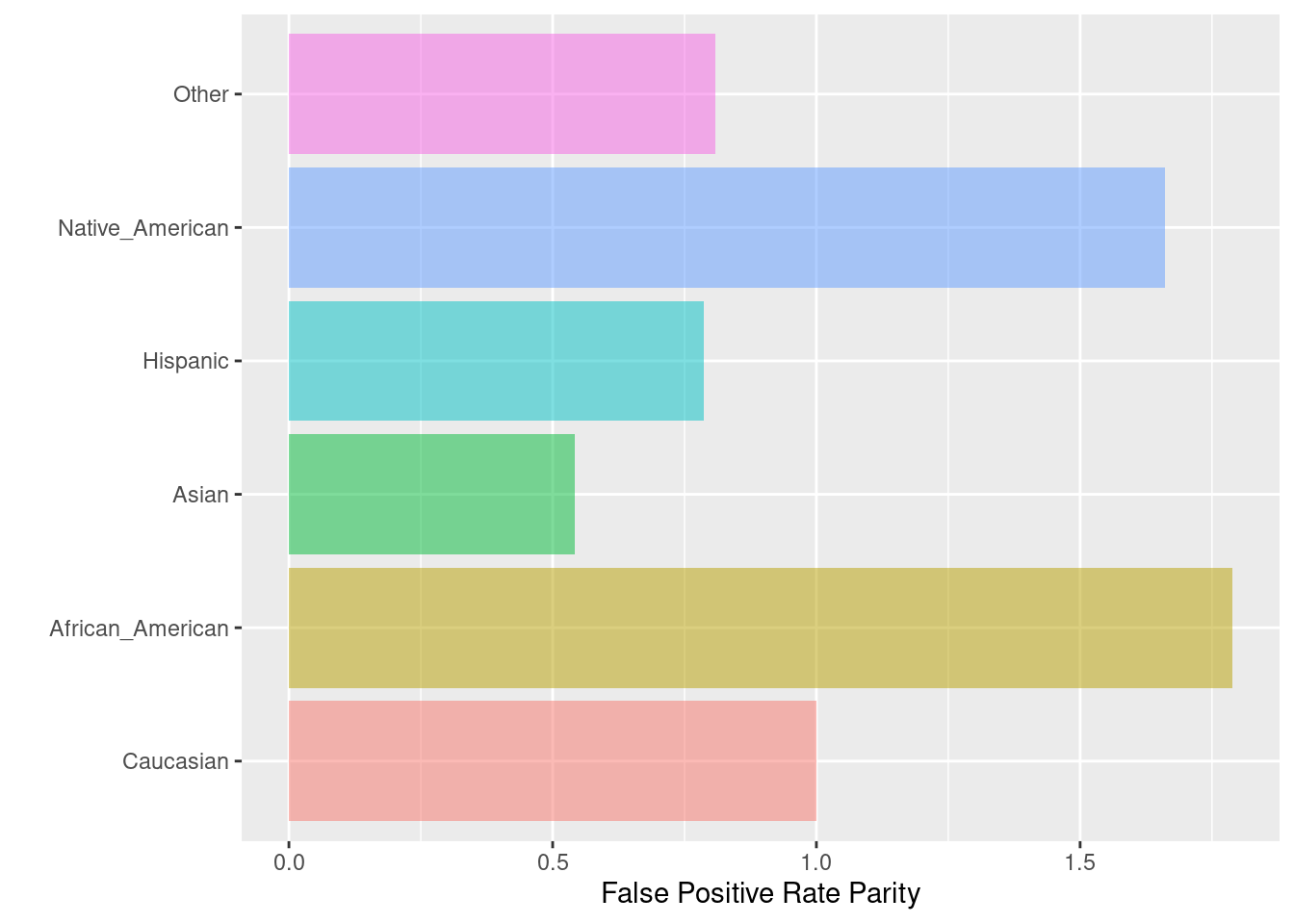
##
## $Probability_plot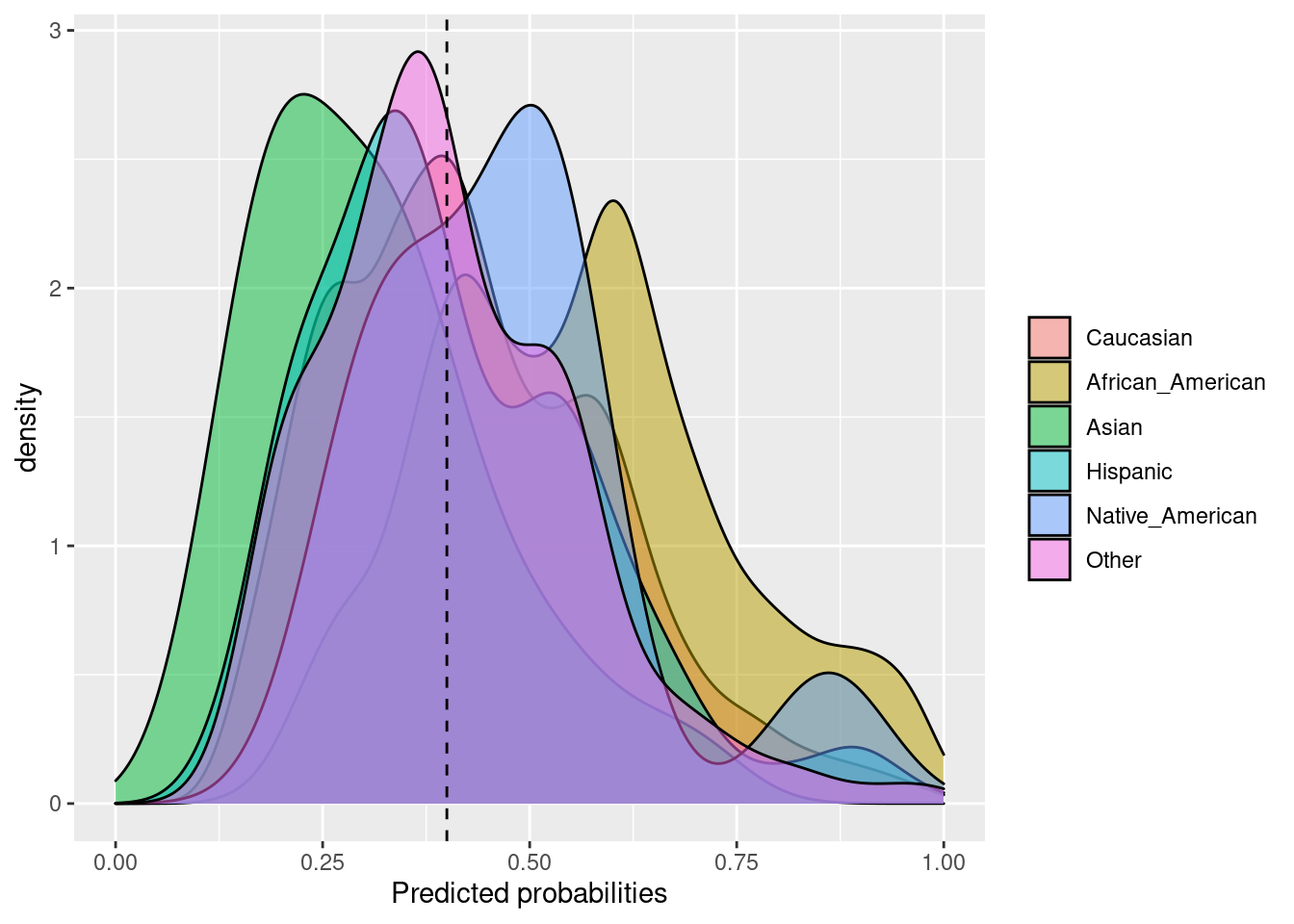
6.2.8 Negative predictive value parity
La paridad de valor predictivo negativo se logra si los valores predictivos negativos en los subgrupos están cerca unos de otros. El valor predictivo negativo se calcula como una relación entre el número de negativos verdaderos y el número total de negativos previstos. Esta función puede considerarse la “inversa” de la paridad de tasa predictiva (predictive rate parity).
Fórmula: \(\frac{TN}{TN + FN}\)
npv_parity(
data = compas,
outcome = 'Two_yr_Recidivism_01',
group = 'ethnicity',
probs = 'probability',
cutoff = 0.4,
base = 'Caucasian'
)## $Metric
## Caucasian African_American Asian Hispanic Native_American
## NPV 0.7424976 0.7413194 0.750000 0.7423729 0.5000000
## NPV Parity 1.0000000 0.9984133 1.010104 0.9998321 0.6734029
## Group size 2103.0000000 3175.0000000 31.000000 509.0000000 11.0000000
## Other
## NPV 0.7748691
## NPV Parity 1.0435982
## Group size 343.0000000
##
## $Metric_plot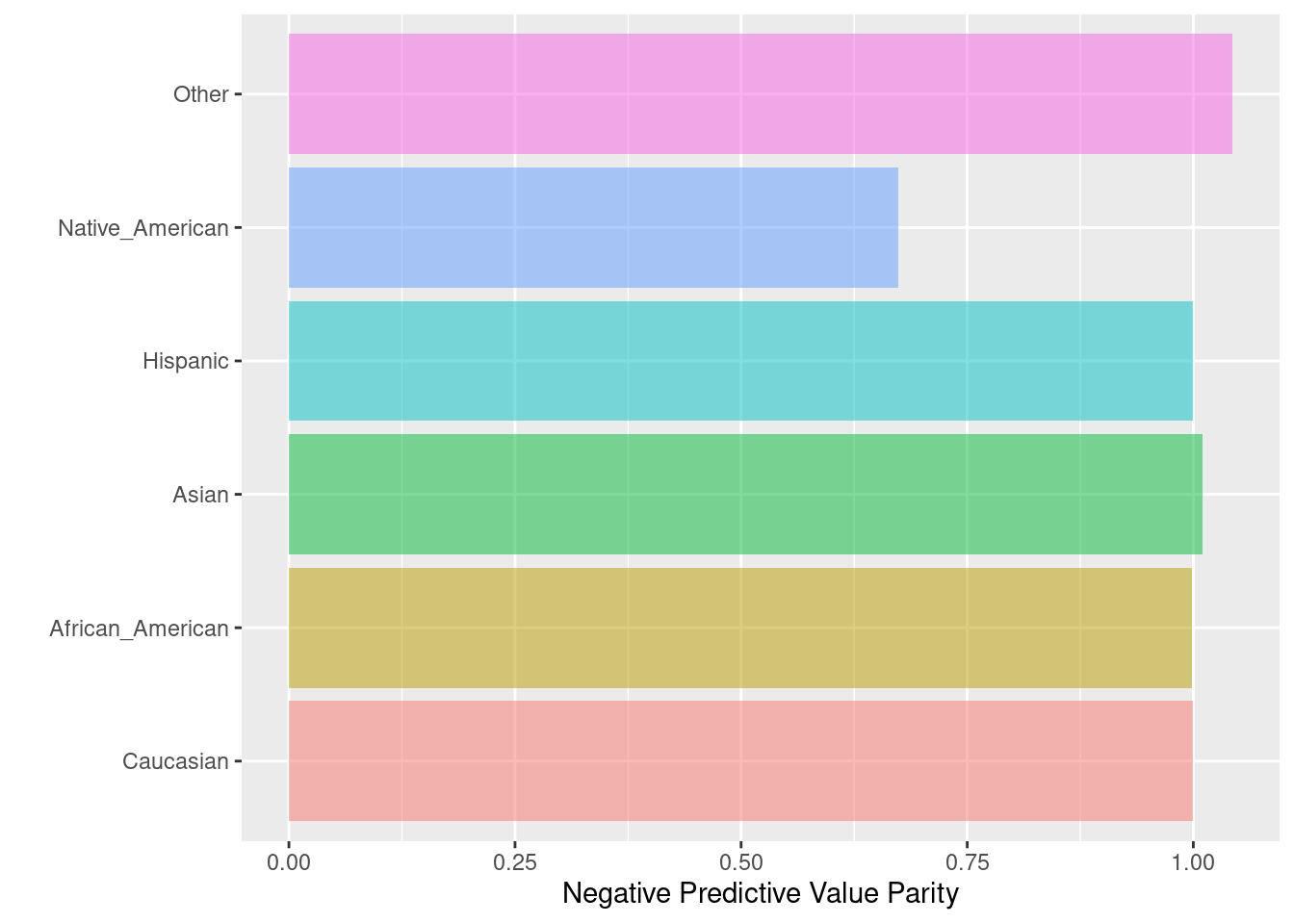
##
## $Probability_plot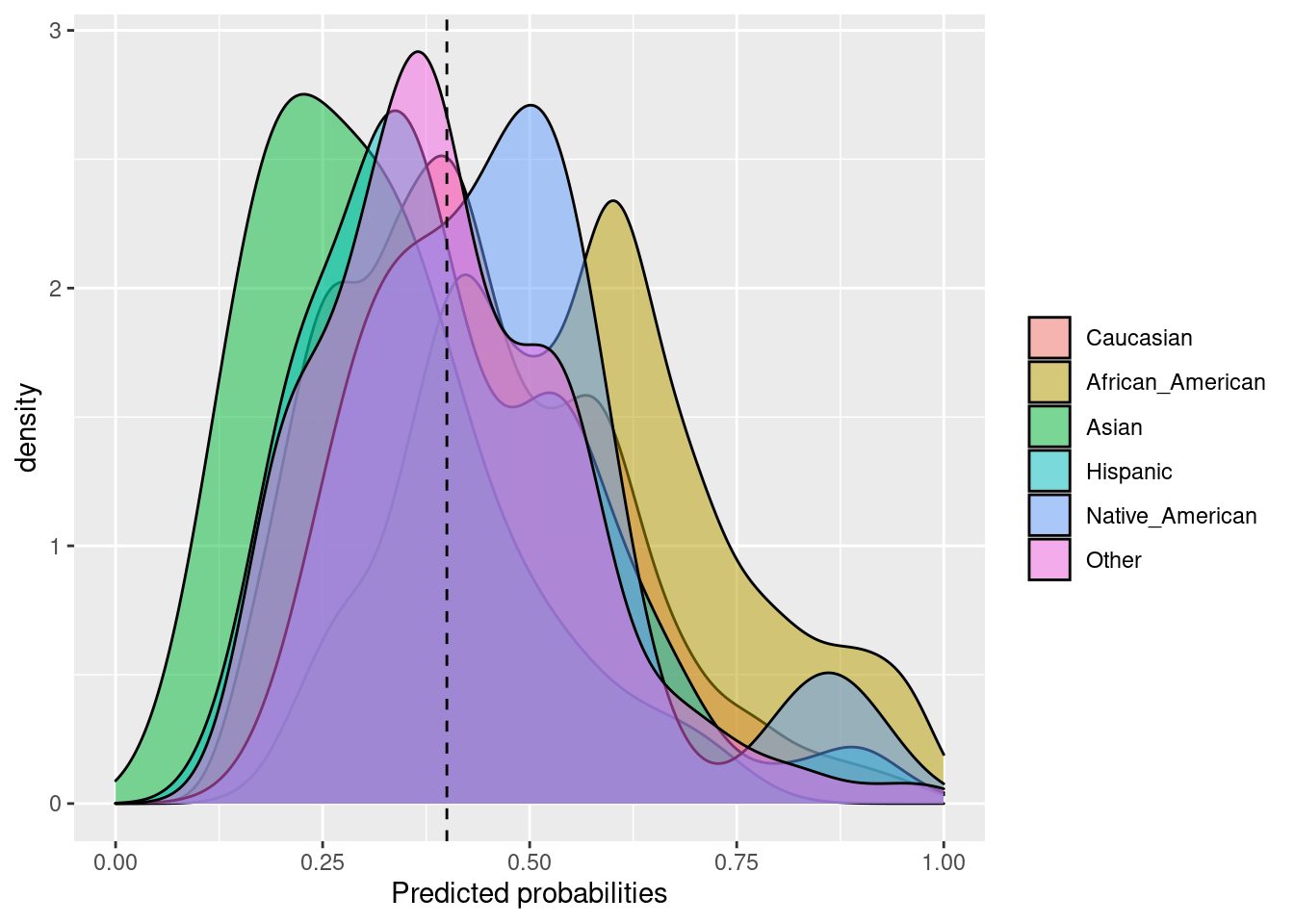
6.2.9 Specificity parity
La paridad de especificidad se logra si las especificidades (la relación entre el número de verdaderos negativos y el número total de negativos) en los subgrupos están próximas entre sí. Esta función puede considerarse la “inversa” de las probabilidades igualadas (equalized odds).
Fórmula: \(\frac{TN}{TN + FP}\)
spec_parity(
data = compas,
outcome = 'Two_yr_Recidivism_01',
group = 'ethnicity',
probs = 'probability',
cutoff = 0.4,
base = 'Caucasian'
)## $Metric
## Caucasian African_American Asian Hispanic
## Specificity 0.598751 0.2820343 0.7826087 0.684375
## Specificity Parity 1.000000 0.4710378 1.3070688 1.143004
## Group size 2103.000000 3175.0000000 31.0000000 509.000000
## Native_American Other
## Specificity 0.3333333 0.6757991
## Specificity Parity 0.5567145 1.1286814
## Group size 11.0000000 343.0000000
##
## $Metric_plot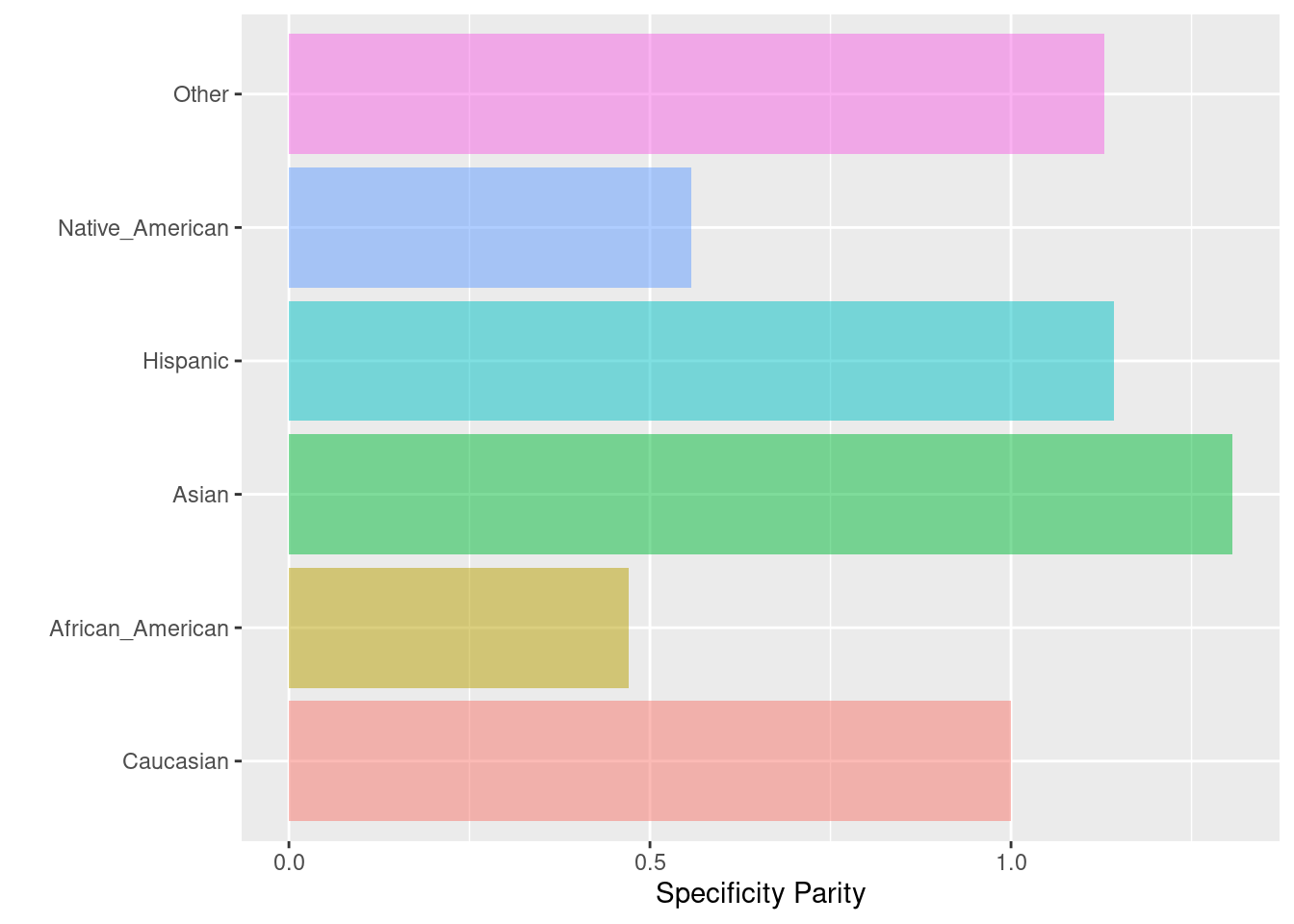
##
## $Probability_plot