Capítulo 7 Interpretabilidad de modelos
Interpretabilidad: En Machine Learning, nos referimos a interpretabilidad al grado en el que un humano puede entender la causa de una decisión o clasificación, la cual nos permite identificar y evitar tener sesgo, injusticia, inequidad en los modelos que generamos.
Poder interpretar nuestros modelos nos brinda más confianza en que lo que estamos haciendo es correcto (además de las métricas de desempeño). Por otro lado, para la gente que lo ocupa, permite transparentar y tener más confianza al modelo.
Ejemplos
Etiquetado: Google photos (2015) etiqueta incorrectamente personas afroamericanas como gorillas.
Facial Recognition (IBM, Microsoft, Megvii): Reconocimiento para hombres blancos 99%, mujeres afroamericanas 35%.
Facebook automatic translation: Arresto de un palestino por traducción incorrecta de “buenos días” en hebreo a “atácalos.”
Interpretabilidad en ML
General Data Protection Regulation (GDPR): Desde mayo de 2018 existe el right to explanation. Por ejemplo: Algoritmos de predicción de riesgo en créditos hipotecarios.
Se puede tener interpretabilidad de modelos de aprendizaje supervisado.
Se tiene la creencia equivocada de que en Europa no se puede ocupar Deep Learning debido a la falta de interpretabilidad y el GDPR. Esto no es verdad.
Es verdad que preferimos ocupar modelos más simples porque nos permiten entender -y explicar- de manera más sencilla por qué se están tomando las decisiones.
Te recomiendo leer el artículo Why should I trust you? (2016) base de mucho de lo desarrollado para interpretabilidad.
7.1 LIME
Acrónimo de Local Interpretable Model-Agnostic Explanation. El objetivo es tener explicacion que un humano pueda entender sobre cualquier modelo supervisado a través de un modelo local más simple.
La explicación se genera para cada predicción realizada. Esta basado en la suposición de que un modelo complejo es lineal en una escala local.
En el contexto de LIME:
Local: Se refiere a que un modelo simple es lo suficientemente bueno/igual de bueno localmente que uno complejo globalmente.
Interpretable: Se refiere a que la explicación debe ser entendida por un ser humano.
Model-agnostic: Se refiere a tratar a cualquier modelo de clasificación, complejo o no, como una caja negra a la que metemos observaciones y obtenemos predicciones, no nos interesa cómo genera estas predicciones, lo que nos interesa es generarlas.
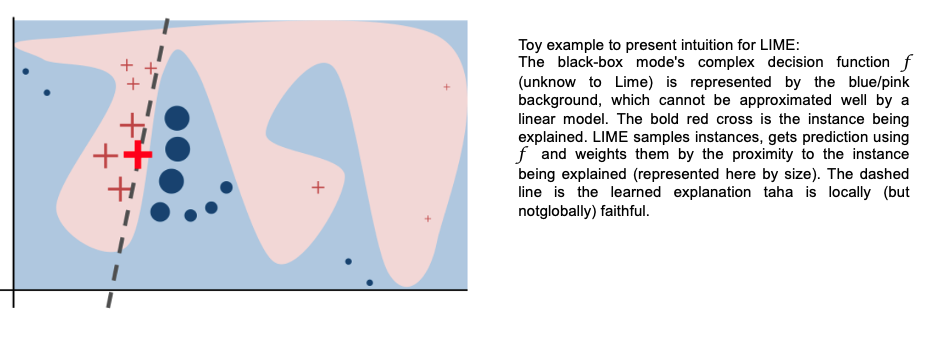
7.1.1 Proceso
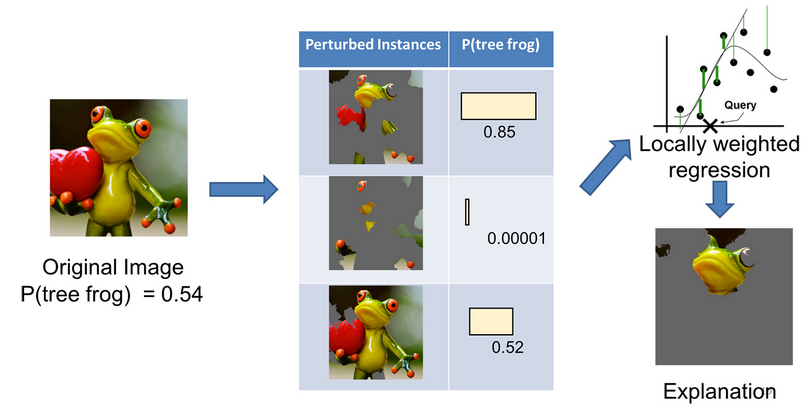
El objetivo de LIME es entender por qué el modelo de machine learning hace cierta predicción, para ello LIME prueba qué pasa con las predicciones si le brindamos al modelo las mismas observaciones pero con variaciones.
Genera un nuevo set de datos que consiste de una muestra permutada con sus predicciones originales. Con este nuevo set LIME entrena un modelo interpretable que puede ser:
- regresión lineal como LASSO
- regresión logística
- árboles de decisión
- Naive Bayes
- K-NN.
- etc.
Este modelo interpretable es ponderado por la proximidad de las observaciones en la muestra a la instancia de interés (la predicción que queremos explicar).
El modelo generado debe ser una buena aproximación al modelo de caja negra localmente, pero no necesariamente en forma global. A esto se le llama local fidelity.
Para entrenar el modelo interpertable, seguimos los siguientes pasos:
Seleccionamos la observación de la que queremos una explicación.
Seleccionamos una vecindad para que LIME ajuste el modelo.
Seleccionamos el número de features más importantes con los que queremos realizar la explicación (se recomienda que sea menor a \(10\)).
LIME genera perturbaciones en una muestra de datos del conjunto de datos
- Texto: “Agrega” o “quita” palabras del texto original aleatoriamente.

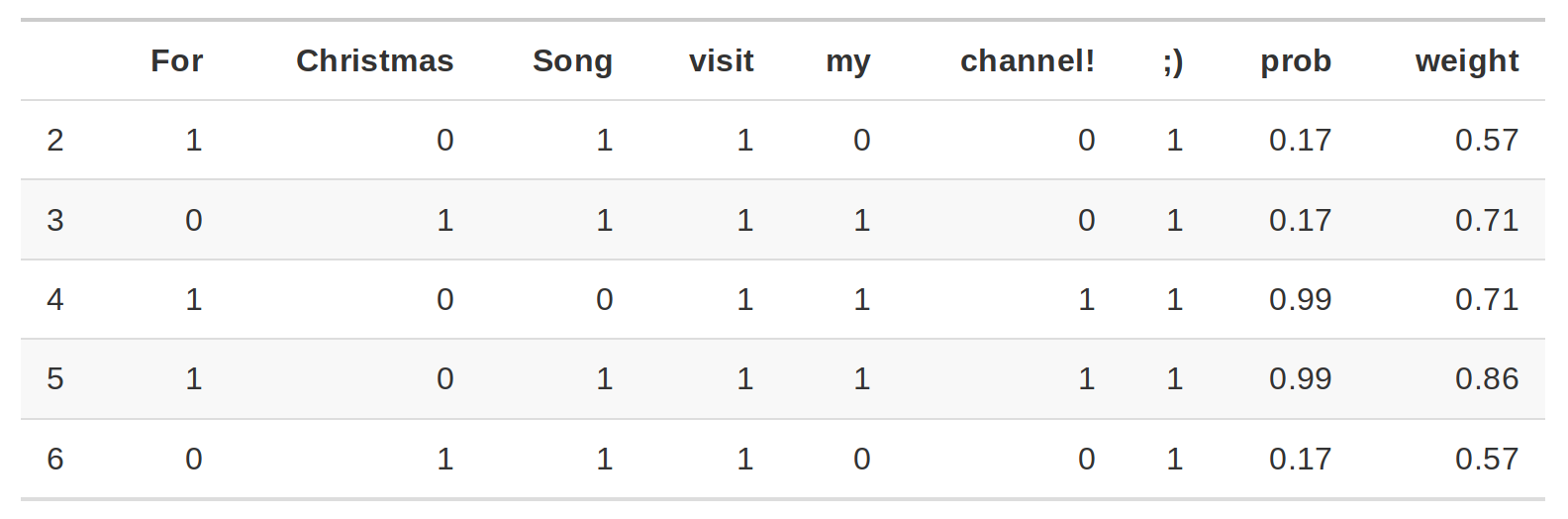
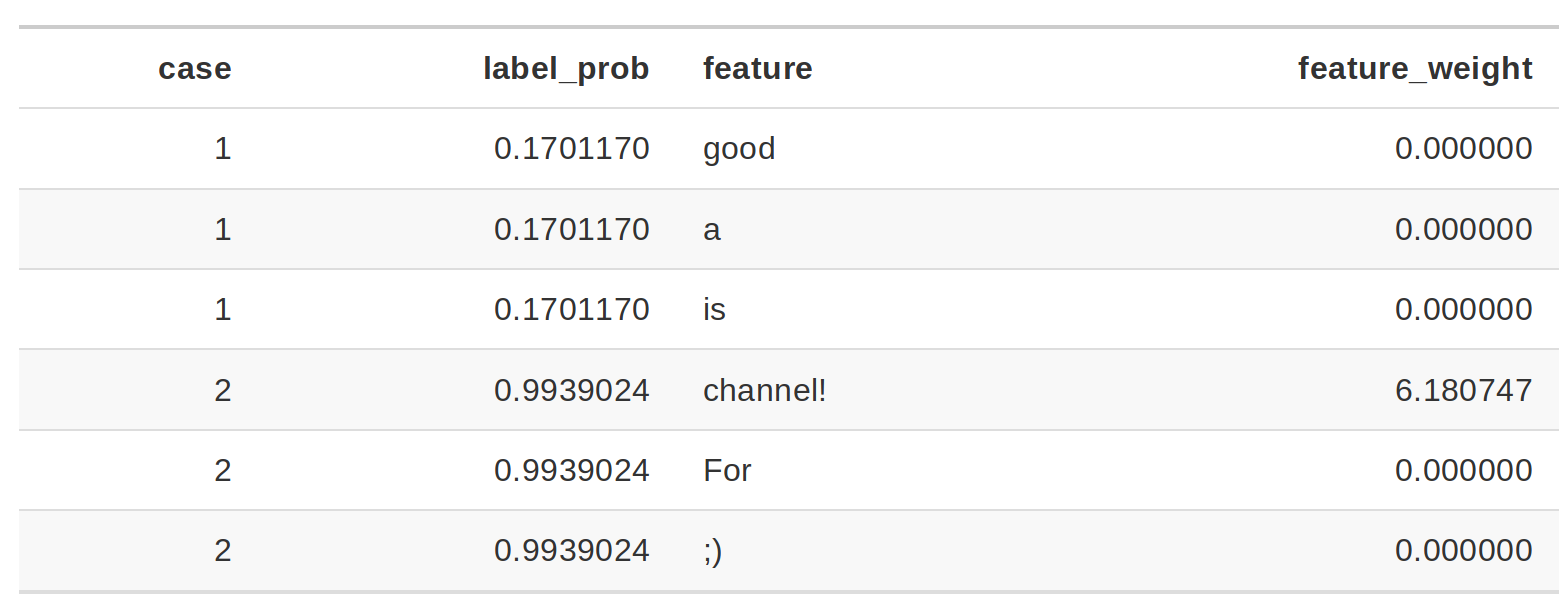
La columna de probabilidad corresponde a la probabilidad de que el enunciado sea Spam o no. La columna peso corresponde a la proximidad del enunciado con variación al enunciado original y está calculado como 1 menos la proporción de palabras que fueron eliminadas.
Por ejemplo: Si una de 7 palabras fueron removidas, el peso correspondería a: \(1- 1/7=0.86\).
Al pasar dos enunciados al modelo de interpretabilidad se identifica que para los casos donde está la palabra channel! el enunciado será clasificado como spam que es el feature con mayor peso para la etiqueta spam.
- Imágenes: “Apaga” y “prende” pixeles de la imágen original.


- Datos tabulares: De cada feature genera nuevas muestras tomadas de una distribución normal con la \(\mu\) y \(\sigma\) del feature.
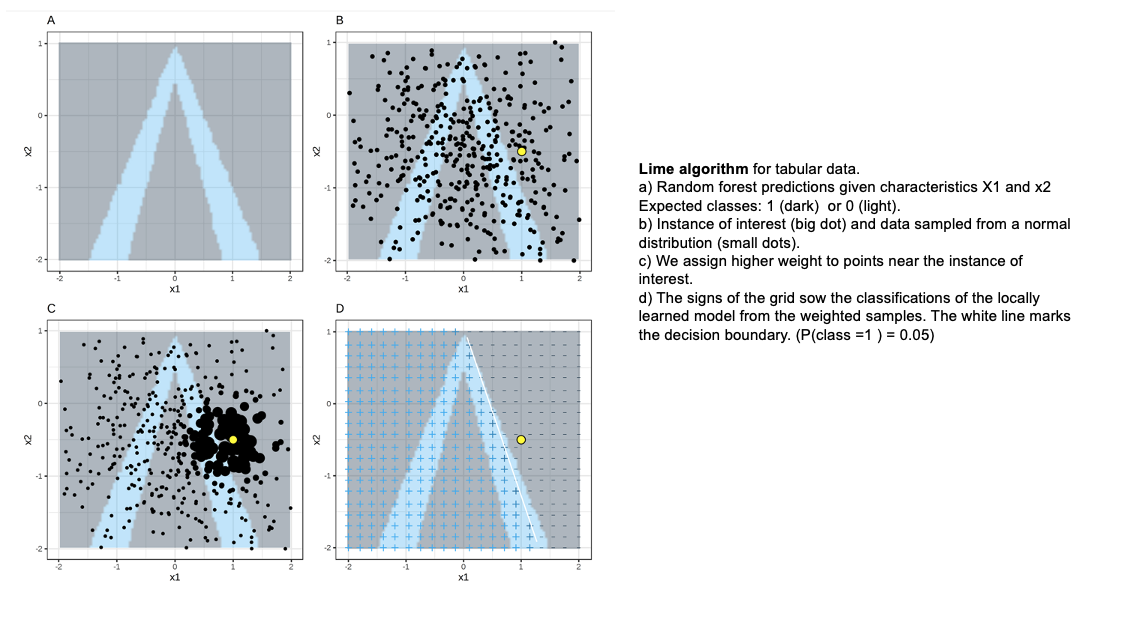
Las observaciones más “cercanas” tendrán más peso que el resto. LIME ocupa un kernel de suavizamiento exponencial.
La implementación de LIME ocupa como kernel \(0.75\) veces la raíz cuadrada del número de features que tenga nuestro dataset. ¿Eso es bueno o malo? Hasta el momento no hay una justificación matemática o estadística que justifique el definir ese número.
Obtiene las predicciones del modelo de caja negra para las observaciones generadas en el paso \(3\).
Calcula las distancias entre la predicción original y las obtenidas con los datos modificados.
Datos tabulares: Distancia euclidiana por default.
Datos numéricos: Se obtiene la media y desviación estándar y se discretiza a sus cuartiles.
Datos categóricos: Se calcula la frecuencia de cada valor.
Texto: Distancia coseno.
Imágenes: Distancia euclidiana.
- Convierte la distancia a un score de similitud.
Datos tabulares: Utiliza el kernel de suavizamiento exponencial.
Texto: Distancia coseno.
Imágenes:
Genera un modelo simple con los datos modificados
Selecciona las \(m\) mejores características (depende del modelo utilizado para crear el modelo de interpretabilidad) como explicación para la predicción del modelo de caja negra.
7.1.2 Características principales
- Vecindad: kernel con suavizamiento exponencial. Peso de influencia
- Similitud: Con respecto a las observaciones originales.
- Selección de variables: Las variables que explican la predicción generada.
Ventajas:
- Fácil de implementar.
- Se puede ocupar en datos tabulares, imágenes y texto.
- Existen paquetes de implementación para R (lime) y Python (lime).
- Las explicaciones son cortas (pocos features), por lo que son más fáciles de entender por un humano no entrenado en machine learning.
- La métrica de fidelity nos permite identificar qué tan confiable es el modelo de interpretabilidad en explicar las predicciones del modelo de caja negra en las vecindad del punto de interés.
- Se pueden ocupar otros features en el modelo de interpretabilidad que los ocupados para entrenar el de caja negra.
Desventajas:
La selección correcta de vecindad es el problema más grave de LIME. Para minimizar este problema deberemos probar con diferentes vecindades y ver cuál(es) son las de mayor sentido.
Variación de las observaciones originales: ¿Qué tal que la distribución no es normal? Al muestrear de una distribución gausiana podemos ignorar correlaciones entre features.
Dependiendo del tamaño de la vecindad tendremos resultados muy diferentes. Este es el mayor problema de LIME.
7.1.3 Implementación con R
library(pdp)
library(vip)
library(randomForest)
library(lime)set.seed(123)
model_rf <- randomForest(
x = dplyr::select(telco_train, -Churn),
y = telco_train$Churn,
ntree = 100
)explainer_caret <- lime::lime(dplyr::select(telco_train, -Churn), model_rf)Veamos cómo llegaron a ser la predicciones, usando Lime.
model_type.randomForest <- function(x,...){
return("classification") # for classification problem
}
predict_model.randomForest <- function(x, newdata, type = "prob") {
# return prediction value
predict(x, newdata, type = type) %>% as.data.frame()
}set.seed(123)
new_data <- telco_train %>% dplyr::select(-Churn) %>% .[2,]
new_data %>% t()## [,1]
## SeniorCitizen -0.4417148
## MonthlyCharges 0.6636772
## TotalCharges 0.4721422
## gender_Male 1.0000000
## Partner_Yes 1.0000000
## Dependents_Yes 1.0000000
## tenure_X1.2.years 0.0000000
## tenure_X2.3.years 0.0000000
## tenure_X3.4.years 1.0000000
## tenure_X4.5.years 0.0000000
## tenure_X5.6.years 0.0000000
## PhoneService_Yes 1.0000000
## MultipleLines_Yes 0.0000000
## InternetService_Fiber.optic 1.0000000
## InternetService_No 0.0000000
## OnlineSecurity_Yes 0.0000000
## OnlineBackup_Yes 0.0000000
## DeviceProtection_Yes 1.0000000
## TechSupport_Yes 0.0000000
## StreamingTV_Yes 1.0000000
## StreamingMovies_Yes 0.0000000
## Contract_One.year 1.0000000
## Contract_Two.year 0.0000000
## PaperlessBilling_Yes 1.0000000
## PaymentMethod_Credit.card..automatic. 0.0000000
## PaymentMethod_Electronic.check 1.0000000
## PaymentMethod_Mailed.check 0.0000000explanation <- lime::explain(
x = new_data,
explainer = explainer_caret,
feature_select = "auto", # Method of feature selection for lime
n_features = 10, # Number of features to explain the model
n_labels = 1
)Para obtener una representación más intuitiva, podemos usar plot_features()
proporcionado para obtener una descripción visual de las explicaciones.
plot_features(explanation, ncol = 1)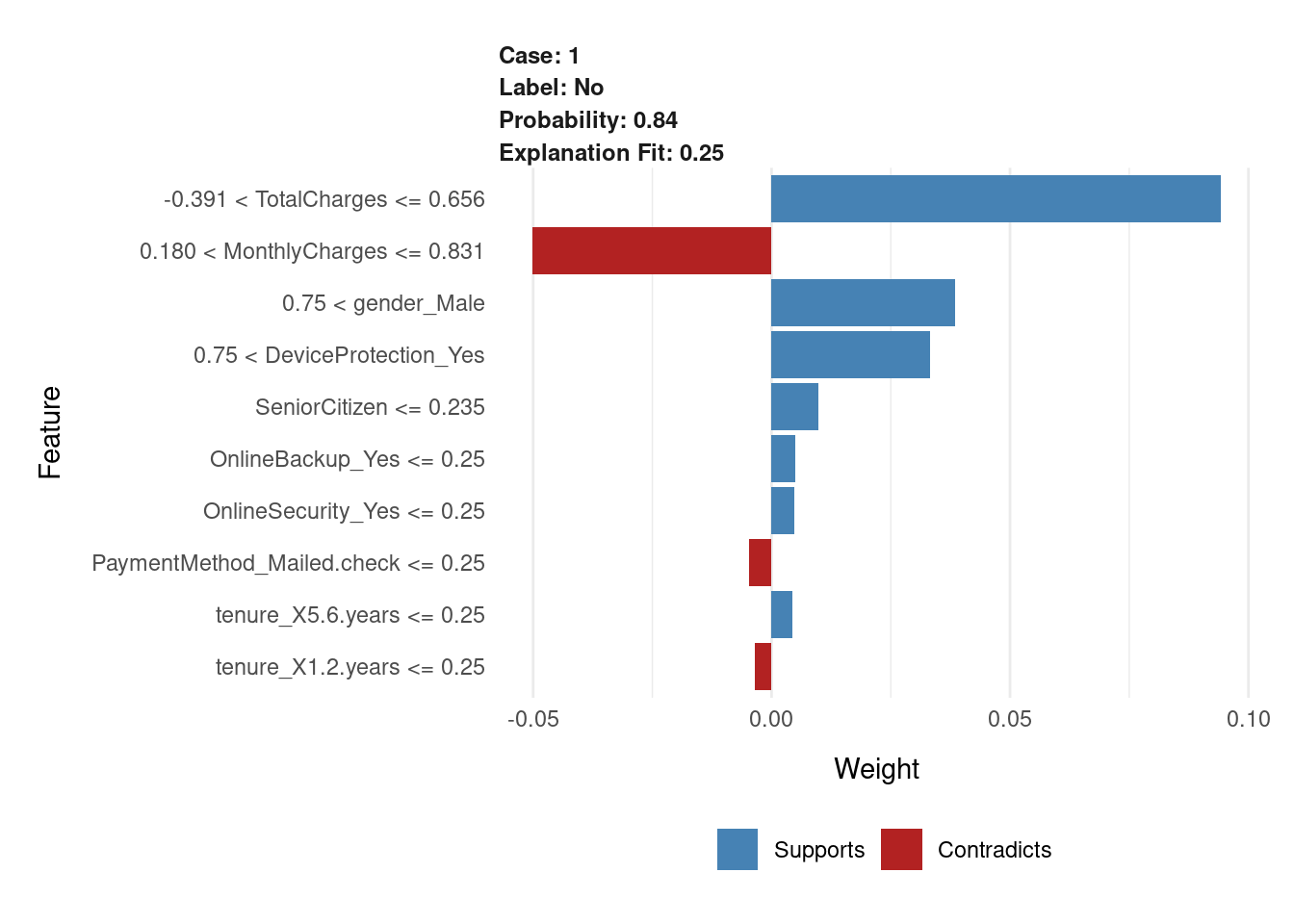
Otro ejemplo
set.seed(123)
new_data2 <- telco_train %>% dplyr::select(-Churn) %>% .[c(2, 4),]
new_data2 %>% t()## [,1] [,2]
## SeniorCitizen -0.4417148 2.2634452
## MonthlyCharges 0.6636772 0.6487142
## TotalCharges 0.4721422 -0.8504924
## gender_Male 1.0000000 0.0000000
## Partner_Yes 1.0000000 0.0000000
## Dependents_Yes 1.0000000 0.0000000
## tenure_X1.2.years 0.0000000 0.0000000
## tenure_X2.3.years 0.0000000 0.0000000
## tenure_X3.4.years 1.0000000 0.0000000
## tenure_X4.5.years 0.0000000 0.0000000
## tenure_X5.6.years 0.0000000 0.0000000
## PhoneService_Yes 1.0000000 1.0000000
## MultipleLines_Yes 0.0000000 1.0000000
## InternetService_Fiber.optic 1.0000000 1.0000000
## InternetService_No 0.0000000 0.0000000
## OnlineSecurity_Yes 0.0000000 0.0000000
## OnlineBackup_Yes 0.0000000 0.0000000
## DeviceProtection_Yes 1.0000000 0.0000000
## TechSupport_Yes 0.0000000 0.0000000
## StreamingTV_Yes 1.0000000 0.0000000
## StreamingMovies_Yes 0.0000000 1.0000000
## Contract_One.year 1.0000000 0.0000000
## Contract_Two.year 0.0000000 0.0000000
## PaperlessBilling_Yes 1.0000000 1.0000000
## PaymentMethod_Credit.card..automatic. 0.0000000 0.0000000
## PaymentMethod_Electronic.check 1.0000000 1.0000000
## PaymentMethod_Mailed.check 0.0000000 0.0000000explanation2 <- lime::explain(
x = new_data2,
explainer = explainer_caret,
feature_select = "auto", # Method of feature selection for lime
n_features = 10, # Number of features to explain the model
n_labels = 1
)
plot_features(explanation2, ncol = 2)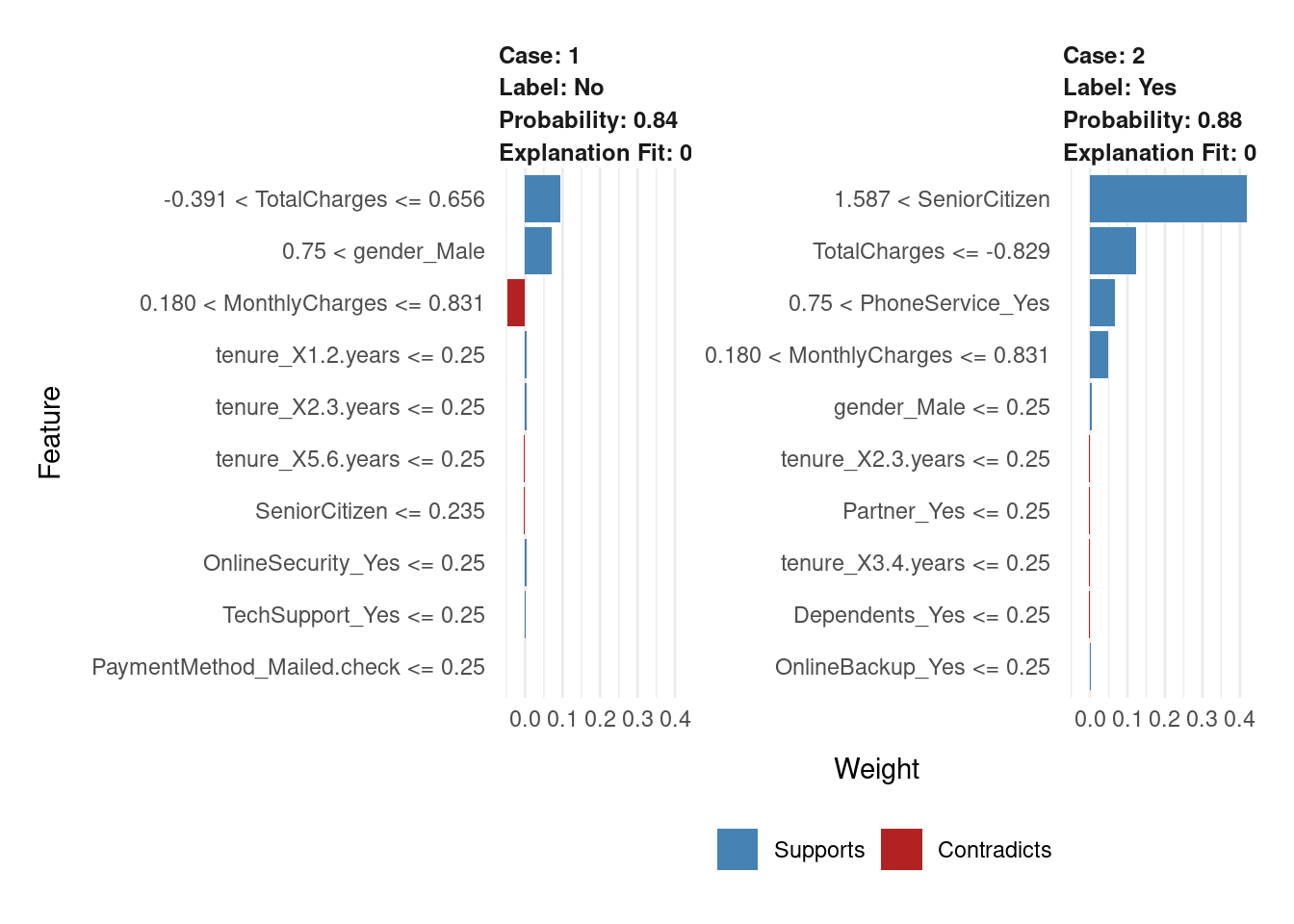
7.2 DALEXtra
El marco tidymodels no contiene software para explicaciones de modelos. En cambio, los modelos entrenados y evaluados con tidymodels se pueden explicar con paquetes complementarios como lime, vip y DALEX:
- DALEX: Contiene funciones que usamos cuando queremos usar métodos explicativos independientes del modelo, por lo que se pueden aplicar a cualquier algoritmo.
Construyamos explicaciones independientes del modelo de regresión de XGBoost para descubrir por qué hacen las predicciones que hacen. Podemos usar el paquete adicional DALEXtra para implementar DALEX, que brinda soporte para tidymodels.
# Se declara el modelo de clasificación
xgboost_reg_model <- boost_tree(
mode = "regression",
trees = 1000,
tree_depth = tune(),
min_n = tune(),
loss_reduction = tune(),
sample_size = tune(),
mtry = tune(),
learn_rate = tune()
) %>%
set_engine("xgboost")
# Se declara el flujo de trabajo
xgboost_workflow <- workflow() %>%
add_model(xgboost_reg_model) %>%
add_recipe(receta_casas_prep)
xgboost_tune_result <- readRDS("models/xgboost_model_reg.rds")
best_xgboost_model_1se <- select_by_one_std_err(
xgboost_tune_result, metric = "rsq", "rsq")
# Selección del mejor modelo
final_xgboost_model <- xgboost_workflow %>%
finalize_workflow(best_xgboost_model_1se) %>%
fit(data = ames_train)library(DALEXtra)
explainer_xgb <- explain_tidymodels(
final_xgboost_model,
data = ames_train,
y = ames_train$Sale_Price ,
label = "XGBoost",
verbose = TRUE
)## Preparation of a new explainer is initiated
## -> model label : XGBoost
## -> data : 2197 rows 74 cols
## -> data : tibble converted into a data.frame
## -> target variable : 2197 values
## -> predict function : yhat.workflow will be used ( default )
## -> predicted values : No value for predict function target column. ( default )
## -> model_info : package tidymodels , ver. 0.2.0 , task regression ( default )
## -> predicted values : numerical, min = 36927.61 , mean = 180440.3 , max = 704172.8
## -> residual function : difference between y and yhat ( default )
## -> residuals : numerical, min = -49510.72 , mean = 117.1645 , max = 50827.19
## A new explainer has been created!Las explicaciones del modelo local proporcionan información sobre una predicción para una sola observación. Por ejemplo, consideremos una casa dúplex antigua en el vecindario de North Ames.
duplex <- ames_train[537,]
duplex %>% glimpse()## Rows: 1
## Columns: 74
## $ MS_SubClass <fct> Duplex_All_Styles_and_Ages
## $ MS_Zoning <fct> Residential_Low_Density
## $ Lot_Frontage <dbl> 60
## $ Lot_Area <int> 7200
## $ Street <fct> Pave
## $ Alley <fct> No_Alley_Access
## $ Lot_Shape <fct> Regular
## $ Land_Contour <fct> Lvl
## $ Utilities <fct> AllPub
## $ Lot_Config <fct> Inside
## $ Land_Slope <fct> Gtl
## $ Neighborhood <fct> North_Ames
## $ Condition_1 <fct> Norm
## $ Condition_2 <fct> Norm
## $ Bldg_Type <fct> Duplex
## $ House_Style <fct> One_Story
## $ Overall_Cond <fct> Average
## $ Year_Built <int> 1949
## $ Year_Remod_Add <int> 1950
## $ Roof_Style <fct> Gable
## $ Roof_Matl <fct> CompShg
## $ Exterior_1st <fct> BrkFace
## $ Exterior_2nd <fct> Stone
## $ Mas_Vnr_Type <fct> None
## $ Mas_Vnr_Area <dbl> 0
## $ Exter_Cond <fct> Typical
## $ Foundation <fct> Slab
## $ Bsmt_Cond <fct> No_Basement
## $ Bsmt_Exposure <fct> No_Basement
## $ BsmtFin_Type_1 <fct> No_Basement
## $ BsmtFin_SF_1 <dbl> 5
## $ BsmtFin_Type_2 <fct> No_Basement
## $ BsmtFin_SF_2 <dbl> 0
## $ Bsmt_Unf_SF <dbl> 0
## $ Total_Bsmt_SF <dbl> 0
## $ Heating <fct> Wall
## $ Heating_QC <fct> Fair
## $ Central_Air <fct> N
## $ Electrical <fct> FuseF
## $ First_Flr_SF <int> 1040
## $ Second_Flr_SF <int> 0
## $ Gr_Liv_Area <int> 1040
## $ Bsmt_Full_Bath <dbl> 0
## $ Bsmt_Half_Bath <dbl> 0
## $ Full_Bath <int> 2
## $ Half_Bath <int> 0
## $ Bedroom_AbvGr <int> 2
## $ Kitchen_AbvGr <int> 2
## $ TotRms_AbvGrd <int> 6
## $ Functional <fct> Typ
## $ Fireplaces <int> 0
## $ Garage_Type <fct> Detchd
## $ Garage_Finish <fct> Unf
## $ Garage_Cars <dbl> 2
## $ Garage_Area <dbl> 420
## $ Garage_Cond <fct> Typical
## $ Paved_Drive <fct> Paved
## $ Wood_Deck_SF <int> 0
## $ Open_Porch_SF <int> 0
## $ Enclosed_Porch <int> 0
## $ Three_season_porch <int> 0
## $ Screen_Porch <int> 0
## $ Pool_Area <int> 0
## $ Pool_QC <fct> No_Pool
## $ Fence <fct> No_Fence
## $ Misc_Feature <fct> None
## $ Misc_Val <int> 0
## $ Mo_Sold <int> 6
## $ Year_Sold <int> 2009
## $ Sale_Type <fct> WD
## $ Sale_Condition <fct> Normal
## $ Sale_Price <int> 90000
## $ Longitude <dbl> -93.6089
## $ Latitude <dbl> 42.03584Existen múltiples enfoques para comprender por qué un modelo predice un precio determinado para esta casa dúplex.
Una se denomina explicación de “desglose” y calcula cómo las contribuciones atribuidas a características individuales cambian la predicción del modelo medio para una observación en particular, como nuestro dúplex.
Para el modelo lide bosques aleatorios, las variables Total_Bsmt_SF, Gr_Liv_Area y BsmtFin_Type_1 son las que más contribuyen a que el precio baje desde la intercepción.
xgb_breakdown <- predict_parts(explainer = explainer_xgb, new_observation = duplex)
xgb_breakdown %>% saveRDS("models/xgb_breakdown.rds")xgb_breakdown <- readRDS('models/xgb_breakdown.rds')¡¡ TEORÍA !!
La idea detrás de Shapley Additive Explanations (Lundberg y Lee 2017), es que las contribuciones promedio de las características se calculan bajo diferentes combinaciones o “coaliciones” de ordenamientos de características.
Calculemos las atribuciones SHAP para nuestra dúplex, usando B = 20 ordenaciones aleatorias.
set.seed(1801)
shap_duplex <- predict_parts(
explainer = explainer_xgb,
new_observation = duplex,
type = "shap",
B = 20
)
shap_duplex %>% saveRDS('models/shap_duplex.rds')Los diagramas de caja de la figura siguiente muestran la distribución de las contribuciones en todos los ordenamientos que probamos, y las barras muestran la atribución promedio para cada variable.
shap_duplex <- readRDS('models/shap_duplex.rds')
shap_duplex2 <- shap_duplex %>%
as_tibble() %>%
dplyr::filter(contribution !=0) %>%
dplyr::arrange(desc(abs(contribution)))
shap_duplex2 %>%
group_by(variable) %>%
mutate(mean_val = mean(contribution)) %>%
ungroup() %>%
mutate(variable = fct_reorder(variable, abs(mean_val))) %>%
ggplot(aes(contribution, variable, fill = mean_val > 0)) +
geom_col(data = ~distinct(., variable, mean_val),
aes(mean_val, variable),
alpha = 0.5) +
geom_boxplot(width = 0.5) +
scale_fill_viridis_d() +
theme(legend.position = "none") +
labs(y = NULL)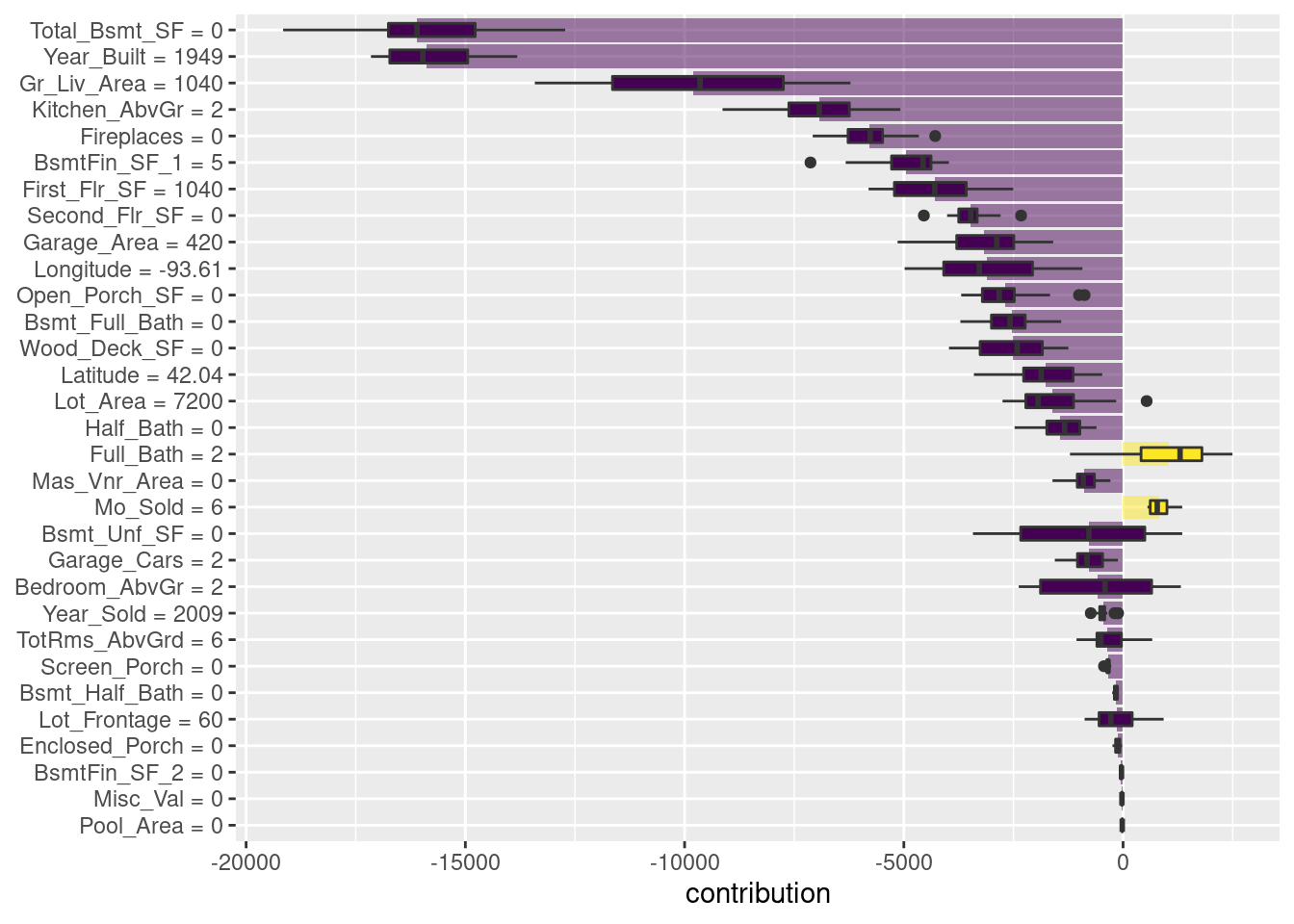
¿Qué pasa con una observación diferente en nuestro conjunto de datos? Veamos una casa unifamiliar más grande y nueva en el vecindario de Gilbert.
big_house <- ames_train[1671,]
big_house %>% glimpse()## Rows: 1
## Columns: 74
## $ MS_SubClass <fct> Two_Story_1946_and_Newer
## $ MS_Zoning <fct> Residential_Low_Density
## $ Lot_Frontage <dbl> 0
## $ Lot_Area <int> 8068
## $ Street <fct> Pave
## $ Alley <fct> No_Alley_Access
## $ Lot_Shape <fct> Slightly_Irregular
## $ Land_Contour <fct> Lvl
## $ Utilities <fct> AllPub
## $ Lot_Config <fct> Inside
## $ Land_Slope <fct> Gtl
## $ Neighborhood <fct> Gilbert
## $ Condition_1 <fct> Norm
## $ Condition_2 <fct> Norm
## $ Bldg_Type <fct> OneFam
## $ House_Style <fct> Two_Story
## $ Overall_Cond <fct> Average
## $ Year_Built <int> 2002
## $ Year_Remod_Add <int> 2002
## $ Roof_Style <fct> Gable
## $ Roof_Matl <fct> CompShg
## $ Exterior_1st <fct> VinylSd
## $ Exterior_2nd <fct> VinylSd
## $ Mas_Vnr_Type <fct> None
## $ Mas_Vnr_Area <dbl> 0
## $ Exter_Cond <fct> Typical
## $ Foundation <fct> PConc
## $ Bsmt_Cond <fct> Typical
## $ Bsmt_Exposure <fct> No
## $ BsmtFin_Type_1 <fct> Unf
## $ BsmtFin_SF_1 <dbl> 7
## $ BsmtFin_Type_2 <fct> Unf
## $ BsmtFin_SF_2 <dbl> 0
## $ Bsmt_Unf_SF <dbl> 1010
## $ Total_Bsmt_SF <dbl> 1010
## $ Heating <fct> GasA
## $ Heating_QC <fct> Excellent
## $ Central_Air <fct> Y
## $ Electrical <fct> SBrkr
## $ First_Flr_SF <int> 1010
## $ Second_Flr_SF <int> 1257
## $ Gr_Liv_Area <int> 2267
## $ Bsmt_Full_Bath <dbl> 0
## $ Bsmt_Half_Bath <dbl> 0
## $ Full_Bath <int> 2
## $ Half_Bath <int> 1
## $ Bedroom_AbvGr <int> 4
## $ Kitchen_AbvGr <int> 1
## $ TotRms_AbvGrd <int> 8
## $ Functional <fct> Typ
## $ Fireplaces <int> 1
## $ Garage_Type <fct> BuiltIn
## $ Garage_Finish <fct> RFn
## $ Garage_Cars <dbl> 2
## $ Garage_Area <dbl> 390
## $ Garage_Cond <fct> Typical
## $ Paved_Drive <fct> Paved
## $ Wood_Deck_SF <int> 120
## $ Open_Porch_SF <int> 46
## $ Enclosed_Porch <int> 0
## $ Three_season_porch <int> 0
## $ Screen_Porch <int> 0
## $ Pool_Area <int> 0
## $ Pool_QC <fct> No_Pool
## $ Fence <fct> No_Fence
## $ Misc_Feature <fct> None
## $ Misc_Val <int> 0
## $ Mo_Sold <int> 12
## $ Year_Sold <int> 2009
## $ Sale_Type <fct> ConLI
## $ Sale_Condition <fct> Normal
## $ Sale_Price <int> 200000
## $ Longitude <dbl> -93.64331
## $ Latitude <dbl> 42.05938Calculamos las atribuciones promedio SHAP de la misma manera.
set.seed(1802)
shap_house <- predict_parts(
explainer = explainer_xgb,
new_observation = big_house,
type = "shap",
B = 20
)
shap_house %>% saveRDS('models/shap_house.rds')shap_house <- readRDS('models/shap_house.rds')
shap_house2 <- shap_house %>%
as_tibble() %>%
dplyr::filter(contribution !=0) %>%
dplyr::arrange(desc(abs(contribution)))
shap_house2 %>%
group_by(variable) %>%
mutate(mean_val = mean(contribution)) %>%
ungroup() %>%
mutate(variable = fct_reorder(variable, abs(mean_val))) %>%
ggplot(aes(contribution, variable, fill = mean_val > 0)) +
geom_col(data = ~distinct(., variable, mean_val),
aes(mean_val, variable),
alpha = 0.5) +
geom_boxplot(width = 0.5) +
scale_fill_viridis_d() +
theme(legend.position = "none") +
labs(y = NULL)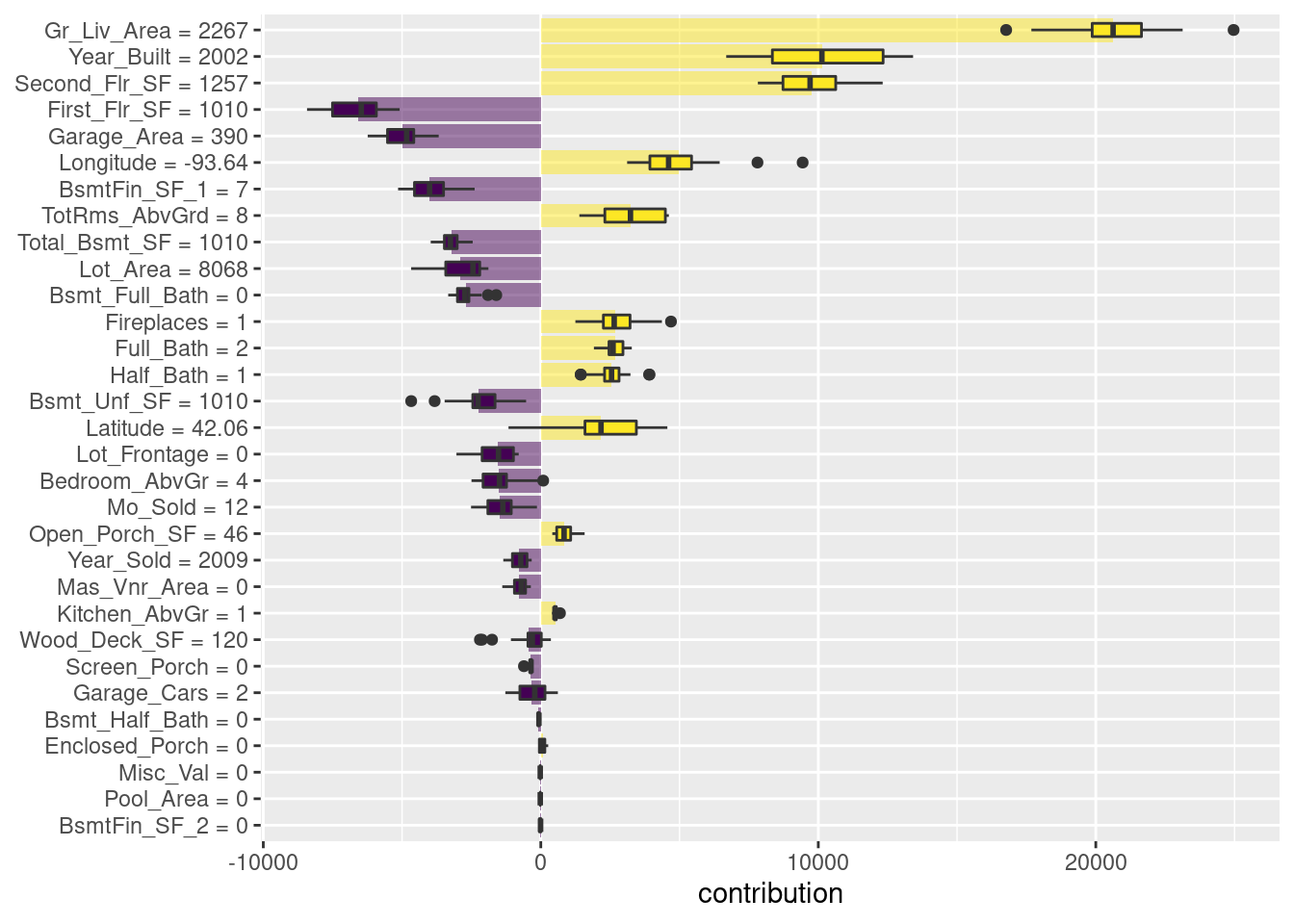
A diferencia del dúplex, el área habitable, año de construcción y área del segundo piso de esta casa contribuyen a que su precio sea más alto.
Los paquetes como DALEX y su paquete de soporte DALEXtra y lime se pueden integrar en un análisis de tidymodels para proporcionar este tipo de explicativos de modelos.
Las explicaciones del modelo son solo una parte de la comprensión de si su modelo es apropiado y efectivo, junto con las estimaciones del rendimiento del modelo.
7.2.1 Otros métodos
Partial Dependence Plot (PDP). Efecto marginal de una o dos variables en la predicción.
Accumulated Local Effects (ALE). Cómo las variables influyen en promedio a la predicción.
7.2.2 Consejos
Trata cada modelo que desarrollas como una afectación de vida o muerte a un humano directamente.
Identifica si estas agregando sesgo, inequidad, injusticia con interpretabilidad.
Siempre que tengas un modelo de aprendizaje supervisado genera interpretabilidad en tu proceso de desarrollo.
Siempre que tengas un modelo de aprendizaje supervisado genera interpretabilidad para el usuario final.
