Capítulo 8 Árboles de decisión
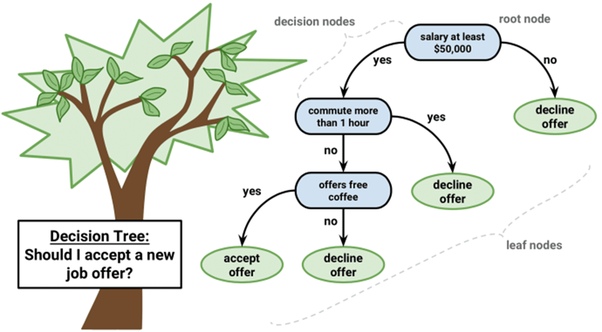
Un árbol de decisiones es un algoritmo del aprendizaje supervisado que se puede utilizar tanto para problemas de clasificación como de regresión. Es un clasificador estructurado en árbol, donde los nodos internos representan las características de un conjunto de datos, las ramas representan las reglas de decisión y cada nodo hoja representa el resultado. La idea básica de los árboles es buscar puntos de cortes en las variables de entrada para hacer predicciones, ir dividiendo la muestra, y encontrar cortes sucesivos para refinar las predicciones.
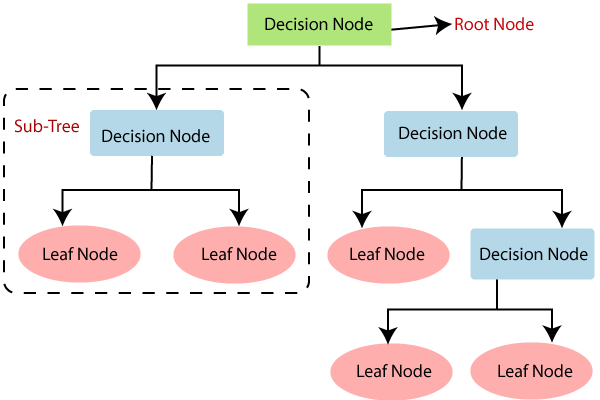
En un árbol de decisión, hay dos tipos nodos, el nodo de decisión o nodos internos (Decision Node) y el nodo hoja o nodo terminal (Leaf node). Los nodos de decisión se utilizan para tomar cualquier decisión y tienen múltiples ramas, mientras que los nodos hoja son el resultado de esas decisiones y no contienen más ramas.
- Regresión: En el caso de la regresión de árboles de decisión, en los nodos finales se calcula el promedio de la variable de respuesta. El promedio será la estimación del modelo.
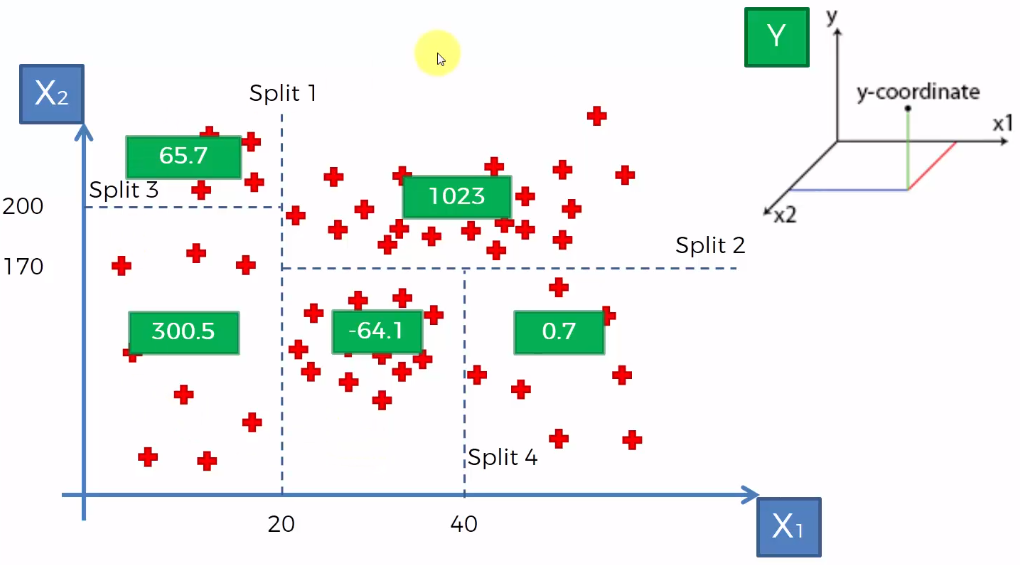
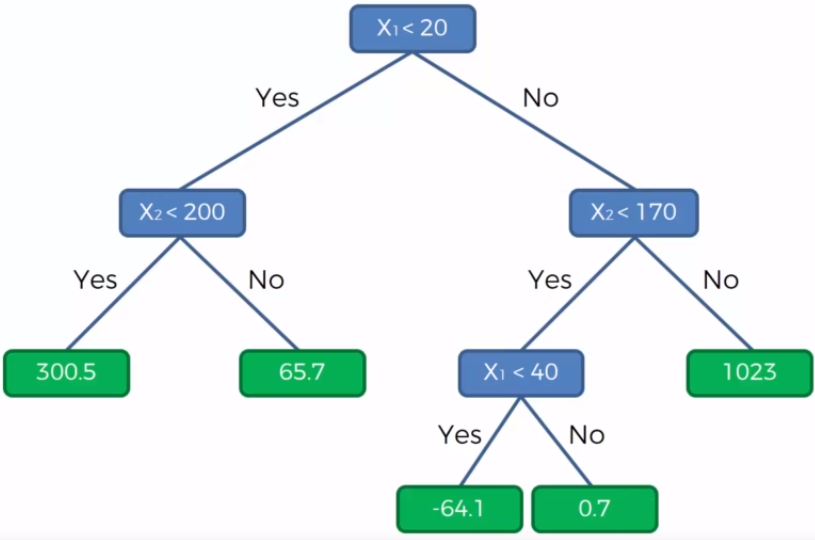
- Clasificación: Por otro lado, en los árboles de clasificación se calcula la proporción de elementos de cada categoría en los nodos finales. De esta manera se calcula la probabilidad de pertenencia a la categoría.
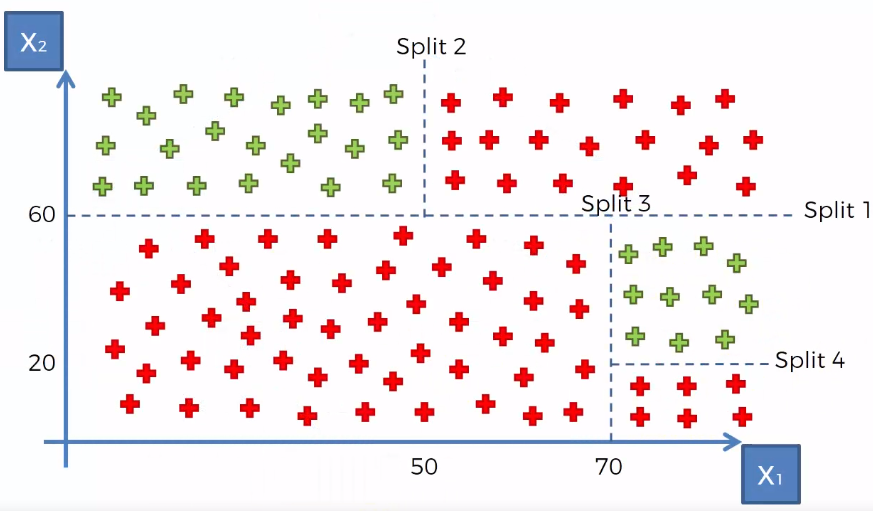
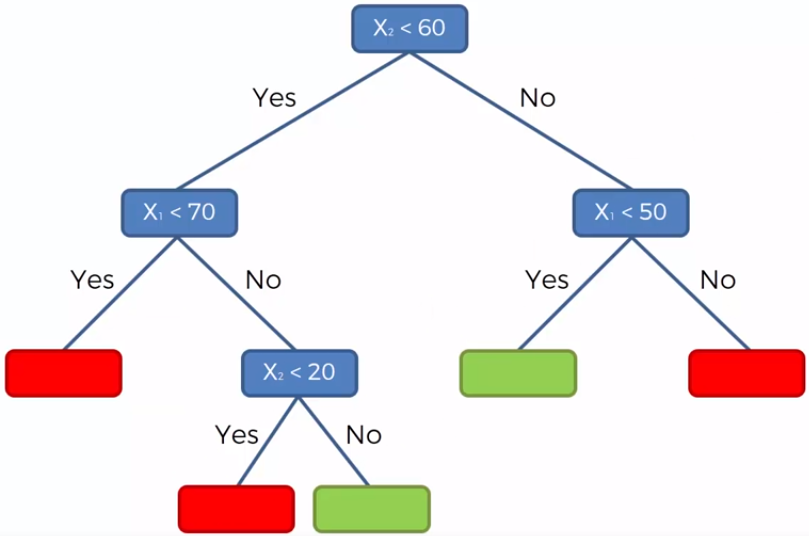
8.1 Ajuste del modelo
En un árbol de decisión, para predecir la clase del conjunto de datos, el algoritmo comienza desde el nodo raíz del árbol. Este algoritmo compara los valores de la variable raíz con la variable de registro y, según la comparación, sigue una rama y salta al siguiente nodo.
Para el siguiente nodo, el algoritmo vuelve a comparar el valor de la siguiente variable con los otros sub-nodos y avanza. Continúa el proceso hasta que se llega a un nodo hoja. El proceso completo se puede comprender mejor con los siguientes pasos:
Comenzamos el árbol con el nodo raíz (llamado S), que contiene el conjunto de entrenamiento completo.
Encuentre la mejor variable en el conjunto de datos usando Attribute Selective Measure (ASM).
Divida la S en subconjuntos que contengan valores posibles para la mejor variable.
Genere el nodo del árbol de decisión, que contiene la mejor variable.
Cree de forma recursiva nuevos árboles de decisión utilizando los subconjuntos del conjunto de datos creado en el paso 3. Continúe este proceso hasta que se alcance una etapa en la que no pueda particionar más los nodos y este nodo final sera un nodo hoja.
Para clasificación nos quedaremos la moda de la variable respuesta del nodo hoja y para regresión usaremos la media de la variable respuesta.
8.1.1 Attribute Selective Measure (ASM)
Al implementar un árbol de decisión, surge el problema principal de cómo seleccionar la mejor variable para el nodo raíz y para los sub-nodos. Para resolver este problemas existe una técnica que se llama medida de selección de atributos o ASM. Mediante esta medición, podemos seleccionar fácilmente la mejor variable para los nodos del árbol. Una de las técnicas más populares para ASM es:
- Índice de Gini
La medida del grado de probabilidad de que una variable en particular se clasifique incorrectamente cuando se elige al azar se llama índice de Gini o impureza de Gini. Los datos se distribuyen por igual según el índice de Gini.
\[Gini = \sum_{i=1}^{n}\hat{p_i}(1-\hat{p}_i)\]
Con \(p_i\) como la probabilidad de que un objeto se clasifique en una clase particular.
Esta métrica puede analizarse como una métrica de impureza. Cuando todos o la mayoría de elementos dentro de un nodo pertenecen a una misma clase, el índice de Gini toma valores cercanos a cero.
Cuando se utiliza el índice de Gini como criterio seleccionar la variable para el nodo raíz, seleccionaremos la variable con el índice de Gini menor.
8.2 Regularización de árboles
Para asegurarse de que no exista sobre-ajuste en el modelo, es importante considerar algunas regularizaciones a los hiper-parámetros implementados. Posteriormente, se determinará cuál de las posibles combinaciones produce mejores resultados.
8.2.1 Nivel de profundidad de árbol
Podríamos preguntarnos cuándo dejar de crecer un árbol. Pueden existir problemas que tengan un gran conjunto de variables y esto da como resultado una gran cantidad de divisiones, lo que a su vez genera un árbol de decisión muy grande. Estos árboles son complejos y pueden provocar un sobre-ajuste. Entonces, necesitamos saber cuándo parar.
Una forma de hacer esto, es establecer un número mínimo de entradas de entrenamiento para dividir un nodo (min_n).
Otra forma, es establecer la profundidad máxima del modelo. La profundidad máxima se refiere a la longitud del camino más largo desde el nodo raíz hasta un nodo hoja (max_depth).
8.3 Aprendizaje conjunto
El aprendizaje conjunto da crédito a la idea de la “sabiduría de las multitudes”, lo que sugiere que la toma de decisiones de un grupo más grande de individuos (modelos) suele ser mejor que la de un individuo.
El aprendizaje en conjunto es un grupo (o conjunto) de individuos o modelos, que trabajan colectivamente para lograr una mejor predicción final. Un solo modelo, también conocido como aprendiz básico puede no funcionar bien individualmente debido a una gran variación o un alto sesgo, sin embargo, cuando se agregan individuos débiles, pueden formar un individuo fuerte, ya que su combinación reduce el sesgo o la varianza, lo que produce un mejor rendimiento del modelo.

Los métodos de conjunto se ilustran con frecuencia utilizando árboles de decisión, ya que este algoritmo puede ser propenso a sobre ajustar (alta varianza y bajo sesgo) y también puede prestarse a desajuste (baja varianza y alto sesgo) cuando es muy pequeño, como un árbol de decisión con un nivel.
Nota: Cuando un algoritmo se adapta o no se adapta a su conjunto de entrenamiento, no se puede generalizar bien a nuevos conjuntos de datos, por lo que se utilizan métodos de conjunto para contrarrestar este comportamiento y permitir la generalización del modelo a nuevos conjuntos de datos.
8.4 Bagging
Primero tenemos que definir qué es la Agregación de Bootstrap o Bagging. Este es un algoritmo de aprendizaje automático diseñado para mejorar la estabilidad y precisión de algoritmos de ML usados en clasificación estadística y regresión. Además reduce la varianza y ayuda a evitar el sobre-ajuste. Aunque es usualmente aplicado a métodos de árboles de decisión, puede ser usado con cualquier tipo de método. Bagging es un caso especial del promediado de modelos.

Los métodos de bagging son métodos donde los algoritmos simples son usados en paralelo. El principal objetivo de los métodos en paralelo es el de aprovecharse de la independencia que hay entre los algoritmos simples, ya que el error se puede reducir bastante al promediar las salidas de los modelos simples. Es como si, queriendo resolver un problema entre varias personas independientes unas de otras, damos por bueno lo que eligiese la mayoría de las personas.
Para obtener la agregación de las salidas de cada modelo simple e independiente, bagging puede usar la votación para los métodos de clasificación y el promedio para los métodos de regresión.
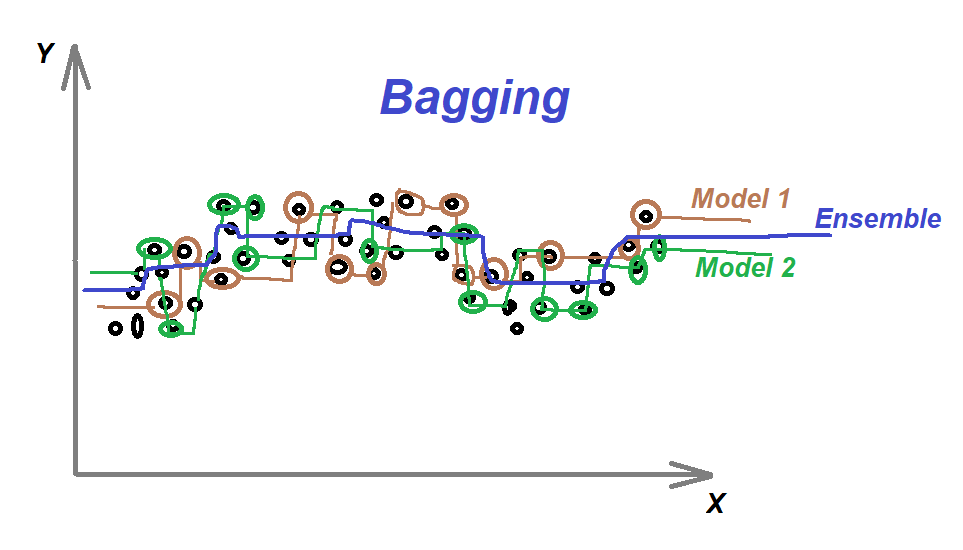
El bagging o agregación bootstrap, es un método de aprendizaje por conjuntos que se usa comúnmente para reducir la varianza dentro de un conjunto de datos ruidoso.
8.5 Random Forest
Un bosque aleatorio es un algoritmo de aprendizaje automático supervisado que se construye a partir de algoritmos de árbol de decisión. Este algoritmo se aplica en diversas industrias, como la banca y el comercio electrónico, para predecir el comportamiento y los resultados.
En esta clase se dará una descripción general del algoritmo de bosque aleatorio, cómo funciona y las características del algoritmo.
También se señalan las ventajas y desventajas de este algoritmo.
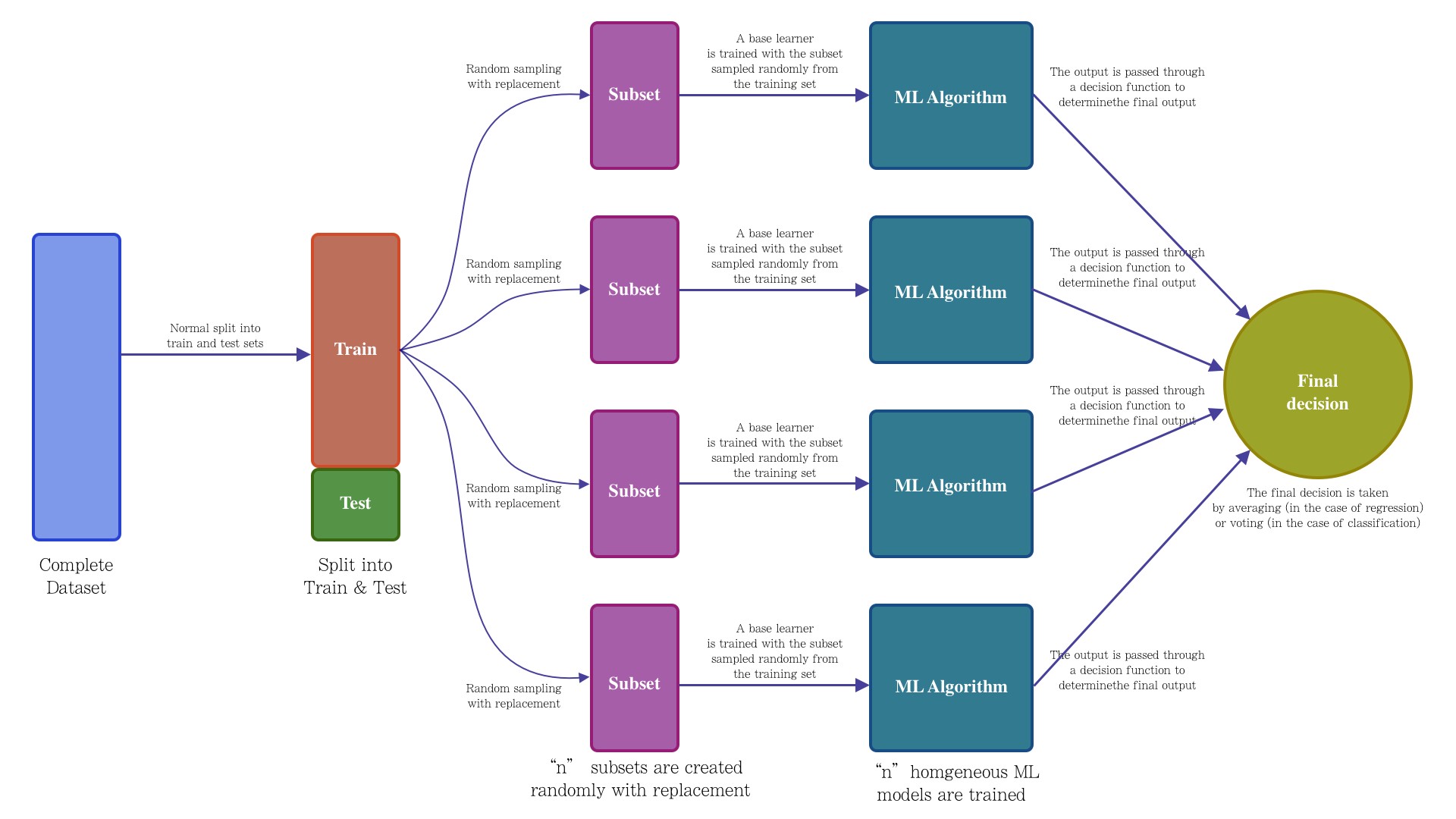
8.5.1 ¿Qué es?
Un bosque aleatorio es una técnica de aprendizaje automático que se utiliza para resolver problemas de regresión y clasificación. Utiliza el aprendizaje por conjuntos, que es una técnica que combina muchos clasificadores para proporcionar soluciones a problemas complejos.
Este algoritmo consta de muchos árboles de decisión. El “bosque” generado se entrena mediante agregación de bootstrap (bagging), el cual es es un meta-algoritmo de conjunto que mejora la precisión de los algoritmos de aprendizaje automático.
El algoritmo establece el resultado en función de las predicciones de los árboles de decisión. Predice tomando el promedio o la media de la salida de varios árboles. El aumento del número de árboles aumenta la precisión del resultado.
Un bosque aleatorio erradica las limitaciones de un algoritmo de árbol de decisión. Reduce el sobre-ajuste de conjuntos de datos y aumenta la precisión. Genera predicciones sin requerir muchas configuraciones.
8.5.2 Características de los bosques aleatorios
Es más preciso que el algoritmo árbol de decisiones.
Proporciona una forma eficaz de gestionar los datos faltantes.
Puede producir una predicción razonable sin ajuste de hiperparámetros.
Resuelve el problema del sobre-ajuste en los árboles de decisión.
En cada árbol forestal aleatorio, se selecciona aleatoriamente un subconjunto de características en el punto de división del nodo.
8.5.3 Aplicar árboles de decisión en un bosque aleatorio
La principal diferencia entre el algoritmo de árbol de decisión y el algoritmo de bosque aleatorio es que el establecimiento de nodos raíz y la desagregación de nodos se realiza de forma aleatoria en este último. El bosque aleatorio emplea el método de bagging para generar la predicción requerida.
El método bagging implica el uso de diferentes muestras de datos (datos de entrenamiento) en lugar de una sola muestra. Los árboles de decisión producen diferentes resultados, dependiendo de los datos de entrenamiento alimentados al algoritmo de bosque aleatorio.
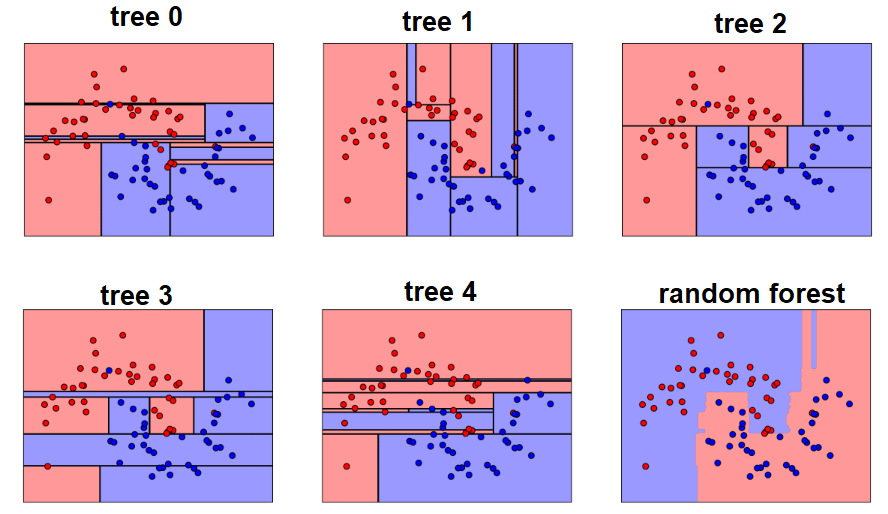
Nuestro primer ejemplo todavía se puede utilizar para explicar cómo funcionan los bosques aleatorios. Supongamos que solo tenemos cuatro árboles de decisión. En este caso, los datos de entrenamiento que comprenden las observaciones y características de estudio se dividirán en cuatro nodos raíz. Supongamos que queremos modelar si un cliente compra o no compra un teléfono.
Los nodos raíz podrían representar cuatro características que podrían influir en la elección de un cliente (precio, almacenamiento interno, cámara y RAM). El bosque aleatorio dividirá los nodos seleccionando características al azar. La predicción final se seleccionará en función del resultado de los cuatro árboles.
El resultado elegido por la mayoría de los árboles de decisión será la elección final.
Si tres árboles predicen la compra y un árbol predice que no comprará, entonces la predicción final será la compra. En este caso, se prevé que el cliente comprará.
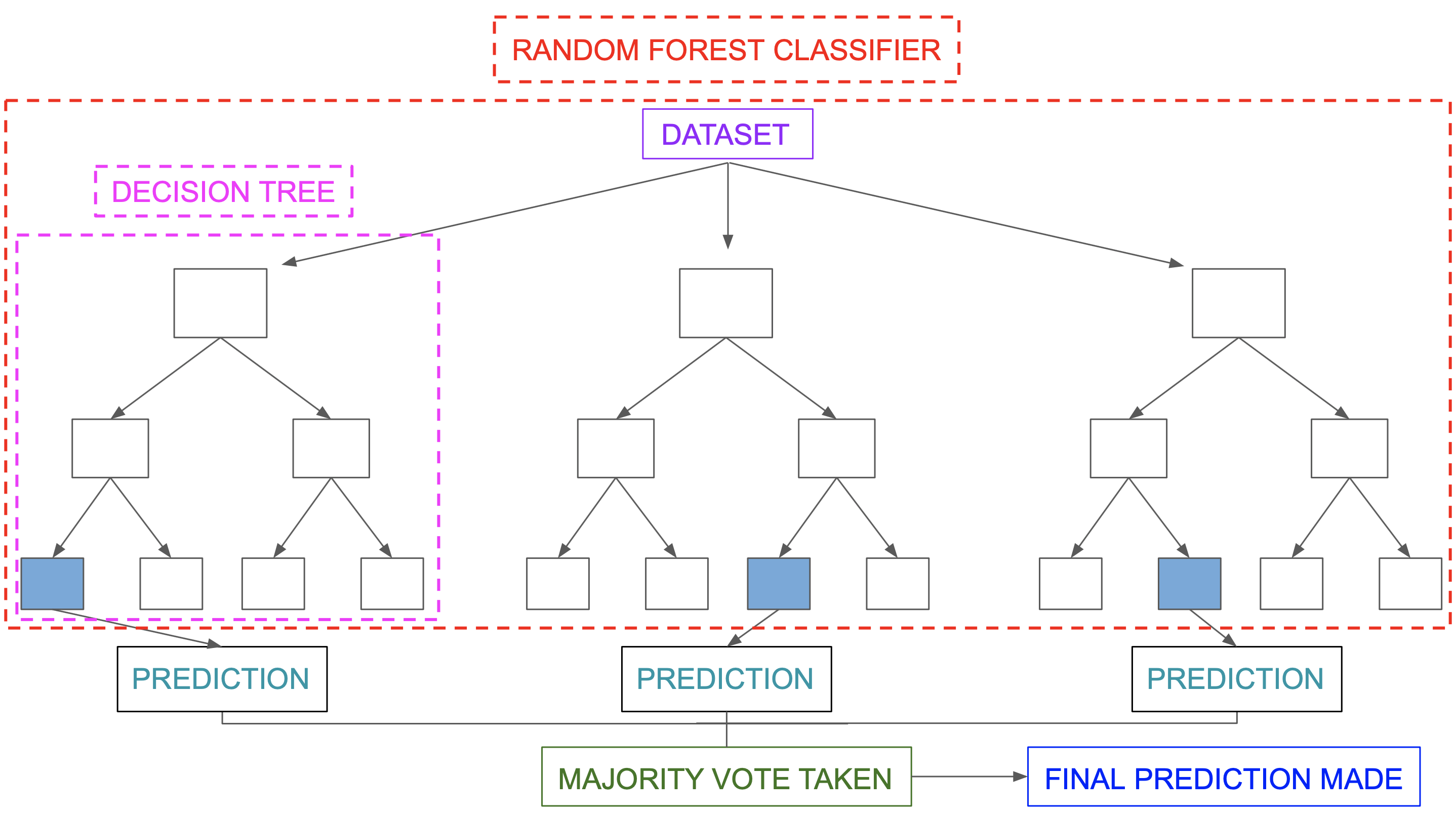
El siguiente diagrama muestra un clasificador de bosque aleatorio simple.
8.5.4 Ventajas y desventjas de bosques aleatorios
Ventajas
Puede realizar tareas de regresión y clasificación.
Un bosque aleatorio produce buenas predicciones que se pueden entender fácilmente.
Puede manejar grandes conjuntos de datos de manera eficiente.
Proporciona un mayor nivel de precisión en la predicción de resultados sobre el algoritmo del árbol de decisión.
Desventajas
Cuando se usa un bosque aleatorio, se requieren bastantes recursos para el cálculo.
Consume más tiempo en comparación con un algoritmo de árbol de decisiones.
No producen buenos resultados cuando los datos son muy escasos. En este caso, el subconjunto de características y la muestra de arranque producirán un espacio invariante. Esto conducirá a divisiones improductivas, que afectarán el resultado.
8.6 Implementación de RF en R
8.6.1 Regresión
Paso 1: Separación inicial de datos ( test, train
library(tidymodels)
data(ames)
set.seed(4595)
ames_split <- initial_split(ames, prop = 0.75)
ames_train <- training(ames_split)
ames_test <- testing(ames_split)
ames_folds <- vfold_cv(ames_train)Contando con datos de entrenamiento, procedemos a realizar el feature engineering para extraer las mejores características que permitirán realizar las estimaciones en el modelo.
Paso 2: Pre-procesamiento e ingeniería de variables
receta_casas <- recipe(
Sale_Price ~ Gr_Liv_Area + TotRms_AbvGrd + Exter_Cond + Bsmt_Cond +
Year_Sold + Year_Remod_Add,
data = ames_train) %>%
step_mutate(
Age_House = Year_Sold - Year_Remod_Add,
Exter_Cond = forcats::fct_collapse(Exter_Cond, Good = c("Typical", "Good", "Excellent"))) %>%
step_relevel(Exter_Cond, ref_level = "Good") %>%
step_normalize(all_numeric_predictors()) %>%
step_dummy(all_nominal_predictors()) %>%
step_interact(~ matches("Bsmt_Cond"):TotRms_AbvGrd)
receta_casasRecordemos que la función recipe() solo son los pasos a seguir, necesitamos usar la función prep() que nos devuelve una receta actualizada con las estimaciones y la función juice() que nos devuelve la matriz de diseño.
Una vez que la receta de transformación de datos está lista, procedemos a implementar el pipeline del modelo de interés.
Paso 3: Selección de tipo de modelo con hiperparámetros iniciales
# install.packages("ranger")
library(ranger)
rforest_model <- rand_forest(
mode = "regression",
trees = 1000,
mtry = tune(),
min_n = tune()) %>%
set_engine("ranger", importance = "impurity")Paso 4: Inicialización de workflow o pipeline
Paso 5: Creación de grid search
set.seed(195628)
rforest_param_grid <- grid_random(
mtry(range = c(2,15)),
min_n(range = c(2,16)),
size = 50
)
ctrl_grid <- control_grid(save_pred = T, verbose = T)Paso 6: Entrenamiento de modelos con hiperparámetros definidos
library(doParallel)
UseCores <- detectCores() - 1
cluster <- makeCluster(UseCores)
registerDoParallel(cluster)
# Ajuste de parámetros
rft1 <- Sys.time()
rforest_tune_result <- tune_grid(
rforest_workflow,
resamples = ames_folds,
grid = rforest_param_grid,
metrics = metric_set(rmse, rsq, mae),
control = ctrl_grid
)
rft2 <- Sys.time(); rft2 - rft1
stopCluster(cluster)
rforest_tune_result %>% saveRDS("models/random_forest_model_reg.rds")Paso 7: Análisis de métricas de error e hiperparámetros (Vuelve al paso 3, si es necesario)
Podemos obtener las métricas de cada fold con el siguiente código:
## # A tibble: 132 × 8
## mtry min_n .metric .estimator mean n std_err .config
## <int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 11 11 mae standard 28160. 10 560. Preprocessor1_Model…
## 2 11 11 rmse standard 42133. 10 1126. Preprocessor1_Model…
## 3 11 11 rsq standard 0.721 10 0.0116 Preprocessor1_Model…
## 4 11 13 mae standard 28139. 10 556. Preprocessor1_Model…
## 5 11 13 rmse standard 42183. 10 1118. Preprocessor1_Model…
## 6 11 13 rsq standard 0.720 10 0.0114 Preprocessor1_Model…
## 7 7 3 mae standard 28054. 10 576. Preprocessor1_Model…
## 8 7 3 rmse standard 41511. 10 1145. Preprocessor1_Model…
## 9 7 3 rsq standard 0.728 10 0.0115 Preprocessor1_Model…
## 10 9 16 mae standard 27991. 10 568. Preprocessor1_Model…
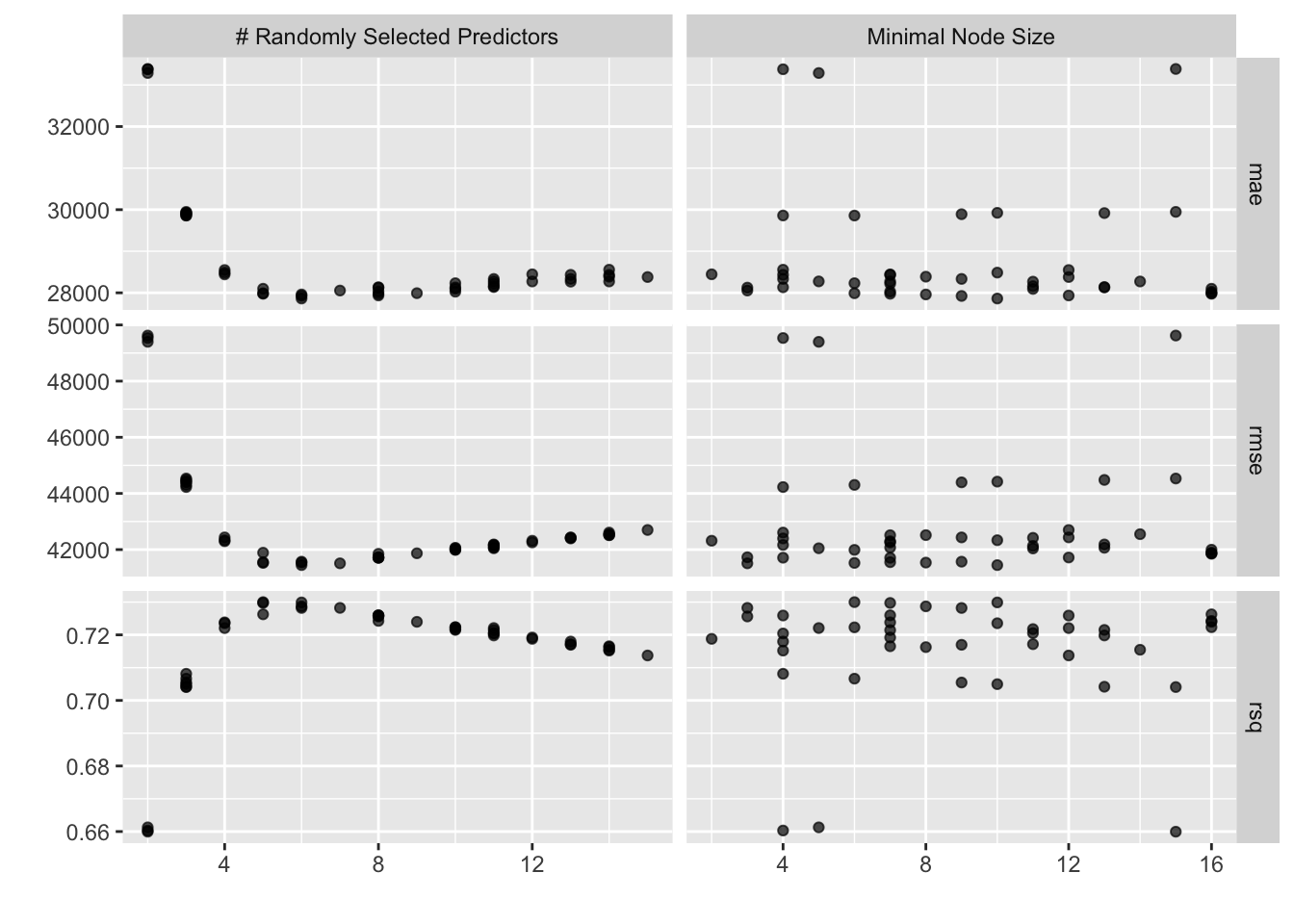
## # ℹ 122 more rowsEn la siguiente gráfica observamos las distintas métricas de error asociados a los hiperparámetros elegidos:
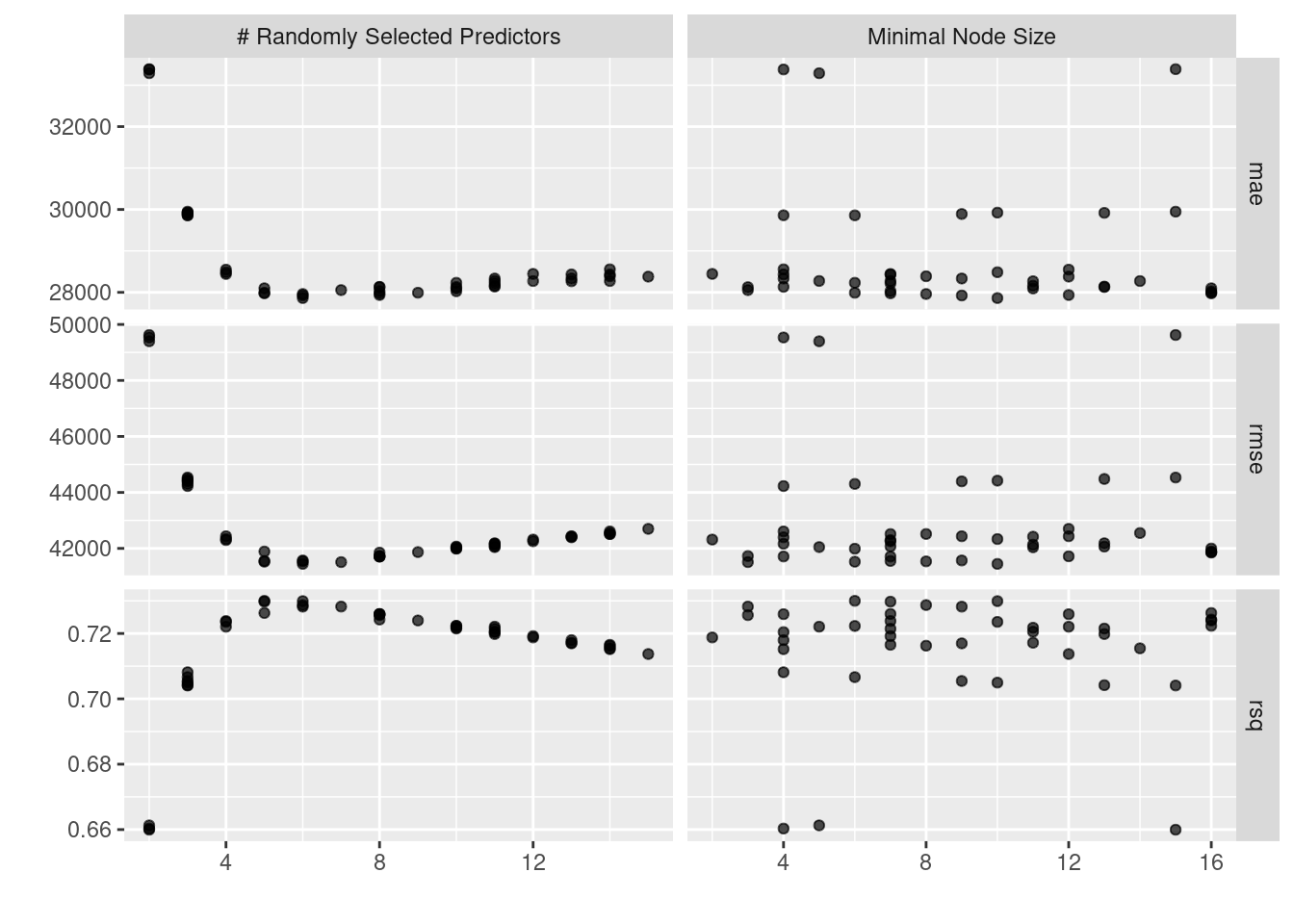
En la siguiente gráfica observamos el error cuadrático medio de las distintas métricas con distintos números de vecinos.
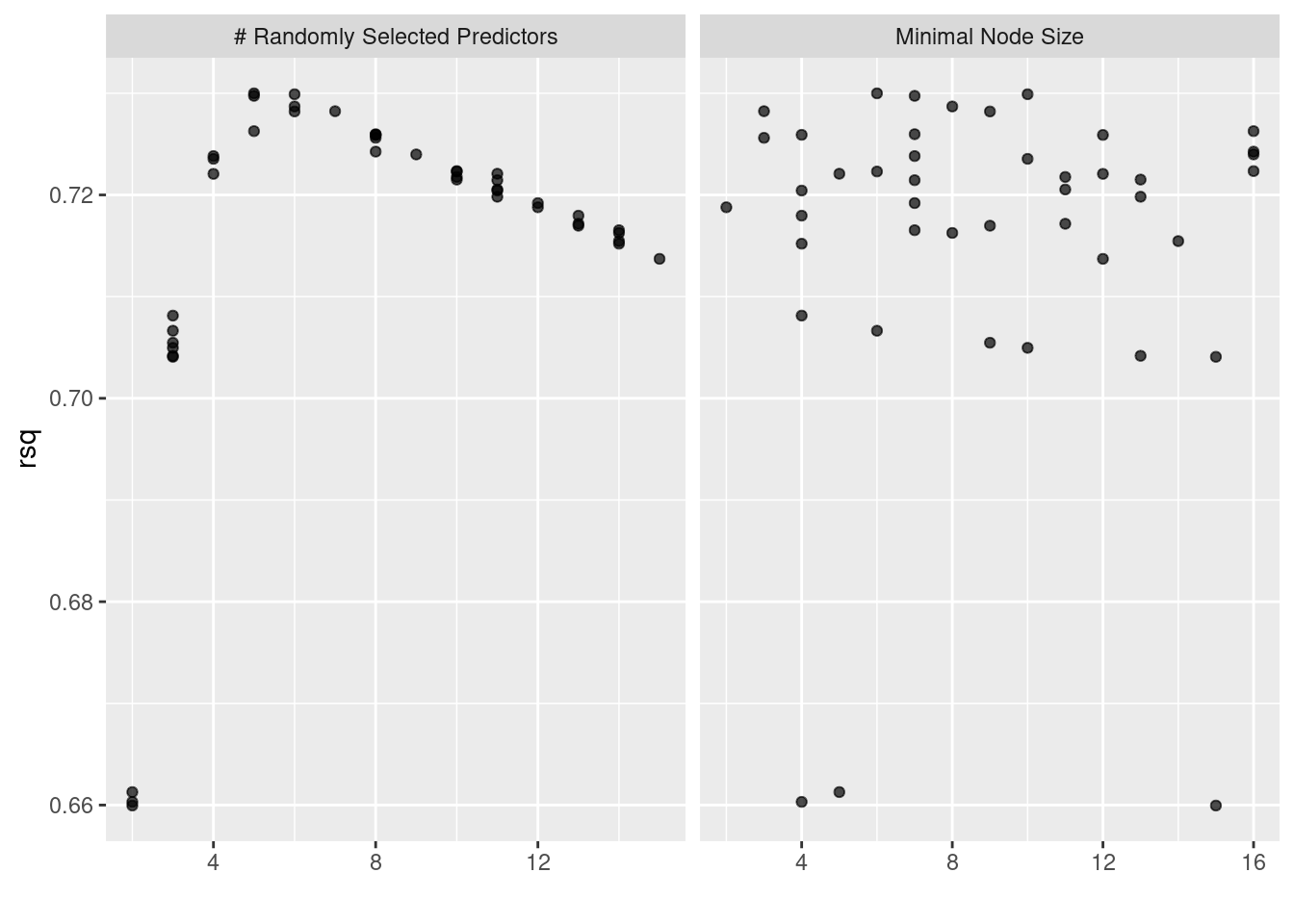
multiparams_plot <- rforest_tune_result %>%
collect_metrics() %>%
filter(.metric == "rmse") %>%
rename(rmse = mean) %>%
ggplot(aes(x = mtry, y = min_n, colour = rmse)) +
geom_point() +
scale_color_gradientn(colours = rainbow(7)) +
labs(
title = "Análisis de R^2 mediante ajuste de hiperparámetros",
x = "Número de ramas",
y = "Mínimo de elementos por nodo"
)
plotly::ggplotly(multiparams_plot)En la gráfica anterior, se aprecia la distribución conjunta de hiperparámetros y su resultados en la \(R^2\). De esta forma, se puede tomar una mejor decisión sobre el subconjunto óptimo de hiperparámetros a seleccionar.
Paso 8: Selección de modelo a usar
Con el siguiente código obtenemos los mejores 10 modelos respecto al rmse.
## # A tibble: 10 × 8
## mtry min_n .metric .estimator mean n std_err .config
## <int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 6 10 rmse standard 41447. 10 1156. Preprocessor1_Model07
## 2 7 3 rmse standard 41511. 10 1145. Preprocessor1_Model03
## 3 5 6 rmse standard 41525. 10 1259. Preprocessor1_Model14
## 4 6 8 rmse standard 41537. 10 1201. Preprocessor1_Model34
## 5 5 7 rmse standard 41551. 10 1259. Preprocessor1_Model31
## 6 6 9 rmse standard 41569. 10 1195. Preprocessor1_Model10
## 7 8 7 rmse standard 41708. 10 1151. Preprocessor1_Model18
## 8 8 4 rmse standard 41711. 10 1124. Preprocessor1_Model33
## 9 8 12 rmse standard 41718. 10 1138. Preprocessor1_Model22
## 10 8 3 rmse standard 41727. 10 1143. Preprocessor1_Model41Ahora obtendremos el modelo que mejor desempeño tiene tomando en cuenta el rmse y haremos las predicciones del conjunto de prueba con este modelo.
## # A tibble: 1 × 3
## mtry min_n .config
## <int> <int> <chr>
## 1 6 10 Preprocessor1_Model07Paso 9: Ajuste de modelo final con todos los datos (Vuelve al paso 2, si es necesario)
final_rforest_model <- rforest_workflow %>%
finalize_workflow(best_rforest_model) %>%
fit(data = ames_train)Este último objeto es el modelo final entrenado, el cual contiene toda la información del pre-procesamiento de datos, por lo que en caso de ponerse en producción el modelo, sólo se necesita de este último elemento para poder realizar nuevas predicciones.
Antes de pasar al siguiente paso, es importante validar que hayamos hecho un uso correcto de las variables predictivas. En este momento es posible detectar variables que no estén aportando valor o variables que no debiéramos estar usando debido a que cometeríamos data leakage. Para enfrentar esto, ayuda estimar y ordenar el valor de importancia de cada variable en el modelo.
library(vip)
final_rforest_model %>%
extract_fit_parsnip() %>%
vip(geom = "col") +
ggtitle("Importancia de las variables")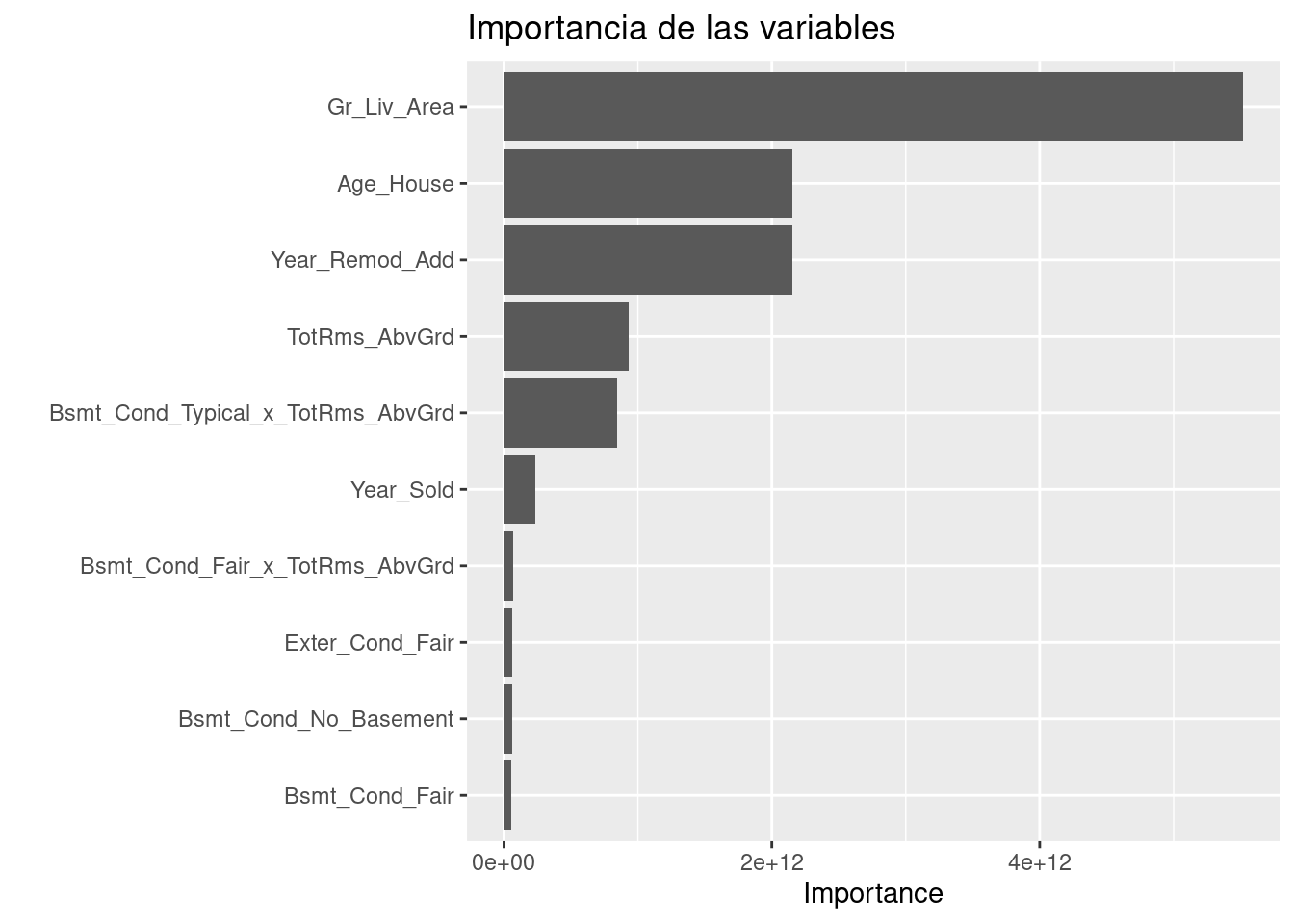
Paso 10: Validar poder predictivo con datos de prueba
Imaginemos por un momento que pasa un mes de tiempo desde que hicimos nuestro modelo, es hora de ponerlo a prueba prediciendo valores de nuevos elementos:
results <- predict(final_rforest_model, ames_test) %>%
dplyr::bind_cols(Sale_Price = ames_test$Sale_Price) %>%
dplyr::rename(pred_rforest_reg = .pred)
results## # A tibble: 733 × 2
## pred_rforest_reg Sale_Price
## <dbl> <int>
## 1 115025. 105000
## 2 163300. 185000
## 3 176940. 180400
## 4 99247. 141000
## 5 213379. 210000
## 6 202438. 216000
## 7 151681. 149900
## 8 123097. 105500
## 9 123097. 88000
## 10 155039. 146000
## # ℹ 723 more rowsMétricas de desempeño
Ahora para calcular las métricas de desempeño usaremos la paquetería MLmetrics. Es posible definir nuestro propio conjunto de métricas que deseamos reportar creando el objeto metric_set:
library(MLmetrics)
multi_metric <- metric_set(mae, mape, rmse, rsq, ccc)
multi_metric(results, truth = Sale_Price, estimate = pred_rforest_reg) %>%
mutate(.estimate = round(.estimate, 2)) %>%
select(-.estimator)## # A tibble: 5 × 2
## .metric .estimate
## <chr> <dbl>
## 1 mae 28822.
## 2 mape 17.0
## 3 rmse 42662.
## 4 rsq 0.72
## 5 ccc 0.83results %>%
ggplot(aes(x = pred_rforest_reg, y = Sale_Price)) +
geom_point() +
geom_abline(color = "red") +
xlab("Prediction") +
ylab("Observation") +
ggtitle("Comparisson")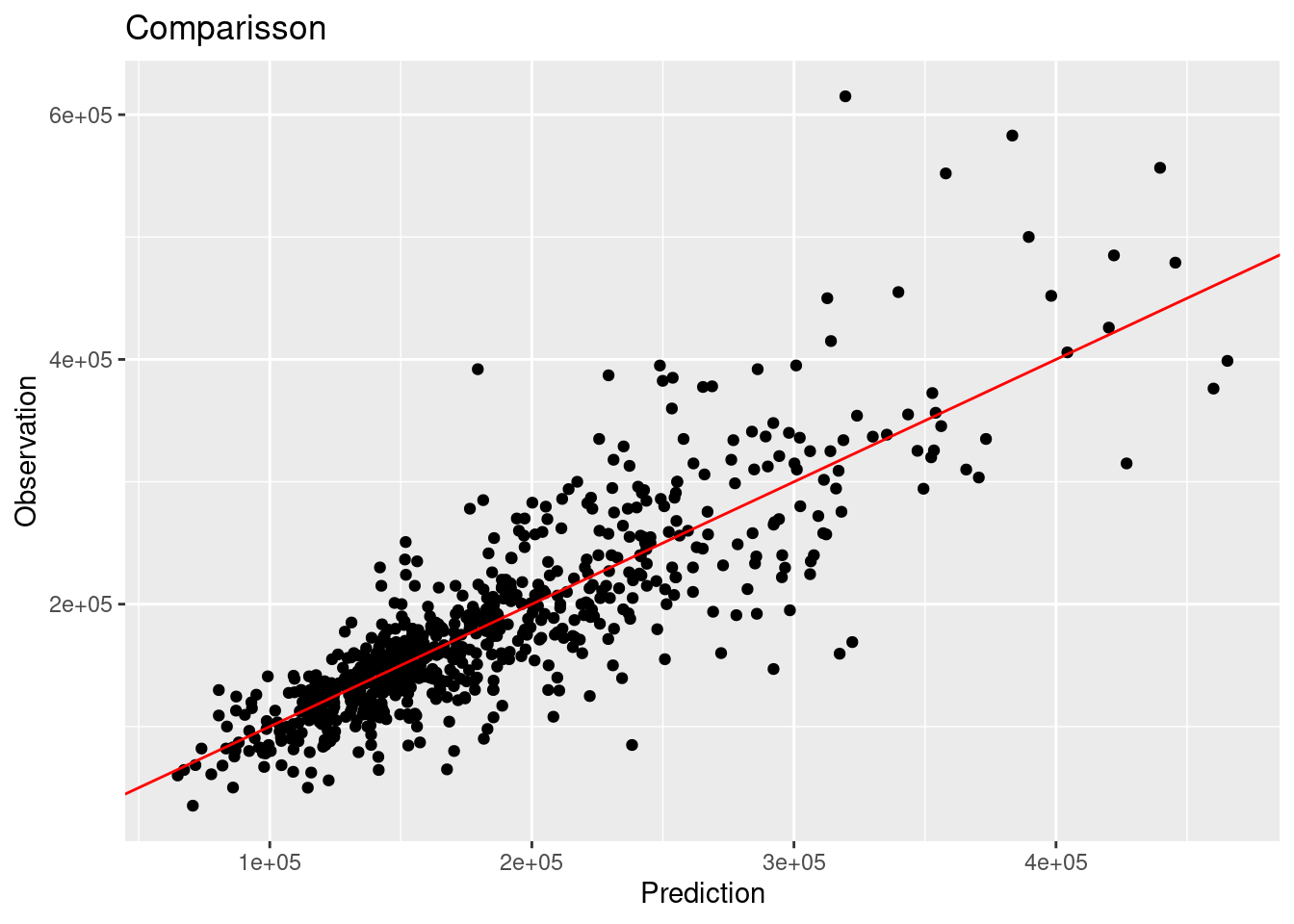
8.6.2 Clasificación
Es turno de revisar la implementación de Random Forest con nuestro bien conocido problema de predicción de cancelación de servicios de telecomunicaciones. Los datos se encuentran disponibles en el siguiente enlace:
Los pasos para implementar en R este modelo predictivo son los mismos, cambiando únicamente las especificaciones del tipo de modelo, pre-procesamiento e hiper-parámetros.
library(readr)
library(tidyverse)
library(tidymodels)
tidymodels_prefer()
telco <- read_csv("data/Churn.csv")
glimpse(telco)## Rows: 7,043
## Columns: 21
## $ customerID <chr> "7590-VHVEG", "5575-GNVDE", "3668-QPYBK", "7795-CFOCW…
## $ gender <chr> "Female", "Male", "Male", "Male", "Female", "Female",…
## $ SeniorCitizen <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ Partner <chr> "Yes", "No", "No", "No", "No", "No", "No", "No", "Yes…
## $ Dependents <chr> "No", "No", "No", "No", "No", "No", "Yes", "No", "No"…
## $ tenure <dbl> 1, 34, 2, 45, 2, 8, 22, 10, 28, 62, 13, 16, 58, 49, 2…
## $ PhoneService <chr> "No", "Yes", "Yes", "No", "Yes", "Yes", "Yes", "No", …
## $ MultipleLines <chr> "No phone service", "No", "No", "No phone service", "…
## $ InternetService <chr> "DSL", "DSL", "DSL", "DSL", "Fiber optic", "Fiber opt…
## $ OnlineSecurity <chr> "No", "Yes", "Yes", "Yes", "No", "No", "No", "Yes", "…
## $ OnlineBackup <chr> "Yes", "No", "Yes", "No", "No", "No", "Yes", "No", "N…
## $ DeviceProtection <chr> "No", "Yes", "No", "Yes", "No", "Yes", "No", "No", "Y…
## $ TechSupport <chr> "No", "No", "No", "Yes", "No", "No", "No", "No", "Yes…
## $ StreamingTV <chr> "No", "No", "No", "No", "No", "Yes", "Yes", "No", "Ye…
## $ StreamingMovies <chr> "No", "No", "No", "No", "No", "Yes", "No", "No", "Yes…
## $ Contract <chr> "Month-to-month", "One year", "Month-to-month", "One …
## $ PaperlessBilling <chr> "Yes", "No", "Yes", "No", "Yes", "Yes", "Yes", "No", …
## $ PaymentMethod <chr> "Electronic check", "Mailed check", "Mailed check", "…
## $ MonthlyCharges <dbl> 29.85, 56.95, 53.85, 42.30, 70.70, 99.65, 89.10, 29.7…
## $ TotalCharges <dbl> 29.85, 1889.50, 108.15, 1840.75, 151.65, 820.50, 1949…
## $ Churn <chr> "No", "No", "Yes", "No", "Yes", "Yes", "No", "No", "Y…Paso 1: Separación inicial de datos ( test, train
set.seed(1234)
telco_split <- initial_split(telco, prop = .70)
telco_train <- training(telco_split)
telco_test <- testing(telco_split)
telco_folds <- vfold_cv(telco_train)
telco_folds## # 10-fold cross-validation
## # A tibble: 10 × 2
## splits id
## <list> <chr>
## 1 <split [4437/493]> Fold01
## 2 <split [4437/493]> Fold02
## 3 <split [4437/493]> Fold03
## 4 <split [4437/493]> Fold04
## 5 <split [4437/493]> Fold05
## 6 <split [4437/493]> Fold06
## 7 <split [4437/493]> Fold07
## 8 <split [4437/493]> Fold08
## 9 <split [4437/493]> Fold09
## 10 <split [4437/493]> Fold10Paso 2: Pre-procesamiento e ingeniería de variables
telco_rec <- recipe(
Churn ~ customerID + TotalCharges + MonthlyCharges + SeniorCitizen + Contract,
data = telco_train) %>%
update_role(customerID, new_role = "id variable") %>%
step_mutate(Contract = as.factor(Contract)) %>%
step_impute_median(all_numeric_predictors()) %>%
step_normalize(all_numeric_predictors()) %>%
step_dummy(all_nominal_predictors())
telco_recPaso 3: Selección de tipo de modelo con hiperparámetros iniciales
rforest_model <- rand_forest(
mode = "classification",
trees = 1000,
mtry = tune(),
min_n = tune()) %>%
set_engine("ranger", importance = "impurity")
rforest_model## Random Forest Model Specification (classification)
##
## Main Arguments:
## mtry = tune()
## trees = 1000
## min_n = tune()
##
## Engine-Specific Arguments:
## importance = impurity
##
## Computational engine: rangerPaso 4: Inicialización de workflow o pipeline
rforest_workflow <- workflow() %>%
add_recipe(telco_rec) %>%
add_model(rforest_model)
rforest_workflow## ══ Workflow ══════════════════
## Preprocessor: Recipe
## Model: rand_forest()
##
## ── Preprocessor ──────────────
## 4 Recipe Steps
##
## • step_mutate()
## • step_impute_median()
## • step_normalize()
## • step_dummy()
##
## ── Model ─────────────────────
## Random Forest Model Specification (classification)
##
## Main Arguments:
## mtry = tune()
## trees = 1000
## min_n = tune()
##
## Engine-Specific Arguments:
## importance = impurity
##
## Computational engine: rangerPaso 5: Creación de grid search
set.seed(195628)
rforest_param_grid <- grid_random(
mtry(range = c(2,5)),
min_n(range = c(2,16)),
size = 20
)
ctrl_grid <- control_grid(save_pred = T, verbose = T)Paso 6: Entrenamiento de modelos con hiperparámetros definidos
library(doParallel)
UseCores <- detectCores() - 1
cluster <- makeCluster(UseCores)
registerDoParallel(cluster)
rft1 <- Sys.time()
rf_tune_result <- tune_grid(
rforest_workflow,
resamples = telco_folds,
grid = rforest_param_grid,
metrics = metric_set(roc_auc, pr_auc),
control = ctrl_grid
)
rft2 <- Sys.time(); rft2 - rft1
stopCluster(cluster)
rf_tune_result %>% saveRDS("models/rforest_model_cla.rds")Paso 7: Análisis de métricas de error e hiperparámetros (Vuelve al paso 3, si es necesario)
## # A tibble: 34 × 8
## mtry min_n .metric .estimator mean n std_err .config
## <int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 3 16 pr_auc binary 0.930 10 0.00372 Preprocessor1_Model01
## 2 3 16 roc_auc binary 0.825 10 0.00623 Preprocessor1_Model01
## 3 3 8 pr_auc binary 0.929 10 0.00385 Preprocessor1_Model02
## 4 3 8 roc_auc binary 0.822 10 0.00635 Preprocessor1_Model02
## 5 3 2 pr_auc binary 0.927 10 0.00378 Preprocessor1_Model03
## 6 3 2 roc_auc binary 0.818 10 0.00653 Preprocessor1_Model03
## 7 5 4 pr_auc binary 0.921 10 0.00359 Preprocessor1_Model04
## 8 5 4 roc_auc binary 0.802 10 0.00682 Preprocessor1_Model04
## 9 3 13 pr_auc binary 0.929 10 0.00397 Preprocessor1_Model05
## 10 3 13 roc_auc binary 0.824 10 0.00640 Preprocessor1_Model05
## # ℹ 24 more rowsEn la siguiente gráfica observamos las distintas métricas de error asociados a los hiperparámetros elegidos.
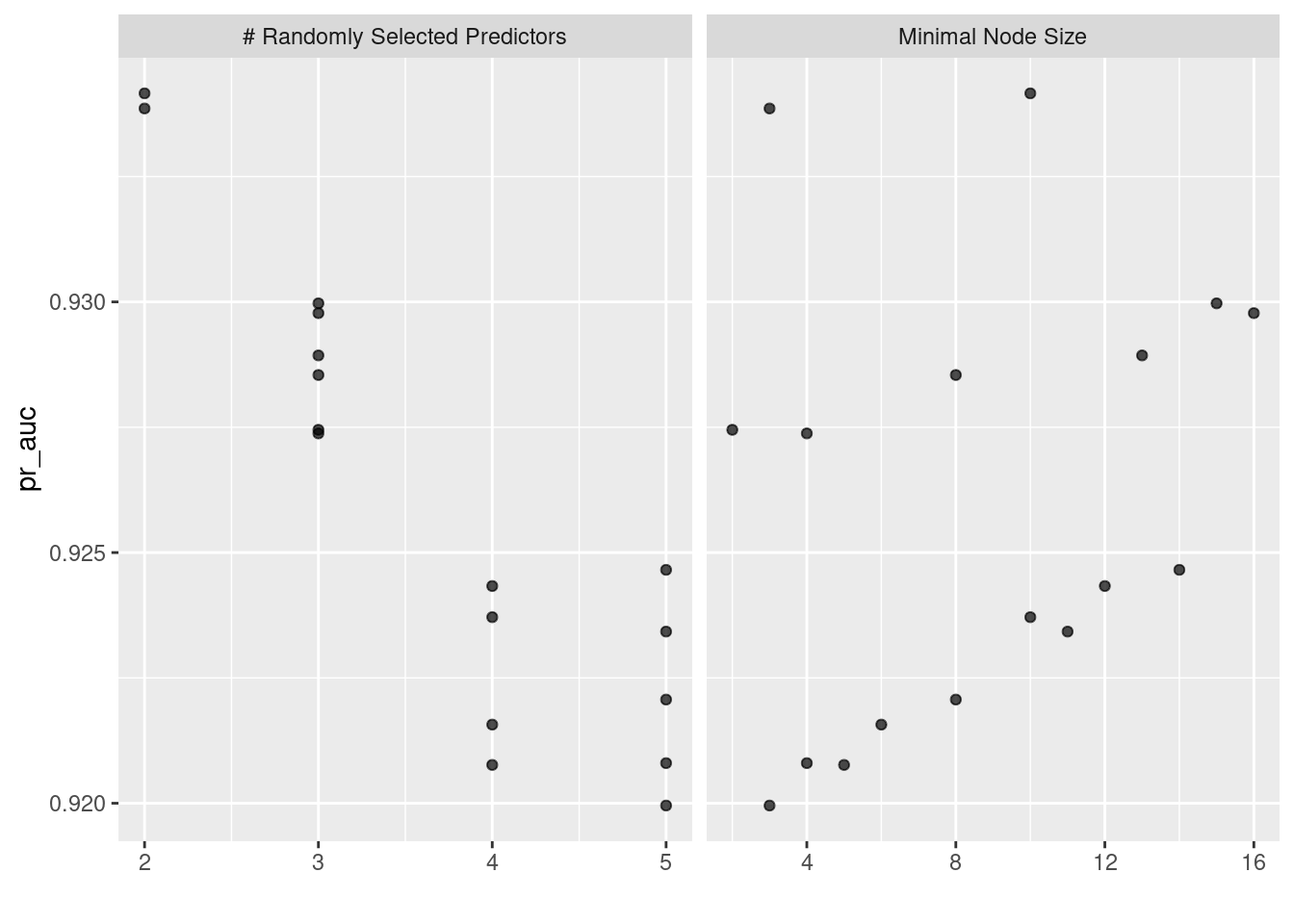
## # A tibble: 10 × 8
## mtry min_n .metric .estimator mean n std_err .config
## <int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 2 10 pr_auc binary 0.934 10 0.00363 Preprocessor1_Model08
## 2 2 3 pr_auc binary 0.934 10 0.00375 Preprocessor1_Model12
## 3 3 15 pr_auc binary 0.930 10 0.00374 Preprocessor1_Model09
## 4 3 16 pr_auc binary 0.930 10 0.00372 Preprocessor1_Model01
## 5 3 13 pr_auc binary 0.929 10 0.00397 Preprocessor1_Model05
## 6 3 8 pr_auc binary 0.929 10 0.00385 Preprocessor1_Model02
## 7 3 2 pr_auc binary 0.927 10 0.00378 Preprocessor1_Model03
## 8 3 4 pr_auc binary 0.927 10 0.00396 Preprocessor1_Model11
## 9 5 14 pr_auc binary 0.925 10 0.00353 Preprocessor1_Model10
## 10 4 12 pr_auc binary 0.924 10 0.00367 Preprocessor1_Model07Paso 8: Selección de modelo a usar
## # A tibble: 1 × 3
## mtry min_n .config
## <int> <int> <chr>
## 1 2 10 Preprocessor1_Model08rf_classification_best_1se_model <- rf_tune_result %>%
select_by_one_std_err(metric = "roc_auc", "roc_auc")
rf_classification_best_1se_model## # A tibble: 1 × 3
## mtry min_n .config
## <int> <int> <chr>
## 1 2 10 Preprocessor1_Model08Paso 9: Ajuste de modelo final con todos los datos (Vuelve al paso 2, si es necesario)
final_rf_model_cla <- rforest_workflow %>%
finalize_workflow(best_rf_model_cla) %>%
parsnip::fit(data = telco_train)Este último objeto es el modelo final entrenado, el cual contiene toda la información del pre-procesamiento de datos, por lo que en caso de ponerse en producción el modelo, sólo se necesita de este último elemento para poder realizar nuevas predicciones.
Antes de pasar al siguiente paso, es importante validar que hayamos hecho un uso correcto de las variables predictivas. En este momento es posible detectar variables que no estén aportando valor o variables que no debiéramos estar usando debido a que cometeríamos data leakage. Para enfrentar esto, ayuda estimar y ordenar el valor de importancia del modelo.
Después de entrenar un modelo, es natural preguntarse qué variables tienen el mayor poder predictivo. Las variables de gran importancia son impulsoras del resultado y sus valores tienen un impacto significativo en los valores del resultado. Por el contrario, las variables con poca importancia pueden omitirse de un modelo, lo que lo hace más simple y rápido de ajustar y predecir.
library(vip)
final_rf_model_cla %>%
extract_fit_parsnip() %>%
vip::vip() +
ggtitle("Importancia de las variables")+
theme_minimal()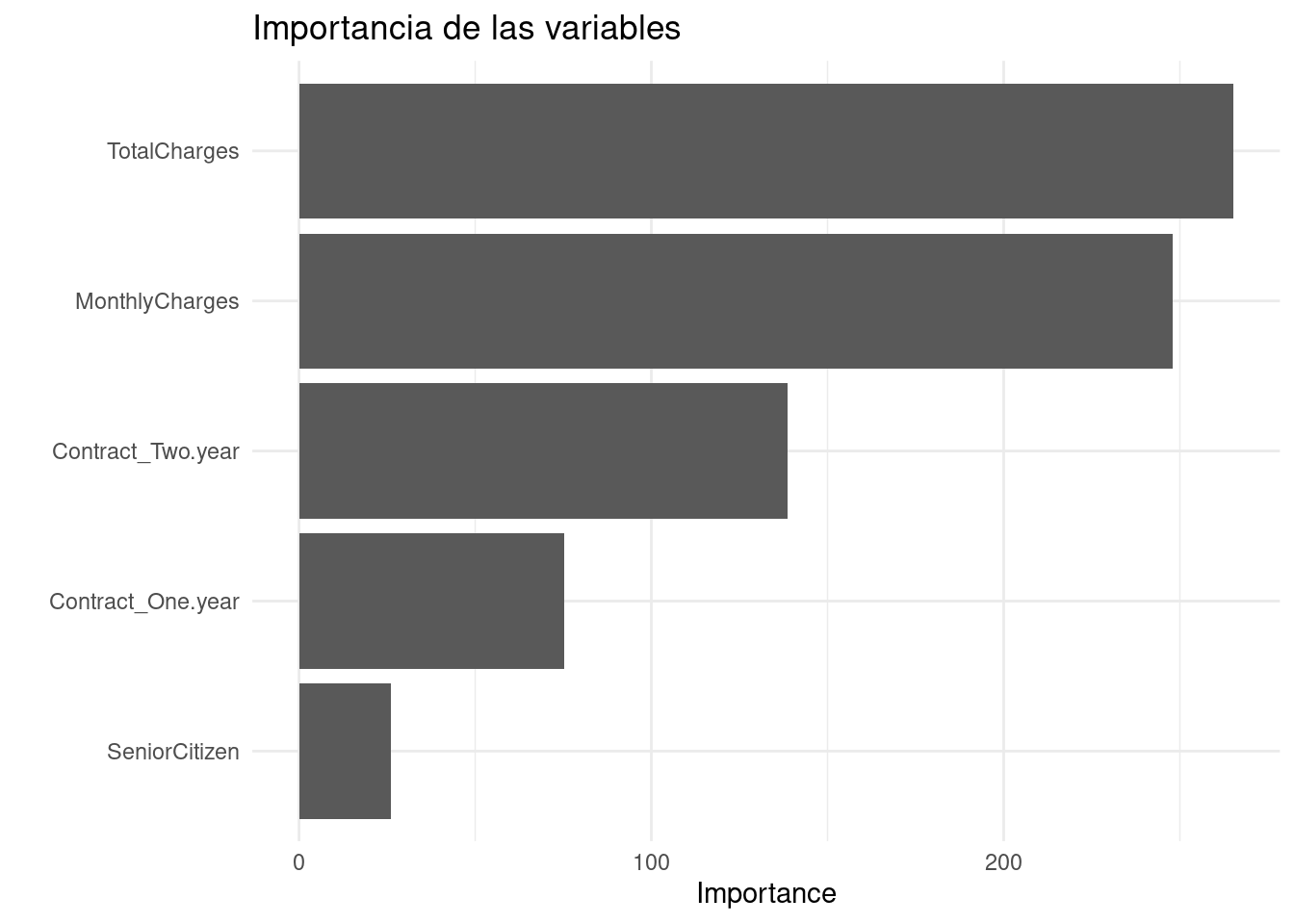
Paso 10: Validar poder predictivo con datos de prueba
Imaginemos por un momento que pasa un mes de tiempo desde que hicimos nuestro modelo, es hora de ponerlo a prueba prediciendo valores de nuevos elementos:
results_cla <- predict(final_rf_model_cla, telco_test, type = 'prob') %>%
dplyr::bind_cols(Churn = telco_test$Churn, .) %>%
mutate(Churn = factor(Churn, levels = c('Yes', 'No'), labels = c('Yes', 'No')))
results_cla## # A tibble: 2,113 × 3
## Churn .pred_No .pred_Yes
## <fct> <dbl> <dbl>
## 1 No 0.939 0.0611
## 2 Yes 0.378 0.622
## 3 No 0.641 0.359
## 4 No 0.987 0.0127
## 5 No 0.898 0.102
## 6 No 0.565 0.435
## 7 No 0.971 0.0290
## 8 No 0.788 0.212
## 9 Yes 0.556 0.444
## 10 No 0.982 0.0182
## # ℹ 2,103 more rowsbind_rows(
roc_auc(results_cla, truth = Churn, .pred_Yes),
pr_auc(results_cla, truth = Churn, .pred_Yes)
)## # A tibble: 2 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 roc_auc binary 0.837
## 2 pr_auc binary 0.644## # A tibble: 1,945 × 3
## .threshold recall precision
## <dbl> <dbl> <dbl>
## 1 Inf 0 1
## 2 0.853 0.00177 1
## 3 0.851 0.00353 1
## 4 0.850 0.00530 1
## 5 0.820 0.00707 1
## 6 0.819 0.00707 0.8
## 7 0.815 0.00883 0.833
## 8 0.810 0.0106 0.857
## 9 0.809 0.0124 0.875
## 10 0.804 0.0141 0.889
## # ℹ 1,935 more rows## # A tibble: 1,946 × 3
## .threshold specificity sensitivity
## <dbl> <dbl> <dbl>
## 1 -Inf 0 1
## 2 0.00596 0 1
## 3 0.00597 0.00646 1
## 4 0.00598 0.0116 1
## 5 0.00599 0.0155 1
## 6 0.00600 0.0252 1
## 7 0.00601 0.0265 1
## 8 0.00602 0.0271 1
## 9 0.00610 0.0278 1
## 10 0.00617 0.0284 1
## # ℹ 1,936 more rowspr_curve_plot <- pr_curve_data %>%
ggplot(aes(x = recall, y = precision)) +
geom_abline(slope = -1, intercept = 1) +
geom_path(size = 1, colour = 'lightblue') +
ylim(0, 1) +
coord_equal() +
ggtitle("Precision vs Recall")+
theme_minimal()
pr_curve_plot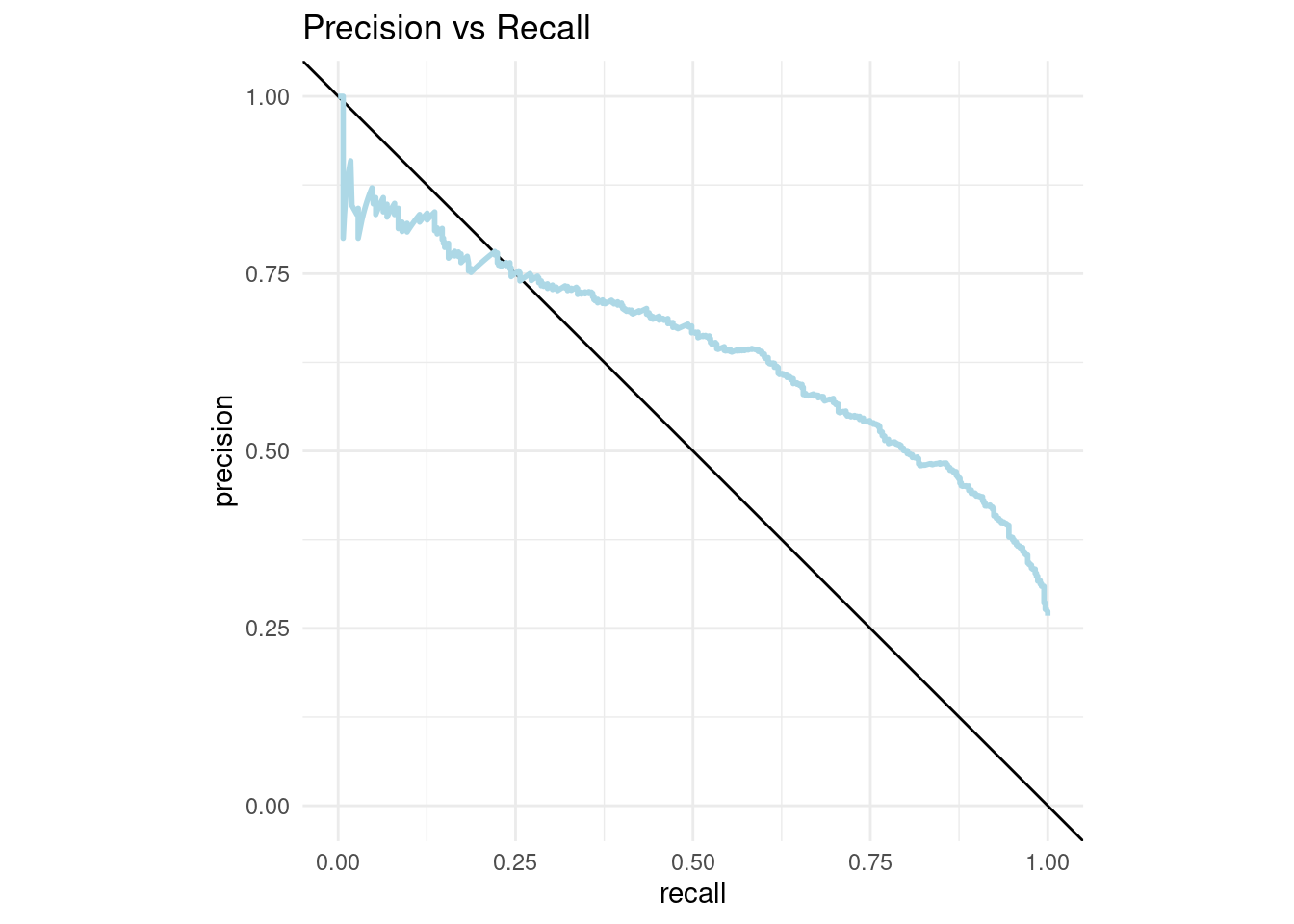
roc_curve_plot <- roc_curve_data %>%
ggplot(aes(x = 1 - specificity, y = sensitivity)) +
geom_path(size = 1, colour = 'lightblue') +
geom_abline() +
coord_equal() +
ggtitle("ROC Curve")+
theme_minimal()
roc_curve_plot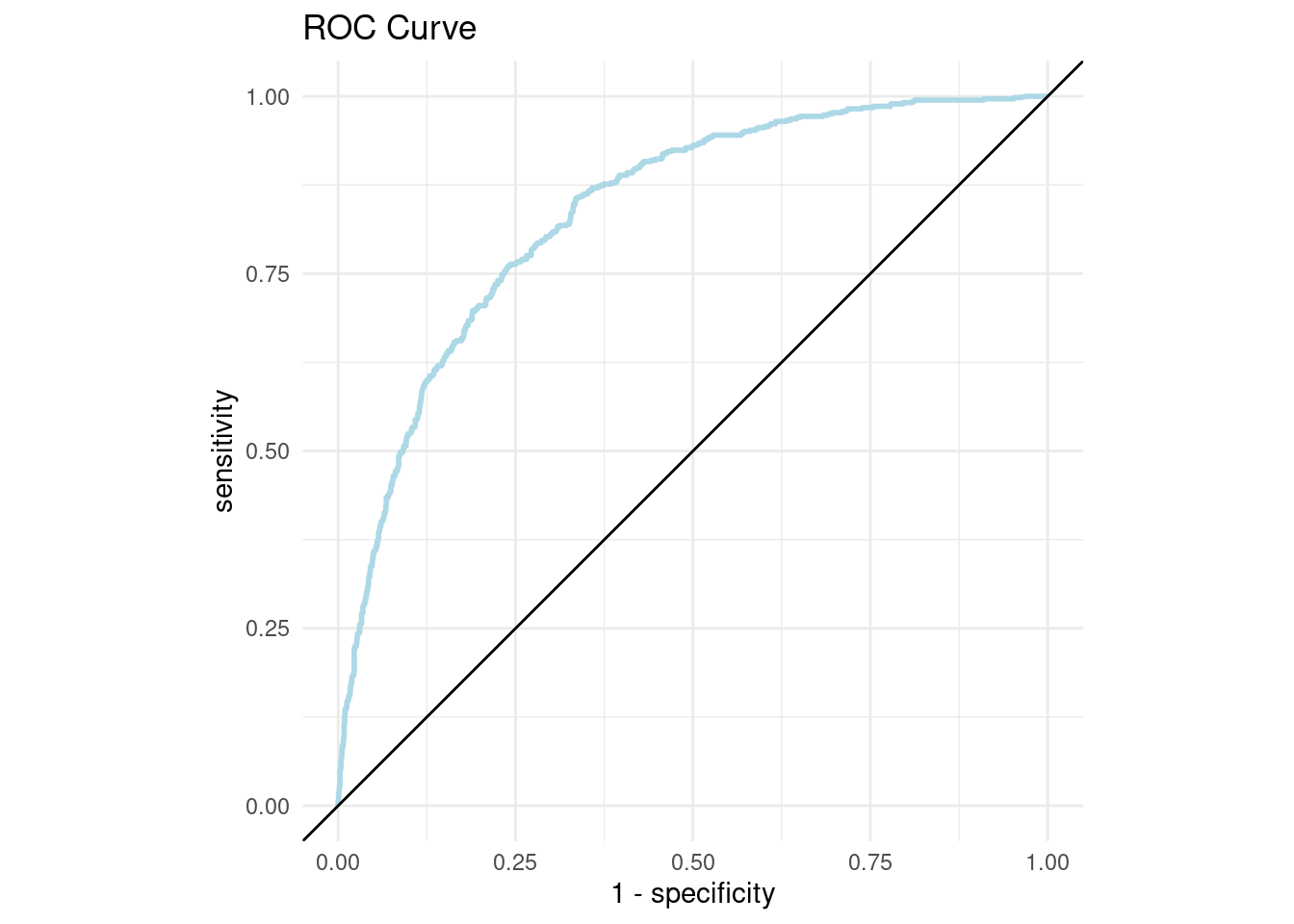
Pueden usar la app de shiny que nos permite jugar con el threshold de clasificación para tomar la mejor decisión.