Capítulo 4 Bagging & Boosting
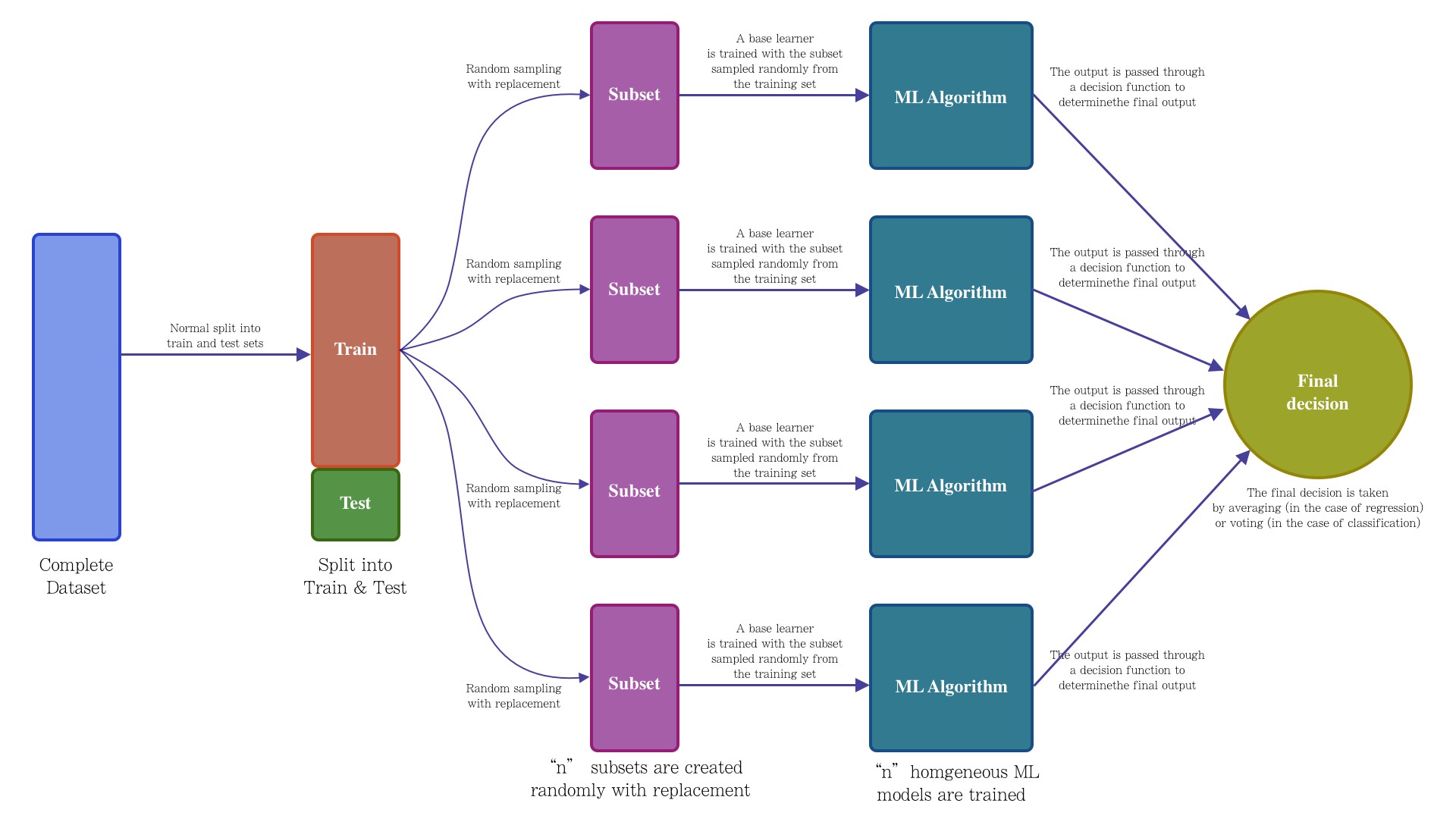
El bagging o agregación bootstrap, es un método de aprendizaje por conjuntos que se usa comúnmente para reducir la varianza dentro de un conjunto de datos ruidoso. En este método, se selecciona una muestra aleatoria de datos en un conjunto de entrenamiento con reemplazo, lo que significa que los puntos de datos individuales se pueden elegir más de una vez. Después de generar varias muestras de datos, estos modelos se entrenan de forma independiente y, según el tipo de tarea (regresión o clasificación), el promedio o la mayoría de esas predicciones producen una estimación más precisa.
Nota: El algoritmo de bosque aleatorio se considera una extensión del método de bagging, utilizando tanto bagging como la aleatoriedad de características para crear un bosque no correlacionado de árboles de decisión.
4.1 Aprendizaje conjunto
El aprendizaje conjunto da crédito a la idea de la “sabiduría de las multitudes,” lo que sugiere que la toma de decisiones de un grupo más grande de individuos (modelos) suele ser mejor que la de un individuo.
El aprendizaje en conjunto es un grupo (o conjunto) de individuos o modelos, que trabajan colectivamente para lograr una mejor predicción final. Un solo modelo, también conocido como aprendiz básico puede no funcionar bien individualmente debido a una gran variación o un alto sesgo, sin embargo, cuando se agregan individuos débiles, pueden formar un individuo fuerte, ya que su combinación reduce el sesgo o la varianza, lo que produce un mejor rendimiento del modelo.

Los métodos de conjunto se ilustran con frecuencia utilizando árboles de decisión, ya que este algoritmo puede ser propenso a sobreajustar (alta varianza y bajo sesgo) y también puede prestarse a desajuste (baja varianza y alto sesgo) cuando es muy pequeño, como un árbol de decisión con un nivel.
Nota: Cuando un algoritmo se adapta o no se adapta a su conjunto de entrenamiento, no se puede generalizar bien a nuevos conjuntos de datos, por lo que se utilizan métodos de conjunto para contrarrestar este comportamiento y permitir la generalización del modelo a nuevos conjuntos de datos.
4.2 Bagging vs. boosting
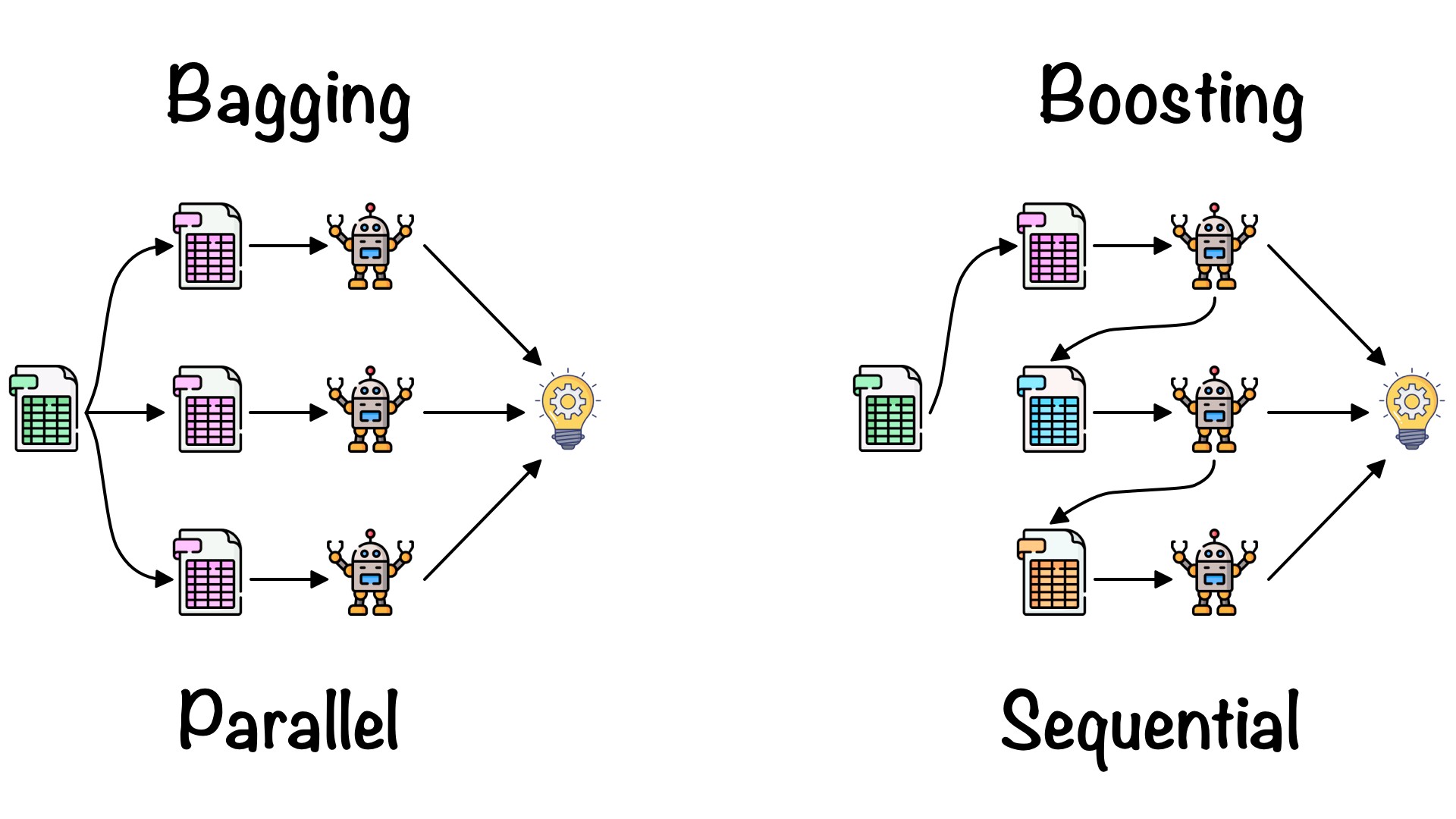
Bagging y el boosting (refuerzo o impulso) son dos tipos principales de métodos de aprendizaje por conjuntos. La principal diferencia entre estos métodos de aprendizaje es la forma en que se capacitan.
En bagging, los modelos se entrenan en paralelo, pero en el boosting, aprenden secuencialmente. Esto significa que se construyen una serie de modelos y con cada nueva iteración del modelo, se incrementan los pesos de los datos clasificados erróneamente en el modelo anterior. Esta redistribución de pesos ayuda al algoritmo a identificar los parámetros en los que necesita enfocarse para mejorar su desempeño.
Un ejemplo de modelo secuencial es: Adaboost y significa “algoritmo de boosting adaptativo,” es uno de los algoritmos de boosting más populares, ya que fue uno de los primeros de su tipo. Otros tipos de algoritmos de booting incluyen XGBoost, GradientBoost y BrownBoost.
Otra diferencia en la que difieren bagging y boosting son los escenarios en los que se utilizan. Por ejemplo, los métodos de bagging se utilizan típicamente en modelos débiles que exhiben alta varianza y bajo sesgo, mientras que los métodos de boosting se aprovechan cuando se observa baja varianza y alto sesgo.
¡¡ RECORDAR !!
Bagging realiza replicaciones bootstrap y ajusta un árbol a cada muestra de manera independiente, mientras que boosting ajusta un árbol a una versión modificada del conjunto original de datos, la cual se modifica en cada iteración de entrenamiento.
4.2.1 Error Out-Of-Bag
Este error es conocido como “OOB.” Se trata de un enfoque distinto a KFCV en donde el error predictivo es calculado a través de los elementos que no fueron seleccionados en la muestra bootstrap. Recordemos que en las muestras bootstrap algunos elementos son seleccionados más de una vez, mientras que otros no aparecen en la muestra. Empíricamente, en cada replicación bootstrap se observan 2/3 partes de la muestra y el resto queda “fuera de la bolsa” (OOB) de entrenamiento.
Si B es el número de replicaciones bootstrap, entonces cada observación i recibe cerca de B/3 predicciones, las cuales son usadas para estimar el error predictivo. Para obtener una única predicción en cada observación, las B/3 predicciones son promediadas.
4.3 Algoritmo Bagging
Bootstrapping: Bagging aprovecha una técnica de muestreo de bootstrapping para crear muestras diversas. Este método de remuestreo genera diferentes subconjuntos a partir del conjunto de datos de entrenamiento original seleccionando puntos de datos al azar y con reemplazo. Esto significa que cada vez que selecciona un punto del conjunto de entrenamiento, puede seleccionar la misma instancia varias veces. Como resultado, un valor se repite dos veces (o más) en una muestra y algunos no aparecen.
Entrenamiento paralelo: estos ejemplos de bootstrap se entrenan de forma independiente y en paralelo entre sí utilizando modelos débiles o básicos.
Agregación: Finalmente, dependiendo de la tarea (regresión o clasificación), se toma un promedio o la mayoría de las predicciones para calcular una estimación más precisa. En el caso de la regresión, se toma un promedio de todos los resultados predichos por los clasificadores individuales; esto se conoce como votación suave.
Para problemas de clasificación, se acepta la clase con mayor mayoría de votos; esto se conoce como votación en firme o votación por mayoría.
4.3.1 Ventajas y desventajas de bagging
Hay una serie de ventajas y desventajas clave que presenta el método de bagging cuando se usa para problemas de clasificación o regresión.
Ventajas
Facilidad de implementación: las bibliotecas de R como tidymodels facilitan la combinación de las predicciones de los aprendices o estimadores base para mejorar el rendimiento del modelo.
Reducción de varianza: bagging puede reducir la varianza dentro de un algoritmo de aprendizaje. Esto es particularmente útil con datos de alta dimensión, donde los valores faltantes pueden conducir a una mayor varianza, lo que los hace más propensos a sobreajustarse y evitar la generalización precisa a nuevos conjuntos de datos.
Desventajas
Pérdida de interpretabilidad: es difícil obtener información empresarial muy precisa a través del bagging debido al promedio involucrado en las predicciones. Si bien el resultado es más preciso que cualquier punto de datos individual, un conjunto de datos más exacto o completo también podría producir más precisión dentro de un solo modelo de clasificación o regresión.
Computacionalmente costoso: bagging se ralentiza y se vuelve más intensivo a medida que aumenta el número de iteraciones. Por lo tanto, no es adecuado para aplicaciones en tiempo real. Los sistemas agrupados o una gran cantidad de núcleos de procesamiento son ideales para crear rápidamente conjuntos en bolsas en conjuntos de prueba grandes.
Menos flexible: como técnica, bagging funciona particularmente bien con algoritmos que son menos estables. Uno que sea más estable o esté sujeto a grandes cantidades de sesgo no proporciona tanto beneficio ya que hay menos variación dentro del conjunto de datos del modelo.
4.3.2 Aplicaciónes de Bagging
La técnica de bagging se utiliza en una gran cantidad de industrias, proporcionando información sobre el valor del mundo real y perspectivas interesantes. Los casos de uso clave incluyen:
TI: bagging también puede mejorar la precisión y exactitud en los sistemas de TI, como los sistemas de detección de intrusiones en la red.
Medio ambiente: los métodos de conjunto, como bagging, se han aplicado en el campo de la teledetección (técnica de adquisición de datos de la superficie terrestre desde sensores instalados en plataformas espaciales).
Finanzas: bagging también se ha aprovechado con modelos de aprendizaje profundo en la industria financiera, automatizando tareas críticas, incluida la detección de fraudes, evaluaciones de riesgo crediticio y problemas de precios de opciones.
4.3.3 Implementación en R
library(tidymodels)
library(rsample)
data(ames)
set.seed(20211212)
ames_boot <- bootstraps(ames, times = 500, apparent = TRUE)
# Se crean muestras bootstrap# Se entrena un modelo para cada muestra.
ames_models <- ames_boot %>%
mutate(
model = map(
splits, ~ lm(Sale_Price ~ 0 + log10(Gr_Liv_Area) + Full_Bath + Year_Built,
data = .)),
coef_info = map(model, tidy)
)
ames_coefs <- ames_models %>% unnest(coef_info)
ames_coefs## # A tibble: 1,503 × 8
## splits id model term estimate std.error statistic p.value
## <list> <chr> <lis> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 <split [2930/1106]> Bootst… <lm> log1… 206873. 9544. 21.7 9.71e-97
## 2 <split [2930/1106]> Bootst… <lm> Full… 49994. 2434. 20.5 1.14e-87
## 3 <split [2930/1106]> Bootst… <lm> Year… -278. 14.4 -19.4 9.39e-79
## 4 <split [2930/1082]> Bootst… <lm> log1… 208068. 9997. 20.8 7.66e-90
## 5 <split [2930/1082]> Bootst… <lm> Full… 49639. 2541. 19.5 5.35e-80
## 6 <split [2930/1082]> Bootst… <lm> Year… -281. 15.1 -18.6 2.40e-73
## 7 <split [2930/1055]> Bootst… <lm> log1… 212558. 9685. 21.9 5.78e-99
## 8 <split [2930/1055]> Bootst… <lm> Full… 48700. 2454. 19.8 2.32e-82
## 9 <split [2930/1055]> Bootst… <lm> Year… -287. 14.6 -19.7 3.45e-81
## 10 <split [2930/1074]> Bootst… <lm> log1… 205522. 9420. 21.8 6.60e-98
## # … with 1,493 more rows# Evaluación de resultados
ames_coefs %>%
ggplot(aes(estimate)) +
geom_histogram(fill = "light blue")+
facet_wrap(~term, scales = "free_x")+
scale_x_continuous(labels = comma)+
theme_minimal()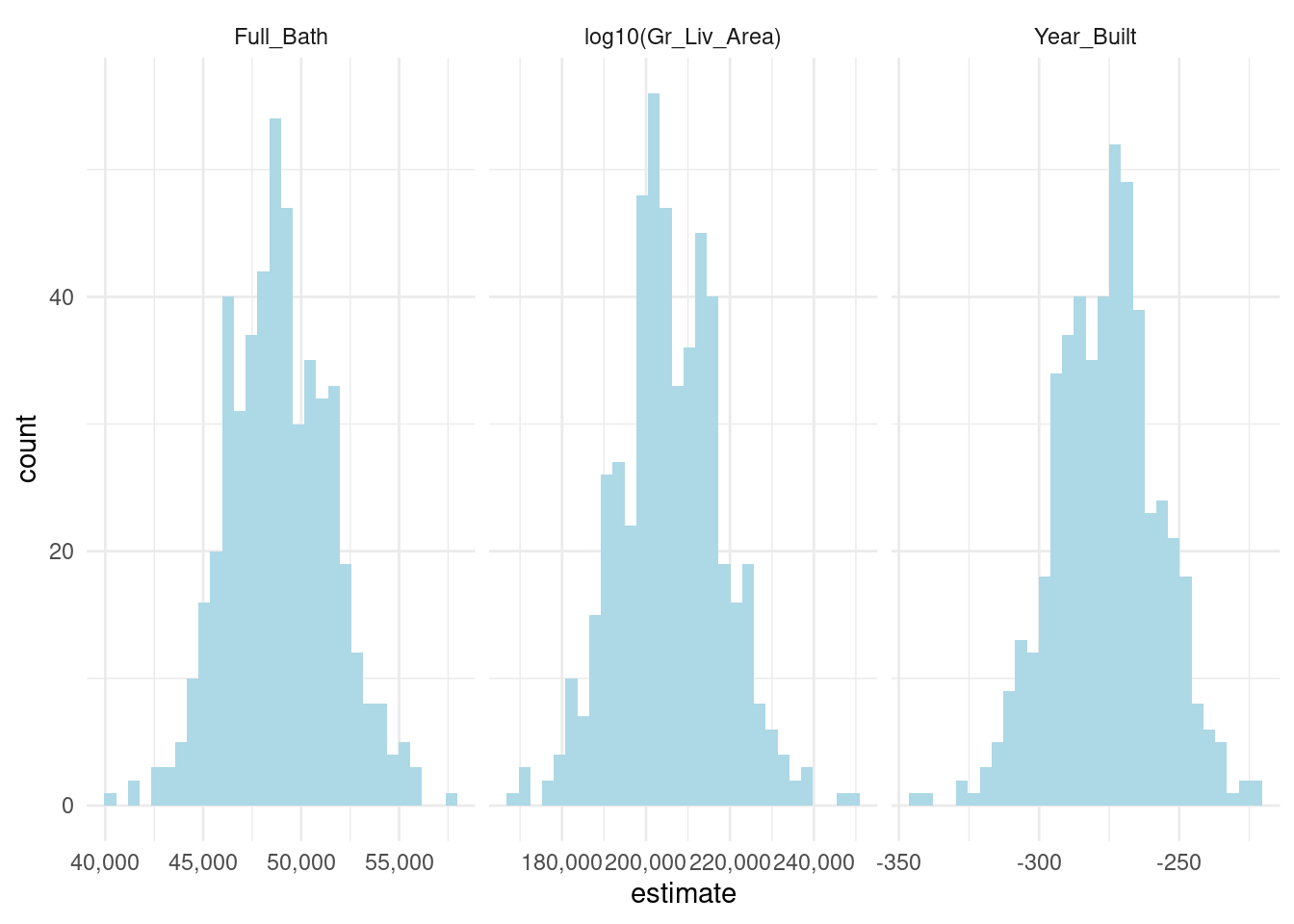
4.4 Algoritmo Boosting
Tradicionalmente, la construcción de una aplicación de aprendizaje automático consistía en tomar un solo estimador, es decir:
- Un regresor logístico
- Un árbol de decisión
- Una máquina de vectores de soporte
- Una red neuronal artificial
Para posteriormente ser entrenado por un conjunto de datos.
Luego nacieron los métodos de conjunto, los cuales pueden describirse como técnicas que utilizan un grupo de modelos “débiles” juntos, con el fin de crear uno más fuerte y agregado.
El Boosting consiste en la idea de filtrar o ponderar los datos que se utilizan para capacitar a nuestro conjunto de modelos “débiles,” para que cada nuevo modelo pondere o “solo se entrene” con observaciones que han sido mal clasificadas por los anteriores modelos.
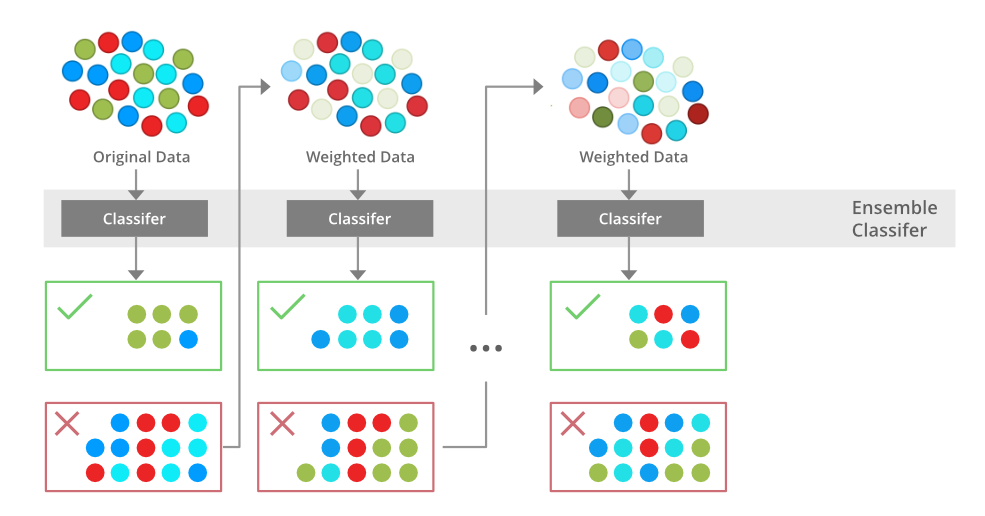
Al hacer esto, nuestro conjunto de modelos aprende a hacer predicciones precisas sobre todo tipo de datos, no solo sobre las observaciones más comunes o fáciles. Además, si uno de los modelos individuales es muy malo para hacer predicciones sobre algún tipo de observación, no importa, ya que los otros \(N - 1\) modelos probablemente lo compensarán.
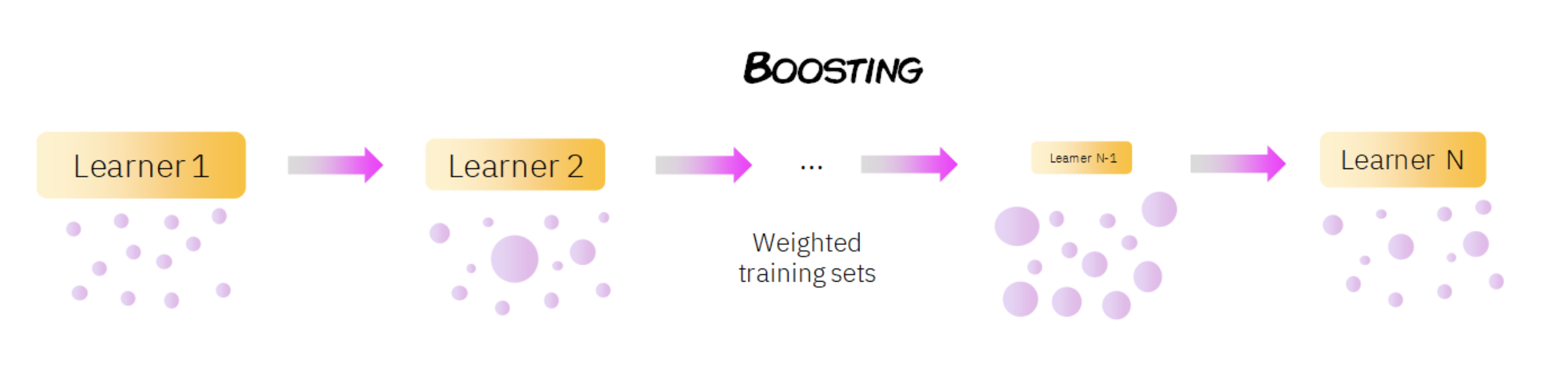
Como se puede ver en la imagen anterior, en boosting el conjunto de datos se pondera (representado por los diferentes tamaños de los datos), de modo que las observaciones que fueron clasificadas incorrectamente por el clasificador \(n\) reciben más importancia en el entrenamiento del modelo \(n + 1\). En general, los métodos de conjunto reducen el sesgo y la varianza de nuestros modelos de aprendizaje automático.
¡¡ RECORDAR !!
Los modelos bootstrap buscan aprender lentamente patrones relevantes a lo largo de muchas iteraciones, de forma que se vaya haciendo un ajuste lento pero preciso.
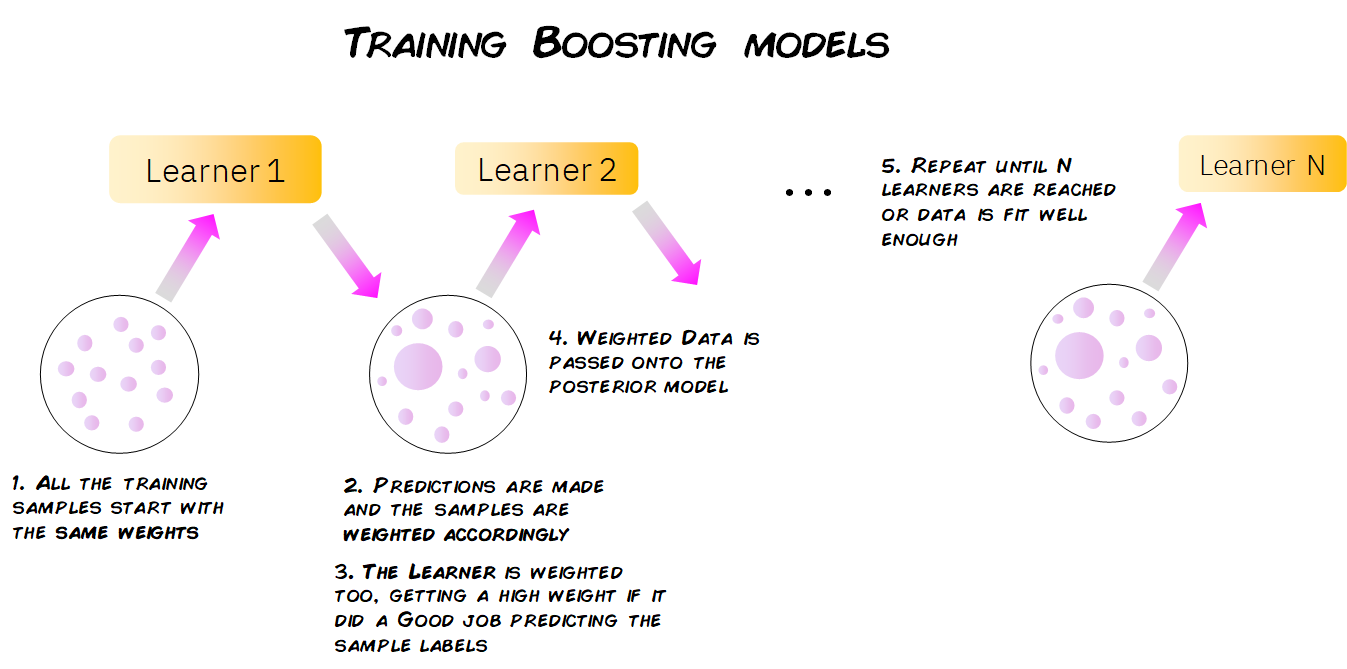
El proceso de entrenamiento depende del algoritmo boosting que estemos usando (Adaboost, LigthGBM, XGBoost, \(\dots\)), pero generalmente sigue este patrón:
Todas las muestras de datos comienzan con los mismos pesos. Estas muestras se utilizan para entrenar un modelo individual (digamos un árbol de decisión).
Se calcula el error de predicción para cada muestra, aumentando los pesos de aquellas muestras que han tenido un error mayor, para hacerlas más importantes para el entrenamiento del siguiente modelo individual.
Dependiendo de qué tan bien le fue a este modelo individual en sus predicciones, se le asigna una importancia/peso.
Los datos ponderados se pasan al modelo posterior y se repiten lo pasos 2) y 3). Este paso se repite hasta que se haya alcanzado un cierto número de modelos o hasta que el error esté por debajo de un cierto umbral.
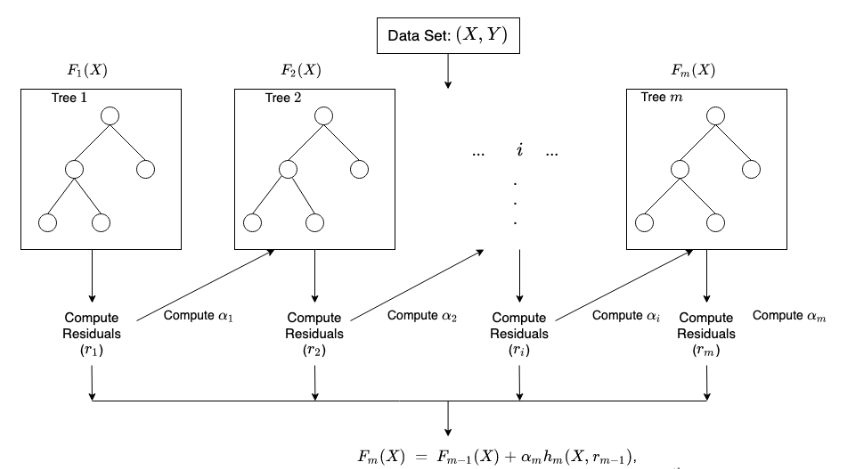
En algunos casos, los modelos de boosting se entrenan con un peso fijo específico para cada modelo (llamado tasa de aprendizaje) y en lugar de dar a cada muestra un peso individual, los modelos se entrenan tratando de predecir las diferencias entre las predicciones anteriores en las muestras y los valores reales de la variable objetivo. Esta diferencia es conocida como residuales.
La forma de ajustar el modelo sigue los siguientes pasos:
Se fija \(\hat{f}(x)=0\) y \(r_i=y_i\) para todos los elementos del conjunto de entrenamiento
Para \(b=1,2,...,B\), repetir:
Ajustar un árbol \(\hat{f}^b\) al conjunto de entrenamiento \((X, r)\)
Actualizar el ajuste \(\hat{f}(x)\) al añadir una nueva versión restringida de un nuevo árbol:
\[\hat{F}_b(X) \leftarrow \hat{F}_{b-1}(X) + \alpha_b\hat{h}_b(X, r_{b-1})\] c) Actualizar los residuos:
\[r_b \leftarrow r_{b-1} - \alpha_b\hat{f}^b(x_i)\]
- Resultado del modelo Boosting:
\[\hat{F}=\sum_{b=1}^{B}\alpha_b\hat{F}_b(x)\] Para calcular \(\alpha_b\) en cada iteración, se usa la siguiente fórmula:
\[\underset{\alpha}{\operatorname{argmin}}=\sum_{i=1}^{b}{L(Y_i, \hat{F}_{i-1}(X_i)+\alpha \hat{h}_i(X_i, r_{i-1}))}\] Donde \(L(Y, F(X))\) es una función de pérdida diferenciable.
4.4.1 Predicciones de Boosting
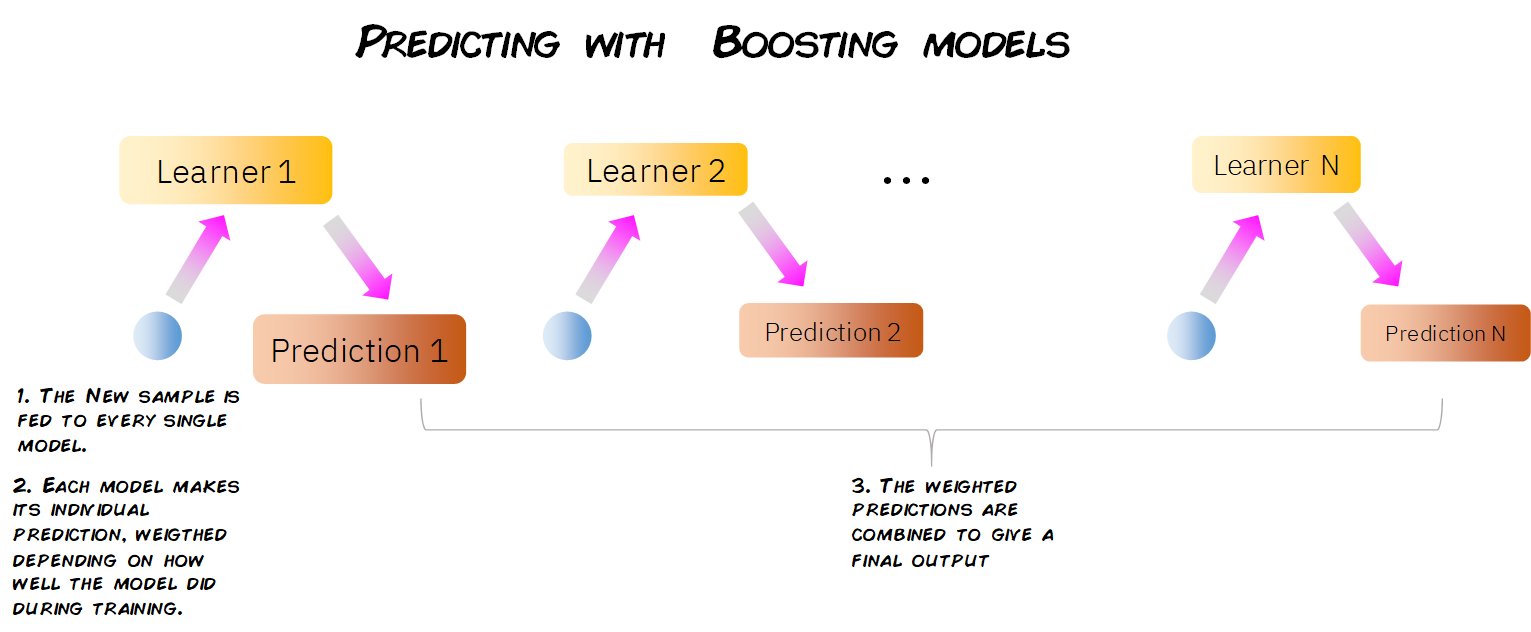
La forma en que un modelo de boosting hace predicciones sobre nuevos datos es muy simple. Cuando obtenemos una nueva observación con sus características, se pasa a través de cada uno de los modelos individuales, haciendo que cada modelo haga su propia predicción.
Luego, teniendo en cuenta el peso de cada uno de estos modelos, todas estas predicciones se escalan y combinan, y se da una predicción global final.
4.4.2 Modelos Boosting
XGBoost
Abreviatura de eXtreme Gradient Boosting, como en Gradient Boosting, ajustamos los árboles a los residuos de las predicciones de árboles anteriores, sin embargo, en lugar de usar árboles de decisión de tamaño fijo convencionales, XGBoost usa un tipo diferente de árboles.
Estos árboles se construyen calculando puntuaciones de similitud entre las observaciones que terminan en un nodo de salida. Además, XGBoost permite la regularización, reduciendo el posible sobreajuste de nuestros árboles individuales y, por lo tanto, del modelo de conjunto general.
Por último, XGBoost está optimizado para superar el límite de los recursos computacionales de los algoritmos de árbol impulsados, lo que lo convierte en un algoritmo rápido y de muy alto rendimiento en términos de tiempo y cálculo.
Adaboost
Abreviatura de Adaptive Boosting, AdaBoost funciona mediante el proceso descrito anteriormente de entrenar secuencialmente, predecir y actualizar los pesos de las muestras mal clasificadas y de los modelos débiles correspondientes.
Se usa principalmente con Decision Tree Stumps: árboles de decisión con solo un nodo raíz y dos nodos de salida, donde solo se evalúa una característica de los datos. Como podemos ver, al tener en cuenta solo una característica de nuestros datos para hacer predicciones, cada pivote es un modelo muy débil. Sin embargo, al combinar muchos de ellos, se puede construir un modelo de conjunto muy robusto y preciso.
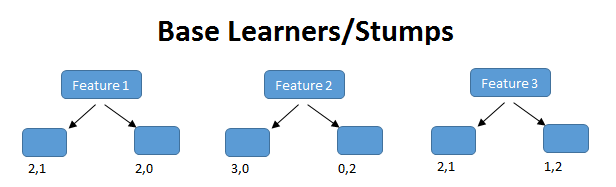
4.4.4 XGBoost para regresión
Paso 1: Separación inicial de datos (test, train)
library(tidymodels)
data(ames)
set.seed(4595)
ames_split <- initial_split(ames, prop = 0.75)
ames_train <- training(ames_split)
ames_test <- testing(ames_split)
ames_folds <- vfold_cv(ames_train)Contando con datos de entrenamiento, procedemos a realizar el feature engineering para extraer las mejores características que permitirán realizar las estimaciones en el modelo.
Paso 2: Pre-procesamiento e ingeniería de variables
receta_casas <- recipe(Sale_Price ~ . , data = ames_train) %>%
step_unknown(Alley) %>%
step_rename(Year_Remod = Year_Remod_Add) %>%
step_rename(ThirdSsn_Porch = Three_season_porch) %>%
step_ratio(Bedroom_AbvGr, denom = denom_vars(Gr_Liv_Area)) %>%
step_mutate(
Age_House = Year_Sold - Year_Remod,
TotalSF = Gr_Liv_Area + Total_Bsmt_SF,
AvgRoomSF = Gr_Liv_Area / TotRms_AbvGrd,
Pool = if_else(Pool_Area > 0, 1, 0),
Exter_Cond = forcats::fct_collapse(Exter_Cond, Good = c("Typical", "Good", "Excellent"))) %>%
step_relevel(Exter_Cond, ref_level = "Good") %>%
step_normalize(all_predictors(), -all_nominal()) %>%
step_dummy(all_nominal()) %>%
step_interact(~ Second_Flr_SF:First_Flr_SF) %>%
step_interact(~ matches("Bsmt_Cond"):TotRms_AbvGrd) %>%
step_rm(
First_Flr_SF, Second_Flr_SF, Year_Remod,
Bsmt_Full_Bath, Bsmt_Half_Bath,
Kitchen_AbvGr, BsmtFin_Type_1_Unf,
Total_Bsmt_SF, Kitchen_AbvGr, Pool_Area,
Gr_Liv_Area, Sale_Type_Oth, Sale_Type_VWD
) %>%
prep()
receta_casas## Recipe
##
## Inputs:
##
## role #variables
## outcome 1
## predictor 73
##
## Training data contained 2197 data points and no missing data.
##
## Operations:
##
## Unknown factor level assignment for Alley [trained]
## Variable renaming for Year_Remod [trained]
## Variable renaming for ThirdSsn_Porch [trained]
## Ratios from Bedroom_AbvGr, Gr_Liv_Area [trained]
## Variable mutation for ~Year_Sold - Year_Remod, ~Gr_Liv_Area + To... [trained]
## Re-order factor level to ref_level for Exter_Cond [trained]
## Centering and scaling for Lot_Frontage, Lot_Area, Year_Built, Year_Remod,... [trained]
## Dummy variables from MS_SubClass, MS_Zoning, Street, Alley, Lot_Shape, Land_Co... [trained]
## Interactions with Second_Flr_SF:First_Flr_SF [trained]
## Interactions with (Bsmt_Cond_Fair + Bsmt_Cond_Good + Bsmt_Cond_No_Ba... [trained]
## Variables removed First_Flr_SF, Second_Flr_SF, Year_Remod, Bsmt_Full_Bath... [trained]Recordemos que la función recipe() solo son los pasos a seguir, necesitamos usar la función prep() que nos devuelve una receta actualizada con las estimaciones y la función juice() que nos devuelve la matriz de diseño.
Paso 3: Selección de tipo de modelo con hiperparámetros iniciales
xgboost_reg_model <- boost_tree(
mode = "regression",
trees = 1000,
tree_depth = tune(),
min_n = tune(),
loss_reduction = tune(),
sample_size = tune(),
mtry = tune(),
learn_rate = tune()
) %>%
set_engine(
"xgboost",
importance = "impurity"
)
xgboost_reg_model## Boosted Tree Model Specification (regression)
##
## Main Arguments:
## mtry = tune()
## trees = 1000
## min_n = tune()
## tree_depth = tune()
## learn_rate = tune()
## loss_reduction = tune()
## sample_size = tune()
##
## Engine-Specific Arguments:
## importance = impurity
##
## Computational engine: xgboostPaso 4: Inicialización de workflow o pipeline
xgboost_reg_workflow <- workflow() %>%
add_model(xgboost_reg_model) %>%
add_recipe(receta_casas)
xgboost_reg_workflow## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: boost_tree()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 11 Recipe Steps
##
## • step_unknown()
## • step_rename()
## • step_rename()
## • step_ratio()
## • step_mutate()
## • step_relevel()
## • step_normalize()
## • step_dummy()
## • step_interact()
## • step_interact()
## • ...
## • and 1 more step.
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Boosted Tree Model Specification (regression)
##
## Main Arguments:
## mtry = tune()
## trees = 1000
## min_n = tune()
## tree_depth = tune()
## learn_rate = tune()
## loss_reduction = tune()
## sample_size = tune()
##
## Engine-Specific Arguments:
## importance = impurity
##
## Computational engine: xgboostPaso 5: Creación de grid search
xgboost_param_grid <- grid_latin_hypercube(
tree_depth(range = c(3, 50)),
min_n(range = c(2,50)),
loss_reduction(range = c(-10, 1.5), trans = log10_trans()),
learn_rate(range = c(-6, -0.25), trans = log10_trans()),
mtry(range = c(1, 70)),
sample_size = sample_prop(),
size = 1000
)
xgboost_param_grid## # A tibble: 1,000 × 6
## tree_depth min_n loss_reduction learn_rate mtry sample_size
## <int> <int> <dbl> <dbl> <int> <dbl>
## 1 8 50 7.99 0.0000189 13 0.910
## 2 7 47 0.000000222 0.144 46 0.986
## 3 32 6 0.00000000222 0.00000352 24 0.750
## 4 29 35 0.00199 0.0000131 16 0.621
## 5 35 16 0.00000646 0.00000246 59 0.560
## 6 15 48 1.46 0.000118 51 0.112
## 7 4 4 0.000000330 0.00000630 26 0.154
## 8 27 10 0.000426 0.269 17 0.278
## 9 50 7 0.807 0.000384 17 0.262
## 10 38 28 0.00970 0.00419 68 0.576
## # … with 990 more rowsPaso 6: Entrenamiento de modelos con hiperparámetros definidos
UseCores <- detectCores() - 1
cluster <- makeCluster(UseCores)
registerDoParallel(cluster)
ctrl_grid <- control_grid(save_pred = T, verbose = T)
xgb1 <- Sys.time()
xgboost_reg_tune_result <- tune_grid(
xgboost_reg_workflow,
resamples = ames_folds,
grid = xgboost_param_grid,
metrics = metric_set(rmse, mae, mape, rsq),
control = ctrl_grid
)
xgb2 <- Sys.time(); xgb2 - xgb1
stopCluster(cluster)
xgboost_reg_tune_result %>% saveRDS("models/xgboost_model_reg.rds")Paso 7: Análisis de métricas de error e hiperparámetros (Vuelve al paso 3, si es necesario)
xgboost_reg_tune_result <- readRDS("models/xgboost_model_reg.rds")
collect_metrics(xgboost_reg_tune_result)## # A tibble: 4,000 × 12
## mtry min_n tree_depth learn_rate loss_reduction sample_size .metric
## <int> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 58 36 36 0.0000895 0.000000405 0.965 mae
## 2 58 36 36 0.0000895 0.000000405 0.965 mape
## 3 58 36 36 0.0000895 0.000000405 0.965 rmse
## 4 58 36 36 0.0000895 0.000000405 0.965 rsq
## 5 45 18 27 0.0000425 0.572 0.314 mae
## 6 45 18 27 0.0000425 0.572 0.314 mape
## 7 45 18 27 0.0000425 0.572 0.314 rmse
## 8 45 18 27 0.0000425 0.572 0.314 rsq
## 9 22 12 25 0.0000154 0.000925 0.287 mae
## 10 22 12 25 0.0000154 0.000925 0.287 mape
## # … with 3,990 more rows, and 5 more variables: .estimator <chr>, mean <dbl>,
## # n <int>, std_err <dbl>, .config <chr>En la siguiente gráfica observamos las distintas métricas de error asociados a los hiperparámetros elegidos:
xgboost_reg_tune_result %>%
autoplot() 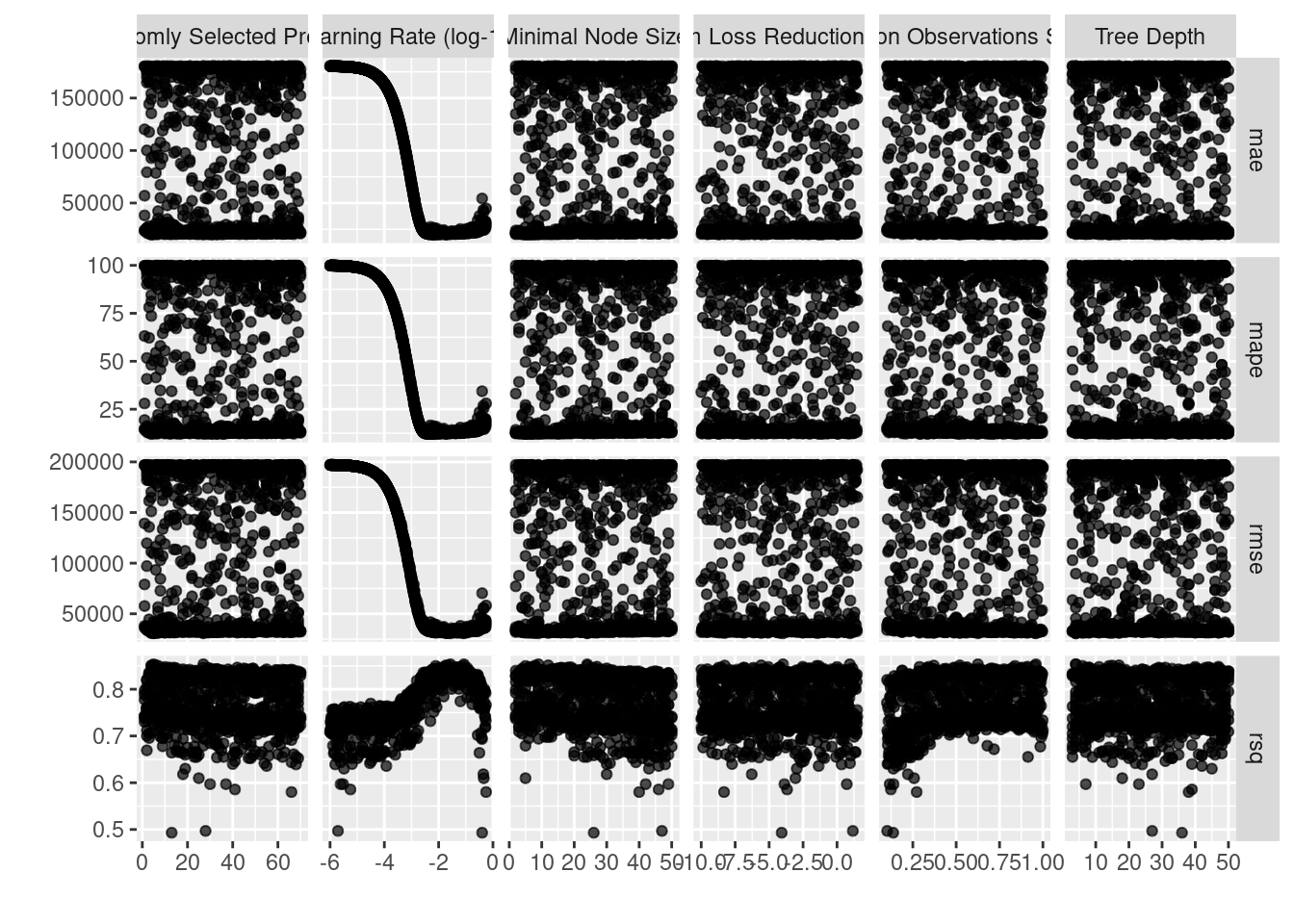
show_best(xgboost_reg_tune_result, n = 10, metric = "rsq") %>%
select(mtry:sample_size, mean:std_err, -n)## # A tibble: 10 × 8
## mtry min_n tree_depth learn_rate loss_reduction sample_size mean std_err
## <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 27 9 4 0.0272 0.000106 0.625 0.853 0.00553
## 2 5 24 4 0.0855 8.75 0.960 0.853 0.00678
## 3 6 12 17 0.0186 0.00000260 0.520 0.851 0.00489
## 4 4 8 15 0.0232 0.00000000536 0.371 0.851 0.00443
## 5 7 24 6 0.0800 0.0311 0.953 0.850 0.00654
## 6 4 5 14 0.00780 0.0457 0.839 0.850 0.00570
## 7 5 27 47 0.0188 0.00298 0.913 0.848 0.00559
## 8 5 8 40 0.0190 0.00000862 0.342 0.848 0.00627
## 9 10 7 11 0.0195 1.01 0.289 0.848 0.00708
## 10 5 19 44 0.0491 0.0000656 0.561 0.847 0.00658Paso 8: Selección de modelo a usar
best_xgboost_reg_model <- select_best(xgboost_reg_tune_result, metric = "rsq")
best_xgboost_reg_model## # A tibble: 1 × 7
## mtry min_n tree_depth learn_rate loss_reduction sample_size .config
## <int> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 27 9 4 0.0272 0.000106 0.625 Preprocessor1_Mo…best_xgboost_reg_1se_model <- xgboost_reg_tune_result %>%
select_by_one_std_err(metric = "rsq", "rsq")
best_xgboost_reg_1se_model## # A tibble: 1 × 14
## mtry min_n tree_depth learn_rate loss_reduction sample_size .metric
## <int> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 4 5 14 0.00780 0.0457 0.839 rsq
## # … with 7 more variables: .estimator <chr>, mean <dbl>, n <int>,
## # std_err <dbl>, .config <chr>, .best <dbl>, .bound <dbl>Paso 9: Ajuste de modelo final con todos los datos (Vuelve al paso 2, si es necesario)
final_xgboost_reg_model <- xgboost_reg_workflow %>%
#finalize_workflow(best_xgboost_model) %>%
finalize_workflow(best_xgboost_reg_1se_model) %>%
fit(data = ames_train)## [01:06:54] WARNING: amalgamation/../src/learner.cc:627:
## Parameters: { "importance" } might not be used.
##
## This could be a false alarm, with some parameters getting used by language bindings but
## then being mistakenly passed down to XGBoost core, or some parameter actually being used
## but getting flagged wrongly here. Please open an issue if you find any such cases.final_xgboost_reg_model## ══ Workflow [trained] ══════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: boost_tree()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 11 Recipe Steps
##
## • step_unknown()
## • step_rename()
## • step_rename()
## • step_ratio()
## • step_mutate()
## • step_relevel()
## • step_normalize()
## • step_dummy()
## • step_interact()
## • step_interact()
## • ...
## • and 1 more step.
##
## ── Model ───────────────────────────────────────────────────────────────────────
## ##### xgb.Booster
## raw: 9.1 Mb
## call:
## xgboost::xgb.train(params = list(eta = 0.0078034925239406, max_depth = 14L,
## gamma = 0.0457345133884295, colsample_bytree = 1, colsample_bynode = 0.173913043478261,
## min_child_weight = 5L, subsample = 0.83899691531139, objective = "reg:squarederror"),
## data = x$data, nrounds = 1000, watchlist = x$watchlist, verbose = 0,
## importance = "impurity", nthread = 1)
## params (as set within xgb.train):
## eta = "0.0078034925239406", max_depth = "14", gamma = "0.0457345133884295", colsample_bytree = "1", colsample_bynode = "0.173913043478261", min_child_weight = "5", subsample = "0.83899691531139", objective = "reg:squarederror", importance = "impurity", nthread = "1", validate_parameters = "TRUE"
## xgb.attributes:
## niter
## callbacks:
## cb.evaluation.log()
## # of features: 23
## niter: 1000
## nfeatures : 23
## evaluation_log:
## iter training_rmse
## 1 195903.219
## 2 194485.609
## ---
## 999 7337.960
## 1000 7331.632Como hemos hablado anteriormente, este último objeto es el modelo final entrenado, el cual contiene toda la información del pre-procesamiento de datos, por lo que en caso de ponerse en producción el modelo, sólo se necesita de este último elemento para poder realizar nuevas predicciones.
Antes de pasar al siguiente paso, es importante validar que hayamos hecho un uso correcto de las variables predictivas. En este momento es posible detectar variables que no estén aportando valor o variables que no debiéramos estar usando debido a que cometeríamos data leakage. Para enfrentar esto, ayuda estimar y ordenar el valor de importancia del modelo
library(vip)
final_xgboost_reg_model %>%
extract_fit_parsnip() %>%
vip::vip(num_features = 25) +
ggtitle("Importancia de las variables")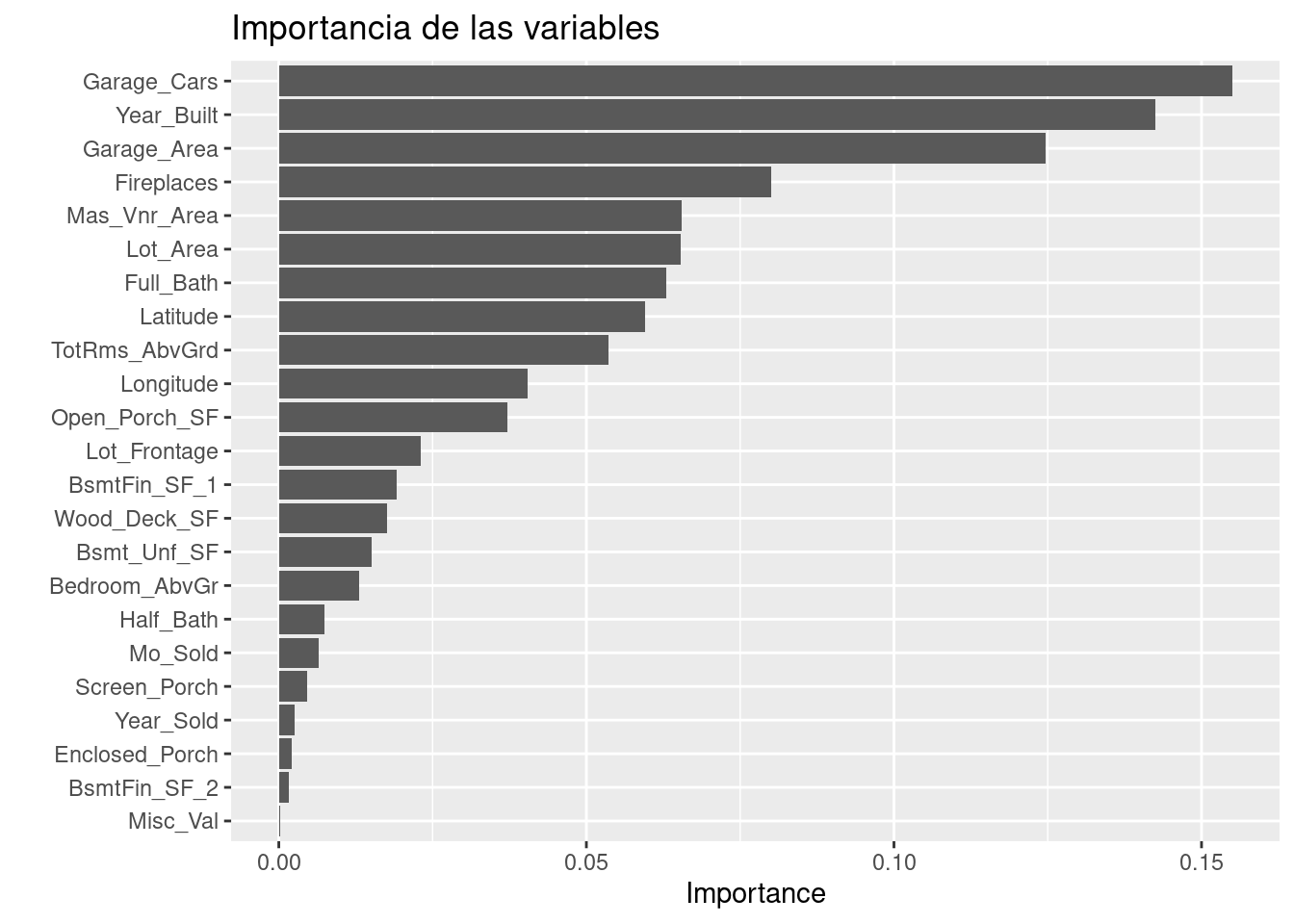
Paso 10: Validar poder predictivo con datos de prueba
Imaginemos por un momento que pasa un mes de tiempo desde que hicimos nuestro modelo, es hora de ponerlo a prueba prediciendo valores de nuevos elementos:
results <- predict(final_xgboost_reg_model, ames_test) %>%
dplyr::bind_cols(truth = ames_test$Sale_Price) %>%
dplyr::rename(pred_xgb_reg = .pred, Sale_Price = truth)
head(results)## # A tibble: 6 × 2
## pred_xgb_reg Sale_Price
## <dbl> <int>
## 1 131668. 105000
## 2 176134. 185000
## 3 176002. 180400
## 4 119015. 141000
## 5 210505. 210000
## 6 218120. 216000multi_metric <- metric_set(rmse, rsq, mae, mape, ccc)
multi_metric(results, truth = Sale_Price, estimate = pred_xgb_reg) %>%
mutate(.estimate = round(.estimate, 2))## # A tibble: 5 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 rmse standard 30205.
## 2 rsq standard 0.86
## 3 mae standard 19721.
## 4 mape standard 12.0
## 5 ccc standard 0.92results %>%
ggplot(aes(x = pred_xgb_reg, y = Sale_Price)) +
geom_point() +
geom_abline(color = "red") +
xlab("Prediction") +
ylab("Observation") +
ggtitle("Comparisson")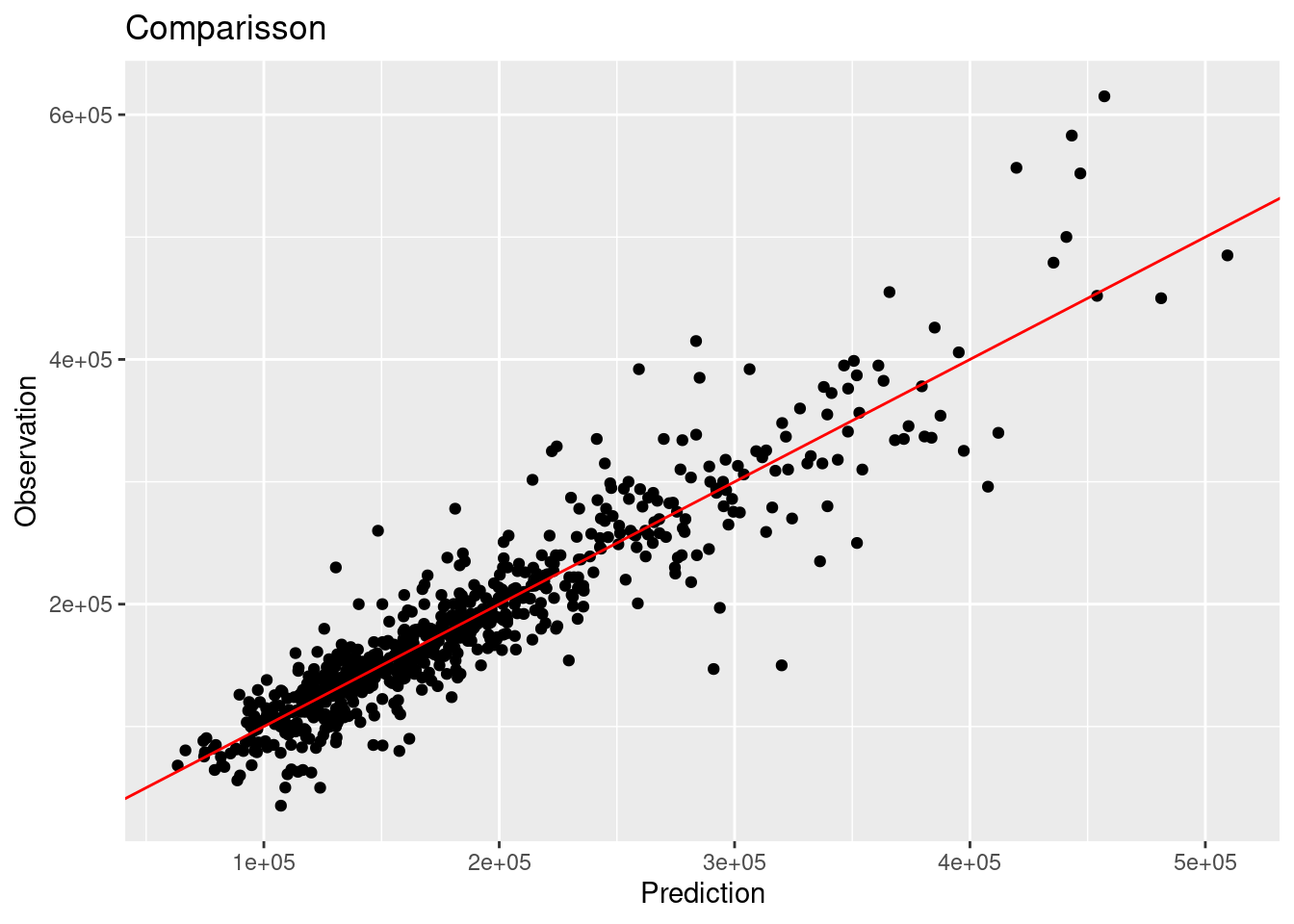
4.4.5 XGBoost para clasificación
Paso 1: Separación inicial de datos (test, train)
set.seed(1234)
telco_split <- initial_split(telco, prop = .70)
telco_train <- training(telco_split)
telco_test <- testing(telco_split)
telco_folds <- vfold_cv(telco_train)
telco_folds## # 10-fold cross-validation
## # A tibble: 10 × 2
## splits id
## <list> <chr>
## 1 <split [4437/493]> Fold01
## 2 <split [4437/493]> Fold02
## 3 <split [4437/493]> Fold03
## 4 <split [4437/493]> Fold04
## 5 <split [4437/493]> Fold05
## 6 <split [4437/493]> Fold06
## 7 <split [4437/493]> Fold07
## 8 <split [4437/493]> Fold08
## 9 <split [4437/493]> Fold09
## 10 <split [4437/493]> Fold10Paso 2: Pre-procesamiento e ingeniería de variables
binner <- function(x) {
x <- cut(x, breaks = c(0, 12, 24, 36,48,60,72), include.lowest = TRUE)
as.numeric(x)
}
telco_rec <- recipe(Churn ~ ., data = telco_train) %>%
update_role(customerID, new_role = "id variable") %>%
step_num2factor(
tenure, transform = binner,
levels = c("0-1 year", "1-2 years", "2-3 years", "3-4 years", "4-5 years", "5-6 years")) %>%
step_normalize(all_numeric_predictors()) %>%
step_dummy(all_nominal_predictors()) %>%
step_impute_median(all_numeric_predictors()) %>%
step_rm(customerID, skip=T) %>%
prep()
telco_rec## Recipe
##
## Inputs:
##
## role #variables
## id variable 1
## outcome 1
## predictor 19
##
## Training data contained 4930 data points and 10 incomplete rows.
##
## Operations:
##
## Factor variables from tenure [trained]
## Centering and scaling for SeniorCitizen, MonthlyCharges, TotalCharges [trained]
## Dummy variables from gender, Partner, Dependents, tenure, PhoneService, Multip... [trained]
## Median imputation for SeniorCitizen, MonthlyCharges, TotalCharges, ge... [trained]
## Variables removed customerID [trained]Paso 3: Selección de tipo de modelo con hiperparámetros iniciales
xgboost_model <- boost_tree(
mode = "classification",
trees = 1000,
tree_depth = tune(),
min_n = tune(),
loss_reduction = tune(),
sample_size = tune(),
mtry = tune(),
learn_rate = tune()
) %>%
set_engine(
"xgboost",
importance = "impurity"
)
xgboost_model## Boosted Tree Model Specification (classification)
##
## Main Arguments:
## mtry = tune()
## trees = 1000
## min_n = tune()
## tree_depth = tune()
## learn_rate = tune()
## loss_reduction = tune()
## sample_size = tune()
##
## Engine-Specific Arguments:
## importance = impurity
##
## Computational engine: xgboostPaso 4: Inicialización de workflow o pipeline
xgboost_workflow <- workflow() %>%
add_model(xgboost_model) %>%
add_recipe(telco_rec)
xgboost_workflow## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: boost_tree()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 5 Recipe Steps
##
## • step_num2factor()
## • step_normalize()
## • step_dummy()
## • step_impute_median()
## • step_rm()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Boosted Tree Model Specification (classification)
##
## Main Arguments:
## mtry = tune()
## trees = 1000
## min_n = tune()
## tree_depth = tune()
## learn_rate = tune()
## loss_reduction = tune()
## sample_size = tune()
##
## Engine-Specific Arguments:
## importance = impurity
##
## Computational engine: xgboostPaso 5: Creación de grid search
xgboost_param_grid <- grid_latin_hypercube(
tree_depth(range = c(2, 30)),
min_n(range = c(2,50)),
loss_reduction(range = c(-10, 1.5), trans = log10_trans()),
learn_rate(range = c(-6, -0.25), trans = log10_trans()),
mtry(range = c(1, 20)),
sample_size = sample_prop(),
size = 500
)
xgboost_param_grid## # A tibble: 500 × 6
## tree_depth min_n loss_reduction learn_rate mtry sample_size
## <int> <int> <dbl> <dbl> <int> <dbl>
## 1 4 6 0.00237 0.0000277 19 0.637
## 2 28 17 0.0189 0.0612 15 0.557
## 3 13 18 0.000467 0.0436 5 0.977
## 4 5 22 0.272 0.388 14 0.192
## 5 10 45 0.000143 0.0383 18 0.480
## 6 24 37 0.00000000778 0.00000364 1 0.233
## 7 11 23 0.0000000629 0.00000795 15 0.531
## 8 9 30 2.07 0.000773 17 0.896
## 9 11 11 0.000000160 0.227 16 0.160
## 10 5 35 0.00000000477 0.0000427 13 0.209
## # … with 490 more rowsPaso 6: Entrenamiento de modelos con hiperparámetros definidos
library(doParallel)
UseCores <- detectCores() - 1
cluster <- makeCluster(UseCores)
registerDoParallel(cluster)
ctrl_grid <- control_grid(save_pred = T, verbose = T)
xgbt1 <- Sys.time()
xgboost_tune_result <- tune_grid(
xgboost_workflow,
resamples = telco_folds,
grid = xgboost_param_grid,
metrics = metric_set(roc_auc, pr_auc)
)
xgb2 <- Sys.time(); xgb2 - xgbt1
stopCluster(cluster)
xgboost_tune_result %>% saveRDS("models/xgboost_model_classification.rds")Paso 7: Análisis de métricas de error e hiperparámetros (Vuelve al paso 3, si es necesario)
xgboost_tune_result <- readRDS("models/xgboost_model_classification.rds")
collect_metrics(xgboost_tune_result)## # A tibble: 1,000 × 12
## mtry min_n tree_depth learn_rate loss_reduction sample_size .metric
## <int> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 17 25 15 0.00000885 5.95e-10 0.461 pr_auc
## 2 17 25 15 0.00000885 5.95e-10 0.461 roc_auc
## 3 9 16 4 0.0757 4.82e- 4 0.349 pr_auc
## 4 9 16 4 0.0757 4.82e- 4 0.349 roc_auc
## 5 2 8 18 0.0000319 9.32e- 8 0.293 pr_auc
## 6 2 8 18 0.0000319 9.32e- 8 0.293 roc_auc
## 7 4 24 25 0.00592 3.02e- 7 0.926 pr_auc
## 8 4 24 25 0.00592 3.02e- 7 0.926 roc_auc
## 9 4 48 28 0.352 6.40e- 5 0.366 pr_auc
## 10 4 48 28 0.352 6.40e- 5 0.366 roc_auc
## # … with 990 more rows, and 5 more variables: .estimator <chr>, mean <dbl>,
## # n <int>, std_err <dbl>, .config <chr>En la siguiente gráfica observamos las distintas métricas de error asociados a los hiperparámetros elegidos:
autoplot(xgboost_tune_result)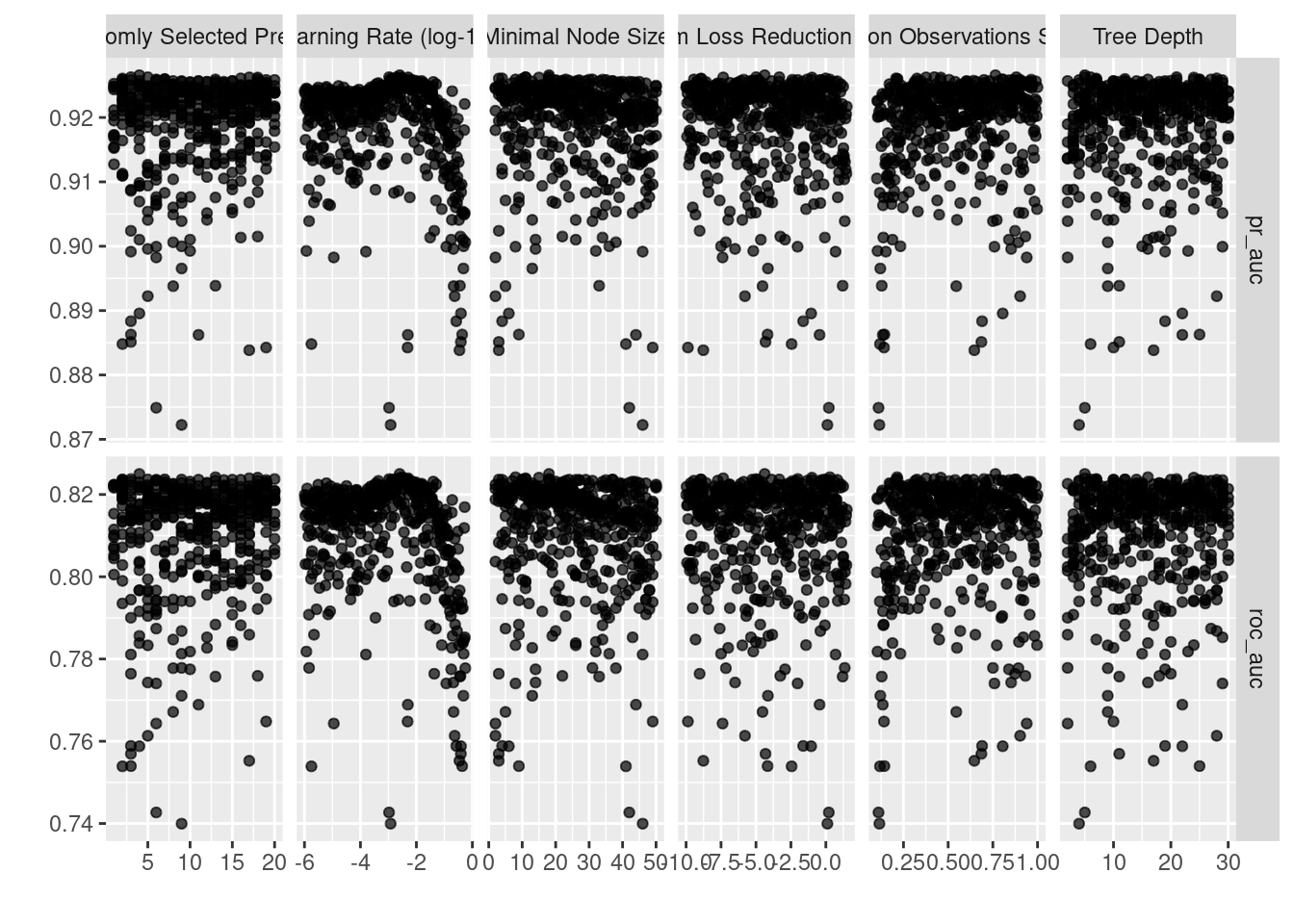
show_best(xgboost_tune_result, n = 10, metric = "roc_auc") ## # A tibble: 10 × 12
## mtry min_n tree_depth learn_rate loss_reduction sample_size .metric
## <int> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 4 18 5 0.00252 0.0000419 0.764 roc_auc
## 2 13 8 16 0.00318 1.92 0.214 roc_auc
## 3 18 15 24 0.00281 0.101 0.459 roc_auc
## 4 17 11 5 0.00508 0.0000000452 0.377 roc_auc
## 5 20 18 7 0.00190 0.00984 0.700 roc_auc
## 6 3 11 21 0.00106 0.0000103 0.423 roc_auc
## 7 7 10 12 0.00291 0.00000000108 0.217 roc_auc
## 8 5 18 6 0.00198 0.000466 0.881 roc_auc
## 9 9 37 14 0.00456 0.000131 0.605 roc_auc
## 10 2 3 7 0.00131 0.00000000122 0.326 roc_auc
## # … with 5 more variables: .estimator <chr>, mean <dbl>, n <int>,
## # std_err <dbl>, .config <chr>show_best(xgboost_tune_result, n = 10, metric = "pr_auc") ## # A tibble: 10 × 12
## mtry min_n tree_depth learn_rate loss_reduction sample_size .metric
## <int> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 4 18 5 0.00252 4.19e- 5 0.764 pr_auc
## 2 3 11 21 0.00106 1.03e- 5 0.423 pr_auc
## 3 5 18 6 0.00198 4.66e- 4 0.881 pr_auc
## 4 17 11 5 0.00508 4.52e- 8 0.377 pr_auc
## 5 18 15 24 0.00281 1.01e- 1 0.459 pr_auc
## 6 16 4 28 0.00215 9.72e- 1 0.208 pr_auc
## 7 2 3 7 0.00131 1.22e- 9 0.326 pr_auc
## 8 7 10 12 0.00291 1.08e- 9 0.217 pr_auc
## 9 6 31 25 0.00384 3.61e-10 0.807 pr_auc
## 10 18 23 27 0.00334 4.55e- 2 0.801 pr_auc
## # … with 5 more variables: .estimator <chr>, mean <dbl>, n <int>,
## # std_err <dbl>, .config <chr>Paso 8: Selección de modelo a usar
best_xgboost_model <- select_best(xgboost_tune_result, metric = "pr_auc")
best_xgboost_model## # A tibble: 1 × 7
## mtry min_n tree_depth learn_rate loss_reduction sample_size .config
## <int> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 4 18 5 0.00252 0.0000419 0.764 Preprocessor1_Mo…best_xgboost_model_1se <- xgboost_tune_result %>%
select_by_one_std_err(metric = "pr_auc", "pr_auc")
best_xgboost_model_1se## # A tibble: 1 × 14
## mtry min_n tree_depth learn_rate loss_reduction sample_size .metric
## <int> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 2 8 18 0.0000319 0.0000000932 0.293 pr_auc
## # … with 7 more variables: .estimator <chr>, mean <dbl>, n <int>,
## # std_err <dbl>, .config <chr>, .best <dbl>, .bound <dbl>Paso 9: Ajuste de modelo final con todos los datos (Vuelve al paso 2, si es necesario)
final_xgboost_model <- xgboost_workflow %>%
#finalize_workflow(best_xgboost_model) %>%
finalize_workflow(best_xgboost_model_1se) %>%
fit(data = telco_test)## [01:07:02] WARNING: amalgamation/../src/learner.cc:627:
## Parameters: { "importance" } might not be used.
##
## This could be a false alarm, with some parameters getting used by language bindings but
## then being mistakenly passed down to XGBoost core, or some parameter actually being used
## but getting flagged wrongly here. Please open an issue if you find any such cases.final_xgboost_model## ══ Workflow [trained] ══════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: boost_tree()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 5 Recipe Steps
##
## • step_num2factor()
## • step_normalize()
## • step_dummy()
## • step_impute_median()
## • step_rm()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## ##### xgb.Booster
## raw: 1.2 Mb
## call:
## xgboost::xgb.train(params = list(eta = 3.18565038552185e-05,
## max_depth = 18L, gamma = 9.31534488985793e-08, colsample_bytree = 1,
## colsample_bynode = 0.666666666666667, min_child_weight = 8L,
## subsample = 0.293253452659119, objective = "binary:logistic"),
## data = x$data, nrounds = 1000, watchlist = x$watchlist, verbose = 0,
## importance = "impurity", nthread = 1)
## params (as set within xgb.train):
## eta = "3.18565038552185e-05", max_depth = "18", gamma = "9.31534488985793e-08", colsample_bytree = "1", colsample_bynode = "0.666666666666667", min_child_weight = "8", subsample = "0.293253452659119", objective = "binary:logistic", importance = "impurity", nthread = "1", validate_parameters = "TRUE"
## xgb.attributes:
## niter
## callbacks:
## cb.evaluation.log()
## # of features: 3
## niter: 1000
## nfeatures : 3
## evaluation_log:
## iter training_logloss
## 1 0.6931346
## 2 0.6931242
## ---
## 999 0.6811728
## 1000 0.6811615Como hemos hablado anteriormente, este último objeto es el modelo final entrenado, el cual contiene toda la información del pre-procesamiento de datos, por lo que en caso de ponerse en producción el modelo, sólo se necesita de este último elemento para poder realizar nuevas predicciones.
Antes de pasar al siguiente paso, es importante validar que hayamos hecho un uso correcto de las variables predictivas. En este momento es posible detectar variables que no estén aportando valor o variables que no debiéramos estar usando debido a que cometeríamos data leakage. Para enfrentar esto, ayuda estimar y ordenar el valor de importancia del modelo.
library(vip)
final_xgboost_model %>%
pull_workflow_fit() %>%
vip::vip() +
ggtitle("Importancia de las variables")## Warning: `pull_workflow_fit()` was deprecated in workflows 0.2.3.
## Please use `extract_fit_parsnip()` instead.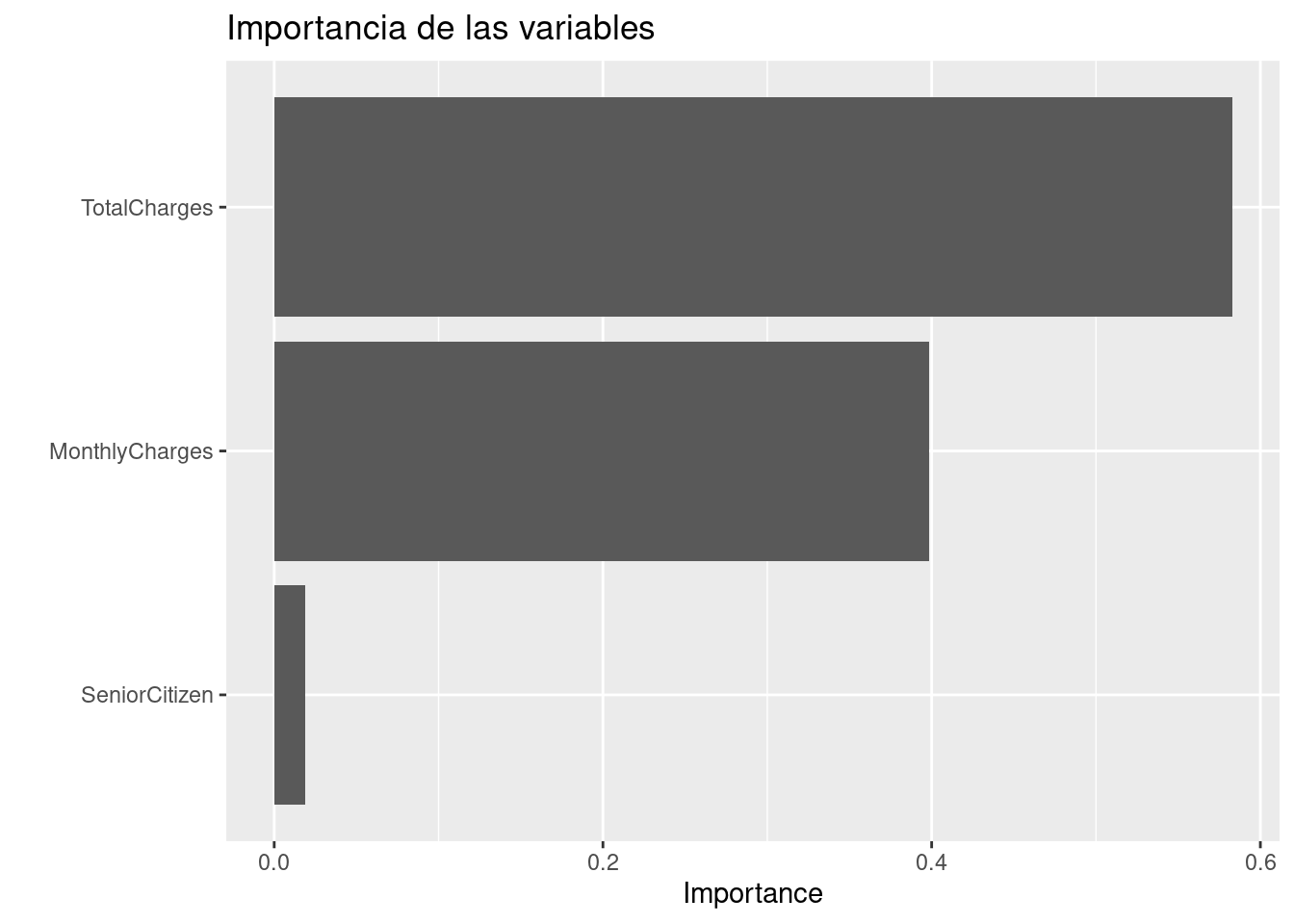
Paso 10: Validar poder predictivo con datos de prueba
Imaginemos por un momento que pasa un mes de tiempo desde que hicimos nuestro modelo, es hora de ponerlo a prueba prediciendo valores de nuevos elementos:
class_results <- predict(final_xgboost_model, telco_test, type = "prob") %>%
bind_cols(Churn = telco_test$Churn) %>%
mutate(Churn = factor(Churn, levels = c('No', 'Yes'), labels = c('No', 'Yes')))
head(class_results)## # A tibble: 6 × 3
## .pred_No .pred_Yes Churn
## <dbl> <dbl> <fct>
## 1 0.512 0.488 No
## 2 0.495 0.505 Yes
## 3 0.508 0.492 No
## 4 0.512 0.488 No
## 5 0.510 0.490 No
## 6 0.502 0.498 Noroc_auc(class_results, truth = Churn, estimate = .pred_Yes, event_level = "second")## # A tibble: 1 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 roc_auc binary 0.833pr_auc(class_results, truth = Churn, estimate = .pred_Yes, event_level = "second")## # A tibble: 1 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 pr_auc binary 0.650A continuación, conoceremos el nivel de sensitividad y especificidad para cada punto de corte:
roc_curve_data <- roc_curve(
class_results,
truth = Churn,
estimate = .pred_Yes,
event_level = 'second'
)
roc_curve_data## # A tibble: 1,864 × 3
## .threshold specificity sensitivity
## <dbl> <dbl> <dbl>
## 1 -Inf 0 1
## 2 0.487 0 1
## 3 0.487 0.000646 1
## 4 0.487 0.00323 1
## 5 0.487 0.00388 1
## 6 0.487 0.00452 1
## 7 0.487 0.00646 1
## 8 0.487 0.00776 1
## 9 0.487 0.00905 1
## 10 0.487 0.0103 1
## # … with 1,854 more rowsA través de estas métricas es posible crear la curva ROC:
roc_curve_plot <- roc_curve_data %>%
ggplot(aes(x = 1 - specificity, y = sensitivity)) +
geom_path(size = 1, colour = 'lightblue') +
geom_abline() +
coord_equal() +
ggtitle("ROC Curve")+
theme_minimal()
roc_curve_plot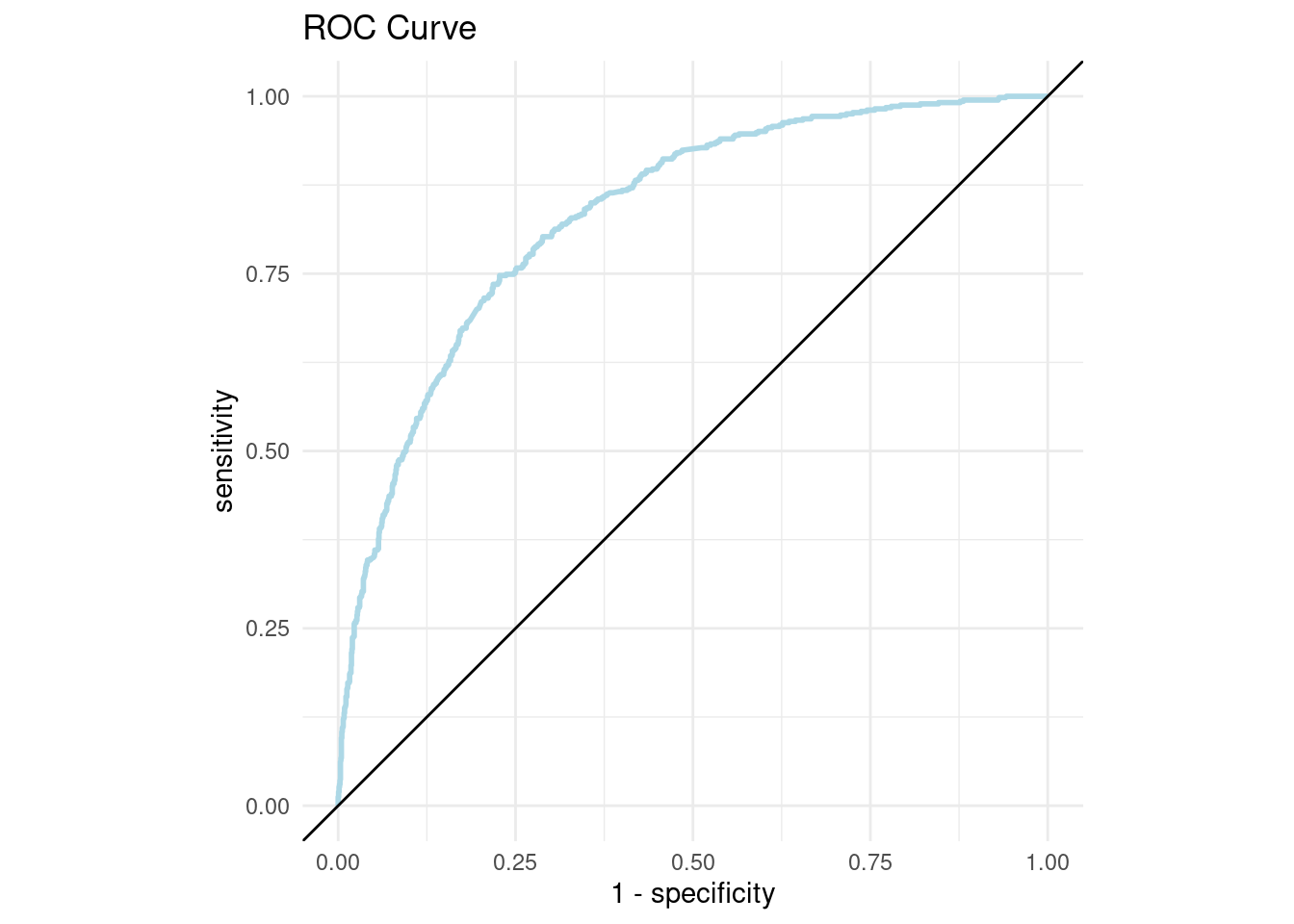
De igual manera, podemos calcular la precisión y cobertura para cada punte de corte:
pr_curve_data <- pr_curve(
class_results,
truth = Churn,
estimate = .pred_Yes,
event_level = 'second'
)
pr_curve_data## # A tibble: 1,863 × 3
## .threshold recall precision
## <dbl> <dbl> <dbl>
## 1 Inf 0 1
## 2 0.507 0.00177 1
## 3 0.507 0.00353 1
## 4 0.507 0.00707 1
## 5 0.507 0.0106 1
## 6 0.507 0.0124 1
## 7 0.507 0.0124 0.875
## 8 0.507 0.0141 0.889
## 9 0.507 0.0159 0.9
## 10 0.507 0.0177 0.909
## # … with 1,853 more rowsY graficar su respectiva curva:
pr_curve_plot <- pr_curve_data %>%
ggplot(aes(x = recall, y = precision)) +
geom_path(size = 1, colour = 'lightblue') +
coord_equal() +
ggtitle("Precision vs Recall")+
theme_minimal()
pr_curve_plot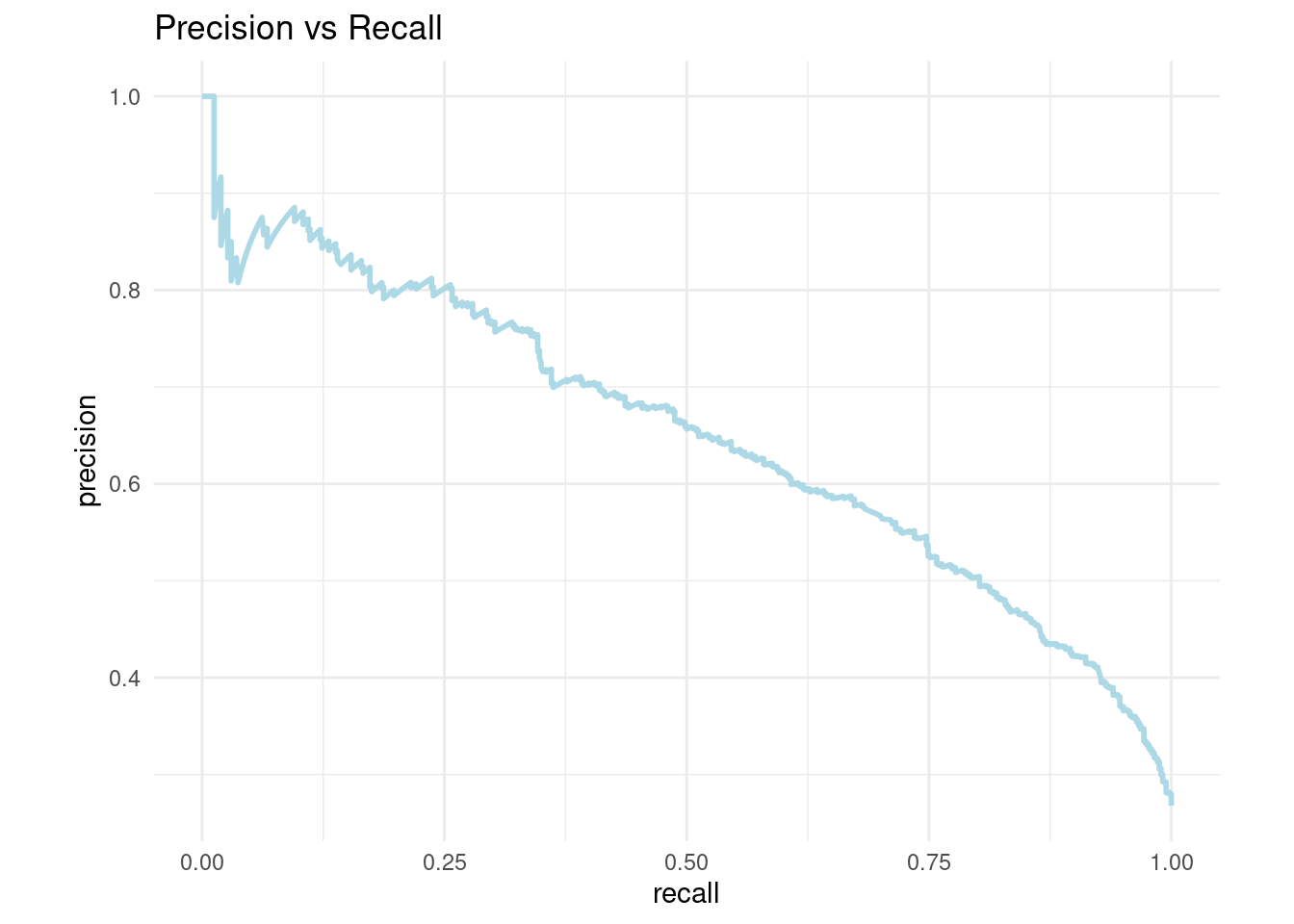
4.5 Ejercicios
Ejecutar un modelo propio usando Adaboost. Cada alumno deberá proponer su propia configuración y comparar resultados con XGBoost:
adaboost_model <- boost_tree(
mode = "classification",
trees = 1000,
tree_depth = tune(),
min_n = tune(),
loss_reduction = tune(),
sample_size = tune(),
mtry = tune(),
learn_rate = tune()
) %>%
set_engine("C5.0", importance = "impurity")