Capítulo 13 Introducción a la Teoría de Gráficas.
13.1 ¿Qué es una gráfica?
Una gráfica es un objeto matemático que representa un conjunto de objetos y las relaciones entre ellos. Estos se usan para modelar fenómenos complejos, como la interacción en redes sociales, redes de comunicaciones, las relaciones entre citas de documentos, la configuración de compuestos químicos y demás.
import torch
import torch.nn as nn
from torch.nn import Linear
import torch.nn.functional as F
import torch_geometric
from torch_geometric.datasets import Planetoid
from torch_geometric.utils import (
to_dense_adj, to_networkx, degree
)
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
import pandas as pd
import random
# Load Zachary's Karate Club graph
G = nx.karate_club_graph()
print(f"Number of nodes: {G.number_of_nodes()}")## Number of nodes: 34## Number of edges: 78# Get the club membership attribute for coloring
club_labels = [G.nodes[i]['club'] for i in G.nodes]
# Color based on club membership ('Mr. Hi' or 'Officer')
color_map = [
'#FF5733' if club == 'Mr. Hi' else '#3371FF' for club in club_labels
]
# Draw the graph
plt.figure(figsize=(8, 6))
pos = nx.spring_layout(G) # positions for all nodes
nx.draw_networkx_nodes(G, pos, node_color=color_map)
nx.draw_networkx_edges(G, pos, alpha=0.6)
nx.draw_networkx_labels(G, pos, font_color='white')## {0: Text(-0.04719248013020107, -0.24839125943933962, '0'), 1: Text(0.2527061933150169, -0.49853455876626895, '1'), 2: Text(0.18566695314916642, -0.21266682268175097, '2'), 3: Text(-0.008383036646563192, -0.6439993123881046, '3'), 4: Text(-0.5360248191245703, 0.024524280025362565, '4'), 5: Text(-0.5352479067701617, 0.3478180477965669, '5'), 6: Text(-0.38539660372494483, 0.4091755909484533, '6'), 7: Text(0.1861921144042323, -0.642247317123454, '7'), 8: Text(0.2904656263409677, -0.0182088686069621, '8'), 9: Text(0.6962549141862674, 0.38503225480269104, '9'), 10: Text(-0.7509492691755976, 0.06447817148422515, '10'), 11: Text(0.6280781559604274, -0.3883000117951177, '11'), 12: Text(-0.25653071196175875, -1.0, '12'), 13: Text(0.12514863455767072, -0.37006969238228743, '13'), 14: Text(-0.20682621275600446, -0.18837809006539058, '14'), 15: Text(0.38293168470972005, 0.4021947491463121, '15'), 16: Text(-0.505814793320668, 0.8885756854662669, '16'), 17: Text(0.048219906960434315, -0.9587541712942022, '17'), 18: Text(0.7305662673930557, 0.22666495046220123, '18'), 19: Text(0.48593445647478734, -0.47766709292332676, '19'), 20: Text(-0.38515409253901134, -0.21405119036828252, '20'), 21: Text(0.3918472870541829, -0.8416382729148583, '21'), 22: Text(0.3548745515028669, 0.6147570976490807, '22'), 23: Text(-0.09362049308351174, 0.4743109168716645, '23'), 24: Text(-0.1802597339264463, 0.8759848229910039, '24'), 25: Text(-0.3555479449878414, 0.6603804298322751, '25'), 26: Text(-0.5882110543793023, -0.052217857704892665, '26'), 27: Text(0.09624343417563727, 0.5092114605111109, '27'), 28: Text(-0.15261197898794066, 0.008646757903172543, '28'), 29: Text(-0.314306892645962, 0.18978119101271848, '29'), 30: Text(0.4484037616416584, -0.027980555679159046, '30'), 31: Text(-0.1773476911929115, 0.3696333299793844, '31'), 32: Text(0.03578559216621987, 0.15851367128534505, '32'), 33: Text(0.14010618136108588, 0.1734216659655616, '33')}## (np.float64(-0.9065084005153062), np.float64(0.8861253987327644), np.float64(-1.198300446973958), np.float64(1.086876132440225))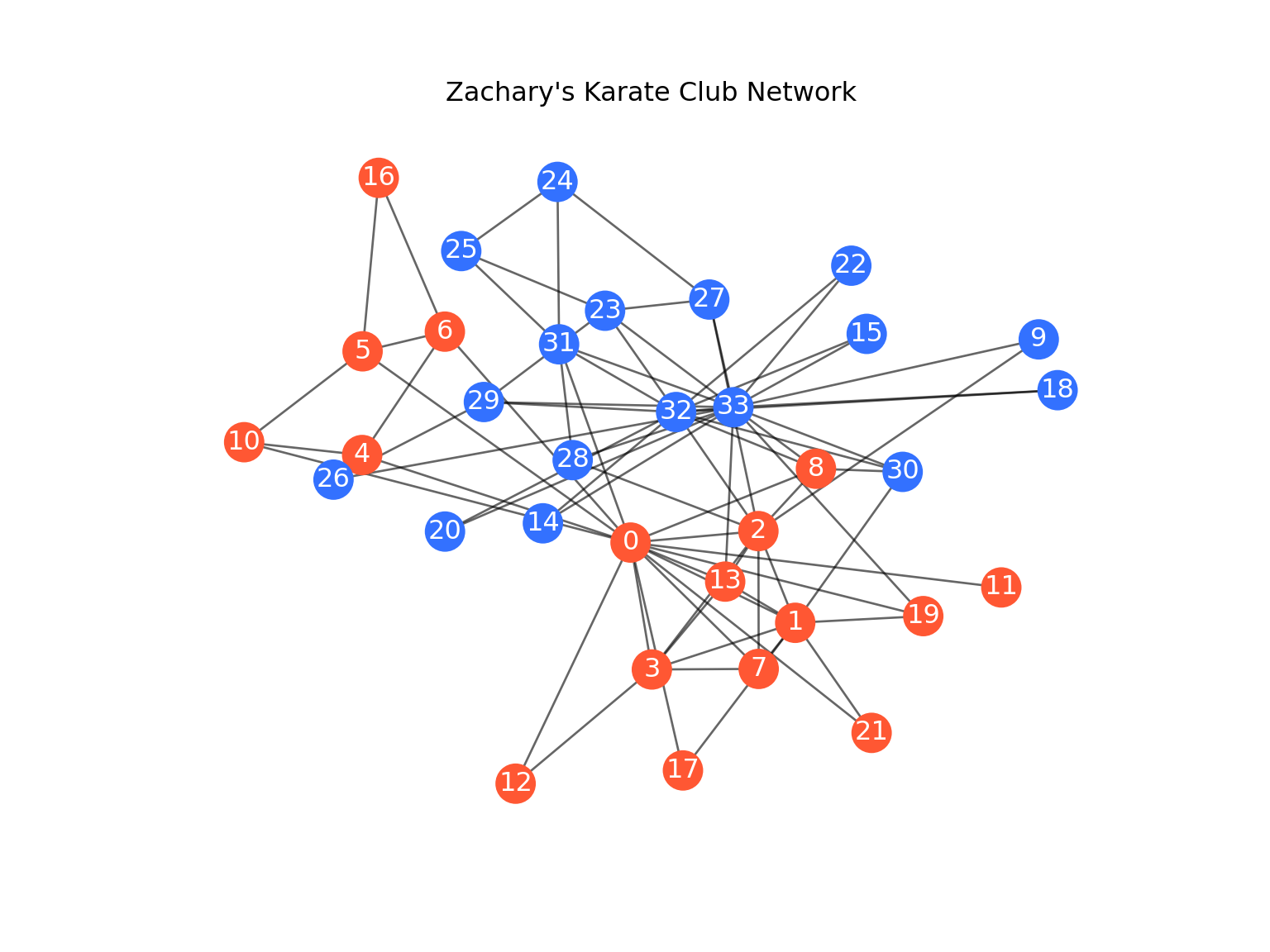
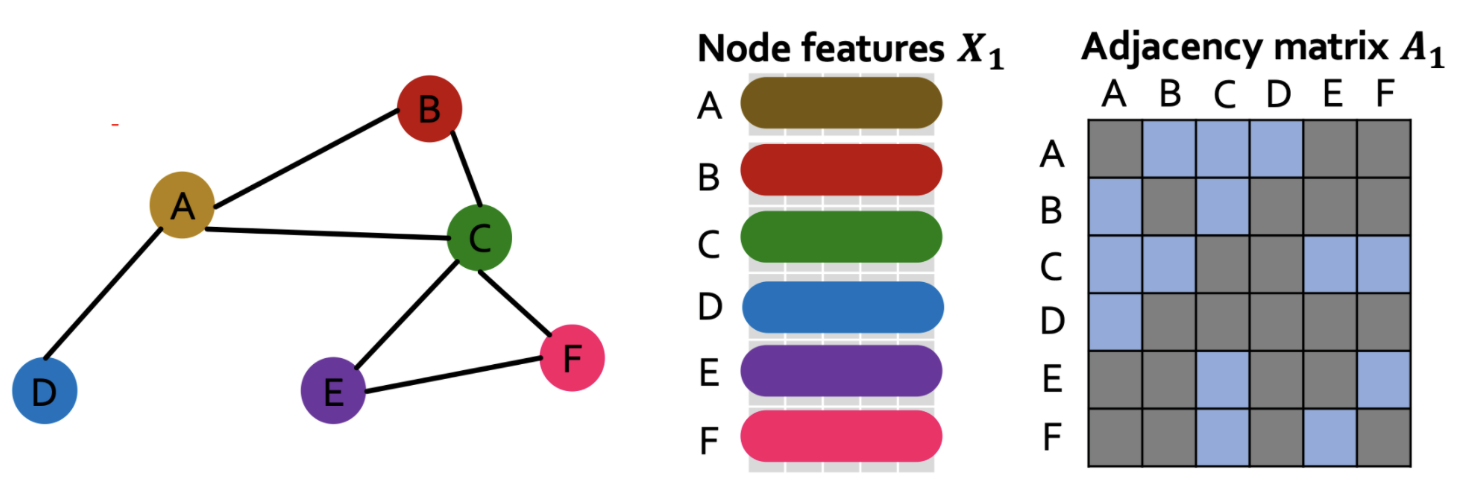
Matematicamente se representan como conjuntos de vértices (o nodos) \(V = \{v_1, \ldots, v_n \}\) y del conjunto de las relaciones entre ellas \(E = \{e_{i_1 i_j}, \ldots, e_{i_m i_m} \}\).
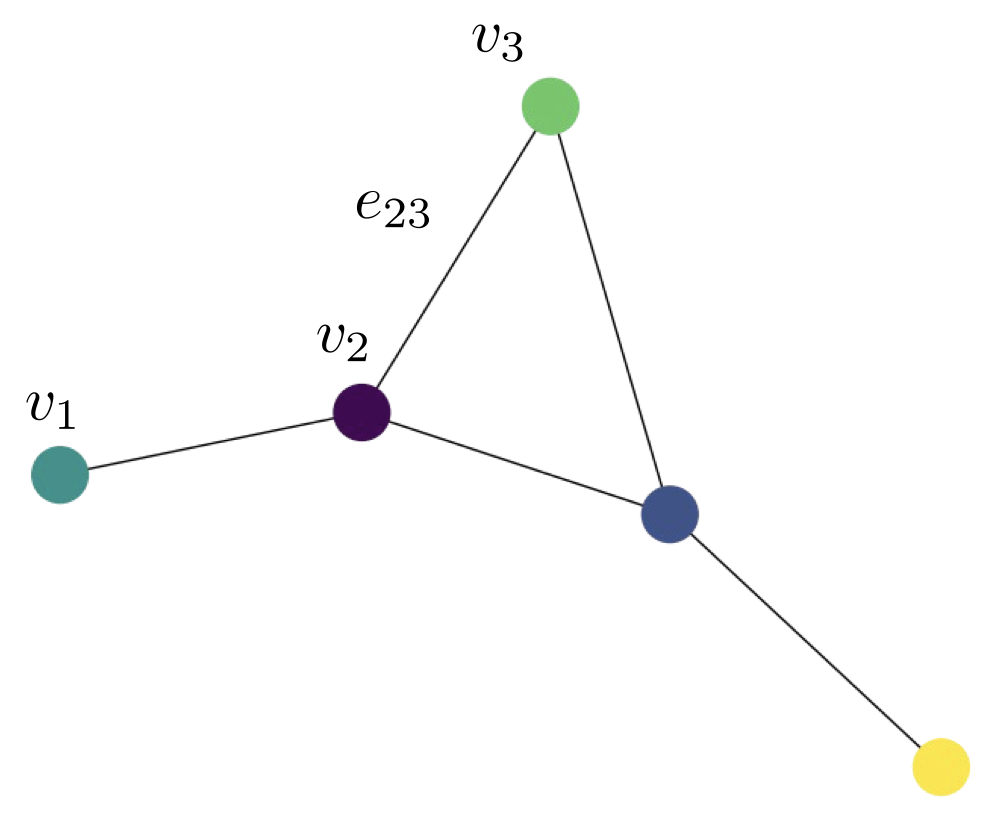
Si bien, el conjunto de aristas define la estructura de la gráfica es comun generar representaciones alternativas. Entre ellas se encuentran:
- Matriz de adjyacencias: \(A\in \mathbb{R}^n\), donde \(n\) es el número de vertices de la gráfica y las entradas de la matriz estan dadas como sigue
\[A_{ij} = \begin{cases} 1,& \text{ existe arista entre } v_i \text{ y }v_j\\ 0,& \text{ en otro caso } \end{cases}\]
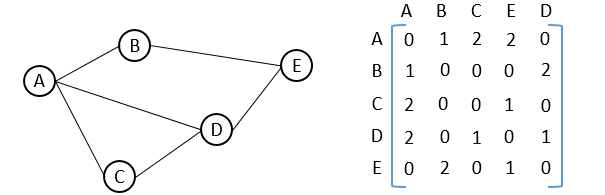 Es de notar que en la práctica, dicha matriz suele ser de tipo sparse, dado
que no todos los nodos están conectados.
Es de notar que en la práctica, dicha matriz suele ser de tipo sparse, dado
que no todos los nodos están conectados.
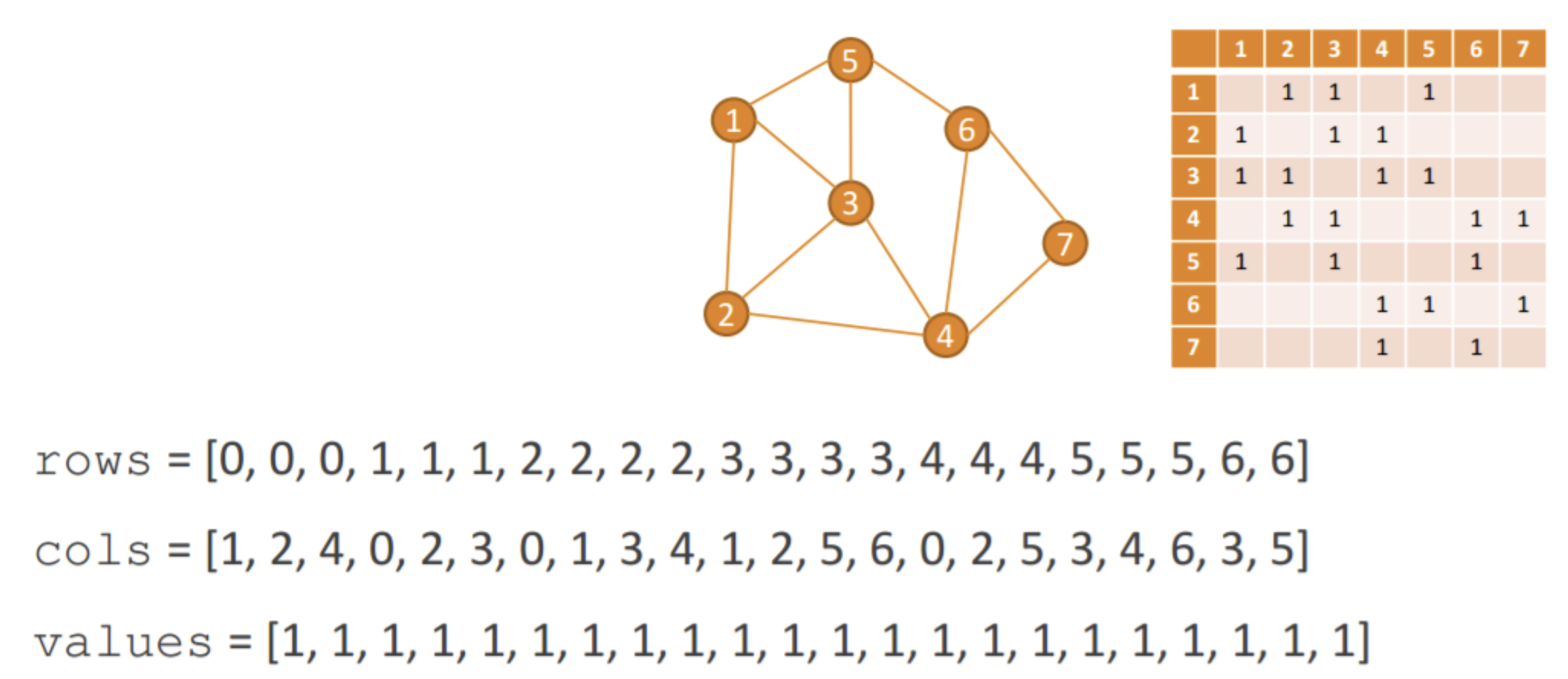
- Sparse Coodinate Format (COO): Es una representacion tensorial de tipo sparse de las estructura de la gráfica. La idea es solo almacenar los indices de los nodos que denotan las adyacencias en la gráfica omitiendo aquellos lugares donde no hay relaciones ente nodos. Véase el siguiente link.
- Por otro lado, se puede considerar de forma opcional incluir en el análisis a características numéricas y categorícas (features) de los vértices de la gráfica.
- Grado de sus vertices: el grado de un nodo \(deg(v_i)\) como a la cantidad de aristas donde dicho nodo está presente. Este se puede calcular como:
\[deg(v_i) = \sum_{i=1}^N A_{ij}\]
G = nx.Graph()
G.add_edges_from([('A', 'B'), ('A', 'C'), ('B', 'D'),
('B', 'E'), ('C', 'F'), ('C', 'G')])
# Draw the graph
plt.figure(figsize=(8, 6))
pos = nx.spring_layout(G) # positions for all nodes
nx.draw_networkx_nodes(G, pos)
nx.draw_networkx_edges(G, pos, alpha=0.6)
nx.draw_networkx_labels(G, pos, font_color='white')## {'A': Text(0.0014884134129522653, 0.00038927366611223594, 'A'), 'B': Text(0.27649108229581354, 0.5351300817099227, 'B'), 'C': Text(-0.27656878516697603, -0.5363259769209958, 'C'), 'D': Text(0.16389404009945505, 1.0, 'D'), 'E': Text(0.7198087698415417, 0.7144950449075653, 'E'), 'F': Text(-0.7180668173023278, -0.7138747005754214, 'F'), 'G': Text(-0.1670467031804588, -0.9998137227871826, 'G')}## (np.float64(-0.869043753952434), np.float64(0.870785706491648), np.float64(-1.2097941636798368), np.float64(1.2099804408926542))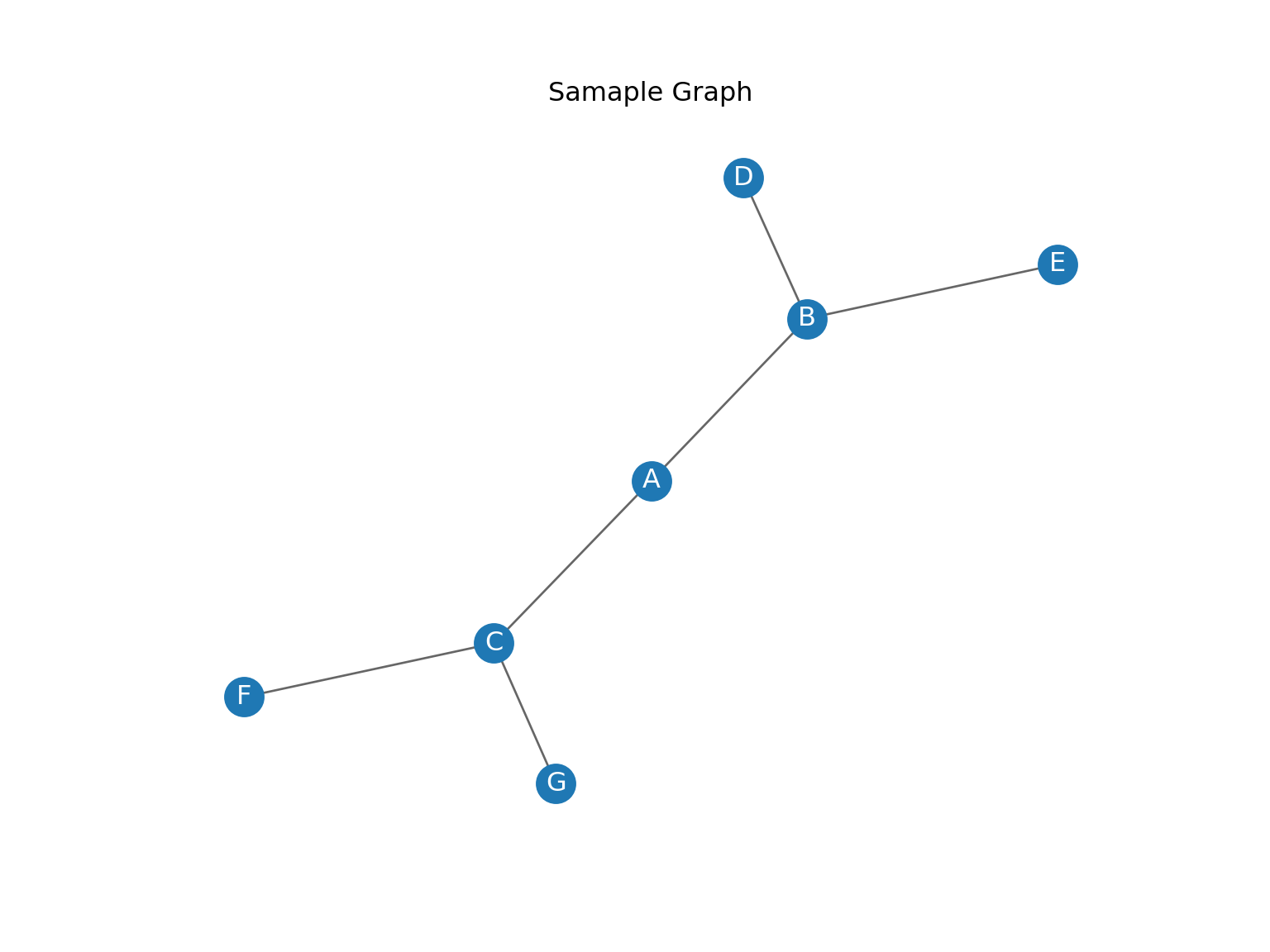
## deg(A) = 2## deg(B) = 313.2 Problemas clásicos de teoría de gráficas (selección)
13.2.1 Caminos y conectividad
Problema: determinar si dos nodos están conectados y cómo se propaga la información a través del grafo.
Aplicaciones: navegación y mapas, análisis de redes sociales, propagación de epidemias, redes de comunicación.
13.2.2 Detección de comunidades
Problema: identificar grupos de nodos densamente conectados entre sí.
Aplicaciones: segmentación de usuarios, análisis de redes sociales, biología de sistemas, recomendación de contenidos.
13.3 Ecosistema de Herramientas para el Trabajo con Grafos
- Software para Visualización y Análisis de Grafos
- Gephi: Herramienta open source la visualización interactiva y el análisis exploratorio de redes complejas y grandes grafos. https://gephi.org. La siguiente imagen fue generada en dicha herramienta
- Bases de datos de Grafos:
- Neo4j: Sistema de gestión de bases de datos orientada a grafos que incluye el Graph Data Science (GDS) Library para ejecutar algoritmos directamente sobre los datos almacenados.
- Memgraph: Base de datos de grafos con capacidades de Streaming https://memgraph.com
- AWS Neptune: Base de datos serveless, funcioina en la nube de AWS https://aws.amazon.com/es/neptune/
- Graphviz: Herramienta basada en scripts (lenguaje DOT) que permite la generación automática de diagramas de grafos de manera estructural y jerárquica.
- Librerías de Python para Manipulación y Algoritmos
- NetworkX: La librería de creación, manipulación y estudio de estructuras de red; flexible e implementa algoritmos clásicos. https://networkx.org/en/
- Graph: Es un framework de Spark para trabajar con gráficas en ambientes distribuidas (https://spark.apache.org/graphx/)
- Mercury-graph: Libreria de BBVA para gráficos, disponible en Mercury, cuenta con algoritmos implementados para Python y Spark. https://www.bbvaaifactory.com/es/graph-analytics-with-mercury-graph/
- Librerías de Deep Learning para Grafos (GNN)
PyTorch Geometric (PyG): Construida sobre PyTorch. Ofrece implementaciones de última generación para operaciones de convolución y pooling en grafos. https://pytorch-geometric.readthedocs.io/en/latest/
Deep Graph Library (DGL): Una librería optimizada y agnóstica al framework (compatible con PyTorch, TensorFlow y JAX), diseñada para facilitar la implementación de modelos GNN a escala industrial. https://www.dgl.ai
13.4 ¿Por qué combinar Graficas y Deep Learning?
Cuando los datos de un problema, ademas de features numéricas tambien incorporan estructura, puede resultar util tomarla en consideracion para tareas de ML.
Para ejemplificarlo, vamos a resolver el problema de clasificación de los datos del Cora de la libreria torch_geometric.datasets.
Este es un conjunto de datos de una red de citas bibliográficas que relaciona artículos científicos y citas bibliográficas de otros artículos en su texto. La tabla siguiente hace un resumen
| # | Atributo | Valor |
|---|---|---|
| 1 | Nodos | 2,708 (Artículos científicos) |
| 2 | Aristas | 10,556 (Citas) |
| 3 | Características (Features) | 1,433 (Vector binario de palabras clave, Bag-of-Words) |
| 4 | Clases | 7 categorías de investigación |
Las categorias de los artìculos son las siguientes:
| Categoria | Nombre | Descripción |
|---|---|---|
| 0 | Theory | Aspectos teóricos, algoritmos fundamentales y pruebas matemáticas. |
| 1 | Reinforcement Learning | Agentes que aprenden mediante prueba y error para maximizar recompensas. |
| 2 | Genetic Algorithms | Algoritmos de optimización inspirados en la evolución biológica. |
| 3 | Neural Networks | Modelos basados en capas de neuronas artificiales y Deep Learning. |
| 4 | Probabilistic Methods | Modelos que gestionan la incertidumbre (Redes Bayesianas, etc.). |
| 5 | Case Based | Sistemas de razonamiento basados en casos y analogías previas. |
class GraphUtils:
@staticmethod
def create_adjacency_matrix(data):
# Crea matriz de adyacencia
adjacency = to_dense_adj(data.edge_index)[0]
# Agrega una diagonal de unos (auto-referencia a nodos)
adjacency = adjacency + torch.eye(len(adjacency))
return adjacency
@staticmethod
def convert_to_networkx(graph, n_sample=None):
g = to_networkx(graph, node_attrs=["x"])
y = graph.y.numpy()
if n_sample is not None:
sampled_nodes = random.sample(list(g.nodes), n_sample)
g = g.subgraph(sampled_nodes)
y = y[sampled_nodes]
return g, y
@staticmethod
def plot_graph(g, y):
plt.figure(figsize=(9, 7))
nx.draw_spring(g, node_size=30, arrows=False, node_color=y)
plt.show() Esta es una representación de una muestra de 1,000 artículos en el conjunto Cora.
 En complemento, ahora veremos el arreglo tabular de datos donde cada reglón es un
artículo, los features son el Bag of Words del corpus del artículo con las
palabras de toda la colección y la categoría a la que pertenece dicho artículo.
En complemento, ahora veremos el arreglo tabular de datos donde cada reglón es un
artículo, los features son el Bag of Words del corpus del artículo con las
palabras de toda la colección y la categoría a la que pertenece dicho artículo.
cora_features = pd.DataFrame(dataset.x.numpy(),columns=["word"+str(i) for i in range(1433)])
cora_features["category"] = data.y
cora_features[cora_features.columns[-5:]].head(20)## word1429 word1430 word1431 word1432 category
## 0 0.0 0.0 0.0 0.0 3
## 1 0.0 0.0 0.0 0.0 4
## 2 0.0 0.0 0.0 0.0 4
## 3 0.0 0.0 0.0 0.0 0
## 4 0.0 0.0 0.0 0.0 3
## 5 0.0 0.0 0.0 0.0 2
## 6 0.0 0.0 0.0 0.0 0
## 7 0.0 0.0 0.0 0.0 3
## 8 0.0 0.0 0.0 0.0 3
## 9 0.0 0.0 0.0 0.0 2
## 10 0.0 0.0 0.0 0.0 0
## 11 0.0 0.0 0.0 0.0 0
## 12 0.0 0.0 0.0 0.0 4
## 13 0.0 0.0 0.0 0.0 3
## 14 0.0 0.0 0.0 0.0 3
## 15 0.0 0.0 0.0 0.0 3
## 16 0.0 0.0 0.0 0.0 2
## 17 0.0 0.0 0.0 1.0 3
## 18 0.0 0.0 0.0 0.0 1
## 19 0.0 0.0 0.0 0.0 3Para la comparativa consistirá en los siguientes:
Un modelo de tipo Multilayer Percepton con dos capas que usa las features numéricas para predecir la categoría a la que corresponde cada artículos
Un modelo que combina capaz, que conectan los datos las features numèricas a una capa lineal y despúes multiplican la salida por la matriz de adyacencias para involucrar la estrucura de la red.
13.4.1 A. Multilayer Percepton en las features tabulares de Cora
# Define MLP model
class MLP(torch.nn.Module):
def __init__(self, dim_in, dim_h, dim_out):
super().__init__()
self.linear1 = Linear(dim_in, dim_h)
self.linear2 = Linear(dim_h, dim_out)
def forward(self, x):
x = self.linear1(x)
x = torch.relu(x)
x = self.linear2(x)
return F.log_softmax(x, dim=1)
def fit(self, data, epochs, learning_rate=0.01, weight_decay=5e-4):
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(self.parameters(), lr=learning_rate, weight_decay=weight_decay)
self.train()
for epoch in range(epochs+1):
optimizer.zero_grad()
out = self(data.x)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
acc = self.accuracy(out[data.train_mask].argmax(dim=1), data.y[data.train_mask])
loss.backward()
optimizer.step()
if epoch % 20 == 0:
val_loss = criterion(out[data.val_mask], data.y[data.val_mask])
val_acc = self.accuracy(out[data.val_mask].argmax(dim=1), data.y[data.val_mask])
print(f'Epoch {epoch:>3} | Train Loss: {loss:.3f} | Train Acc:'
f' {acc*100:>5.2f}% | Val Loss: {val_loss:.2f} | '
f'Val Acc: {val_acc*100:.2f}%')
@torch.no_grad()
def test(self, data):
self.eval()
out = self(data.x)
acc = self.accuracy(out.argmax(dim=1)[data.test_mask], data.y[data.test_mask])
return acc
@staticmethod
def accuracy(y_pred, y_true):
return torch.sum(y_pred == y_true).item() / len(y_true)13.4.2 B. Modelo basado en una capa lineal que se multiplica por la matriz de adyacencia.
class GNNLayer(torch.nn.Module):
def __init__(self, dim_in, dim_out):
super().__init__()
self.linear = Linear(dim_in, dim_out, bias=False)
def forward(self, x, adjacency):
x = self.linear(x)
x = torch.sparse.mm(adjacency, x)
return xclass GNN(torch.nn.Module):
def __init__(self, dim_in, dim_h, dim_out):
super().__init__()
self.gnn1 = GNNLayer(dim_in, dim_h)
self.gnn2 = GNNLayer(dim_h, dim_out)
def forward(self, x, adjacency):
h = self.gnn1(x, adjacency)
h = torch.relu(h)
h = self.gnn2(h, adjacency)
return F.log_softmax(h, dim=1)
def fit(self, data, adjacency, epochs, learning_rate=0.01, weight_decay=5e-4):
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(self.parameters(), lr=learning_rate, weight_decay=weight_decay)
self.train()
for epoch in range(epochs+1):
optimizer.zero_grad()
out = self(data.x, adjacency)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
acc = MLP.accuracy(out[data.train_mask].argmax(dim=1), data.y[data.train_mask])
loss.backward()
optimizer.step()
if epoch % 20 == 0:
val_loss = criterion(out[data.val_mask], data.y[data.val_mask])
val_acc = MLP.accuracy(out[data.val_mask].argmax(dim=1), data.y[data.val_mask])
print(f'Epoch {epoch:>3} | Train Loss: {loss:.3f} | Train Acc:'
f' {acc*100:>5.2f}% | Val Loss: {val_loss:.2f} | '
f'Val Acc: {val_acc*100:.2f}%')
@torch.no_grad()
def test(self, data, adjacency):
self.eval()
out = self(data.x, adjacency)
acc = MLP.accuracy(out.argmax(dim=1)[data.test_mask], data.y[data.test_mask])
return accAhora entrenamos ambos modelos:
## MLP(
## (linear1): Linear(in_features=1433, out_features=16, bias=True)
## (linear2): Linear(in_features=16, out_features=7, bias=True)
## )## Epoch 0 | Train Loss: 1.959 | Train Acc: 10.71% | Val Loss: 2.03 | Val Acc: 9.60%
## Epoch 20 | Train Loss: 0.098 | Train Acc: 100.00% | Val Loss: 1.34 | Val Acc: 54.40%
## Epoch 40 | Train Loss: 0.013 | Train Acc: 100.00% | Val Loss: 1.42 | Val Acc: 54.20%
## Epoch 60 | Train Loss: 0.007 | Train Acc: 100.00% | Val Loss: 1.38 | Val Acc: 53.40%
## Epoch 80 | Train Loss: 0.008 | Train Acc: 100.00% | Val Loss: 1.32 | Val Acc: 54.60%
## Epoch 100 | Train Loss: 0.009 | Train Acc: 100.00% | Val Loss: 1.30 | Val Acc: 55.20%##
## MLP test accuracy: 55.60%adjacency = GraphUtils.create_adjacency_matrix(data)
gnn = GNN(dataset.num_features, 16, dataset.num_classes)
print(gnn)## GNN(
## (gnn1): GNNLayer(
## (linear): Linear(in_features=1433, out_features=16, bias=False)
## )
## (gnn2): GNNLayer(
## (linear): Linear(in_features=16, out_features=7, bias=False)
## )
## )## Epoch 0 | Train Loss: 1.940 | Train Acc: 18.57% | Val Loss: 1.95 | Val Acc: 16.40%
## Epoch 20 | Train Loss: 0.074 | Train Acc: 100.00% | Val Loss: 1.55 | Val Acc: 75.20%
## Epoch 40 | Train Loss: 0.007 | Train Acc: 100.00% | Val Loss: 2.26 | Val Acc: 73.80%
## Epoch 60 | Train Loss: 0.002 | Train Acc: 100.00% | Val Loss: 2.39 | Val Acc: 74.40%
## Epoch 80 | Train Loss: 0.001 | Train Acc: 100.00% | Val Loss: 2.35 | Val Acc: 74.60%
## Epoch 100 | Train Loss: 0.001 | Train Acc: 100.00% | Val Loss: 2.30 | Val Acc: 74.60%##
## GNN test accuracy: 76.60%## modelo accuracy
## 0 MLP 55.6
## 1 GNN 76.6En este ejemplo, el factor que marco la diferencia de la accion de la matriz de transaciones sobre los pesos de la red, pues intutivamente sirve para comunicar la estructura de relaciones de los nodos en el proceso de aprendizaje.
Dicho modelo es una implementación dummy de una familia conocida como Graph Convolutional Networks que abordaremos más adelante.
13.4.3 ¿Qué esta haciendo la red?
En este caso usaremos los datos del Karate Club presentes en PyTorch Geoemtric.
Entrenaremos nuevamente una red con la misma idea previa, que las features numéricas sean multiplicadas por la matriz de adyancencia
from torch_geometric.datasets import KarateClub
# Import dataset from PyTorch Geometric
dataset = KarateClub()
data = dataset[0]Podemos acceder a la información de la gráfica:
## KarateClub()## ------------## Number of graphs: 1## Number of features: 34## Number of classes: 4En este caso las features numéricas son solo encoding de los nodos con el indice que se han numerado:
## x = torch.Size([34, 34])## tensor([[1., 0., 0., ..., 0., 0., 0.],
## [0., 1., 0., ..., 0., 0., 0.],
## [0., 0., 1., ..., 0., 0., 0.],
## ...,
## [0., 0., 0., ..., 1., 0., 0.],
## [0., 0., 0., ..., 0., 1., 0.],
## [0., 0., 0., ..., 0., 0., 1.]])## edge_index = torch.Size([2, 156])## x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 ... x22 x23 x24 x25 x26 x27 x28 x29 x30 x31 x32 x33 x34
## 0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
## 1 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
## 2 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
## 3 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
## 4 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
##
## [5 rows x 34 columns]from torch_geometric.utils import to_networkx
G = to_networkx(data, to_undirected=True)
plt.figure(figsize=(12,12))
plt.axis('off')## (np.float64(0.0), np.float64(1.0), np.float64(0.0), np.float64(1.0))nx.draw_networkx(G,
pos=nx.spring_layout(G, seed=0),
with_labels=True,
node_size=400,
node_color=data.y,
cmap="hsv",
vmin=-2,
vmax=3,
width=0.8,
edge_color="grey",
font_size=14
)
plt.show()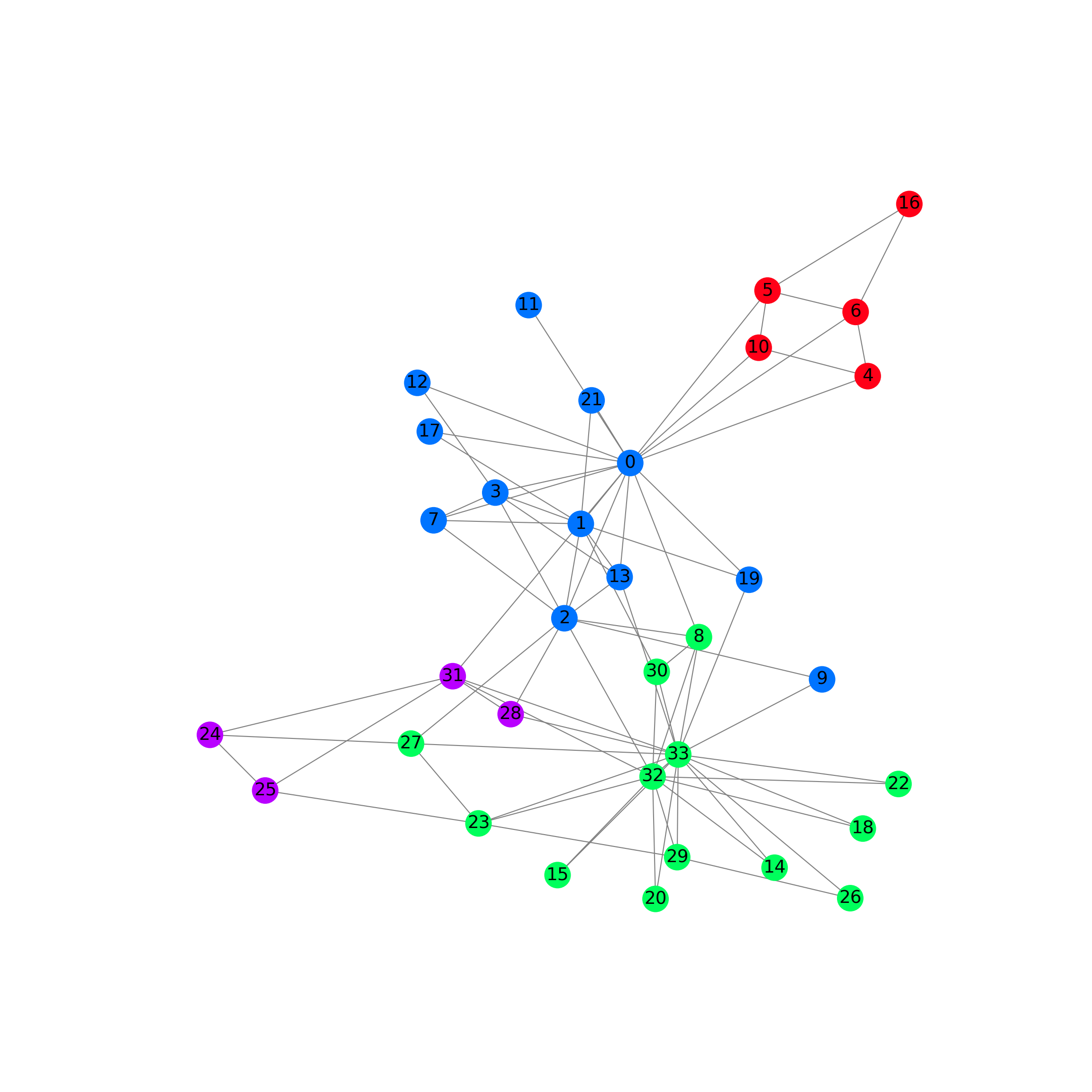
from torch.nn import Linear
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
self.gcn = GCNConv(dataset.num_features, 3)
self.out = Linear(3, dataset.num_classes)
def forward(self, x, edge_index):
h = self.gcn(x, edge_index).relu()
z = self.out(h)
return h, z
model = GCN()
print(model)## GCN(
## (gcn): GCNConv(34, 3)
## (out): Linear(in_features=3, out_features=4, bias=True)
## )criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.02)
# Calculate accuracy
def accuracy(pred_y, y):
return (pred_y == y).sum() / len(y)
# Data for animations
embeddings = []
losses = []
accuracies = []
outputs = []
# Training loop
for epoch in range(201):
# Clear gradients
optimizer.zero_grad()
# Forward pass
h, z = model(data.x, data.edge_index)
# Calculate loss function
loss = criterion(z, data.y)
# Calculate accuracy
acc = accuracy(z.argmax(dim=1), data.y)
# Compute gradients
loss.backward()
# Tune parameters
optimizer.step()
# Store data for animations
embeddings.append(h)
losses.append(loss)
accuracies.append(acc)
outputs.append(z.argmax(dim=1))
# Print metrics every 10 epochs
if epoch % 10 == 0:
print(f'Epoch {epoch:>3} | Loss: {loss:.2f} | Acc: {acc*100:.2f}%')## Epoch 0 | Loss: 1.32 | Acc: 35.29%
## Epoch 10 | Loss: 1.17 | Acc: 70.59%
## Epoch 20 | Loss: 0.99 | Acc: 70.59%
## Epoch 30 | Loss: 0.78 | Acc: 85.29%
## Epoch 40 | Loss: 0.55 | Acc: 91.18%
## Epoch 50 | Loss: 0.34 | Acc: 100.00%
## Epoch 60 | Loss: 0.19 | Acc: 100.00%
## Epoch 70 | Loss: 0.11 | Acc: 100.00%
## Epoch 80 | Loss: 0.07 | Acc: 100.00%
## Epoch 90 | Loss: 0.04 | Acc: 100.00%
## Epoch 100 | Loss: 0.03 | Acc: 100.00%
## Epoch 110 | Loss: 0.02 | Acc: 100.00%
## Epoch 120 | Loss: 0.02 | Acc: 100.00%
## Epoch 130 | Loss: 0.02 | Acc: 100.00%
## Epoch 140 | Loss: 0.01 | Acc: 100.00%
## Epoch 150 | Loss: 0.01 | Acc: 100.00%
## Epoch 160 | Loss: 0.01 | Acc: 100.00%
## Epoch 170 | Loss: 0.01 | Acc: 100.00%
## Epoch 180 | Loss: 0.01 | Acc: 100.00%
## Epoch 190 | Loss: 0.01 | Acc: 100.00%
## Epoch 200 | Loss: 0.01 | Acc: 100.00%plt.rcParams["animation.bitrate"] = 3000
def draw_predicted_graph(i):
G = to_networkx(data, to_undirected=True)
fig = plt.figure(figsize=(12, 12))
plt.axis('off')
nx.draw_networkx(G,
pos=nx.spring_layout(G, seed=0),
with_labels=True,
node_size=300,
node_color=outputs[i].numpy(),
cmap="hsv",
vmin=0,
vmax=5,
width=0.8,
edge_color="grey",
font_size=14
)
plt.title(
f'Epoch {i} | Loss: {losses[i]:.2f} | Acc: {accuracies[i]*100:.2f}%',
fontsize=18, pad=20)
plt.show()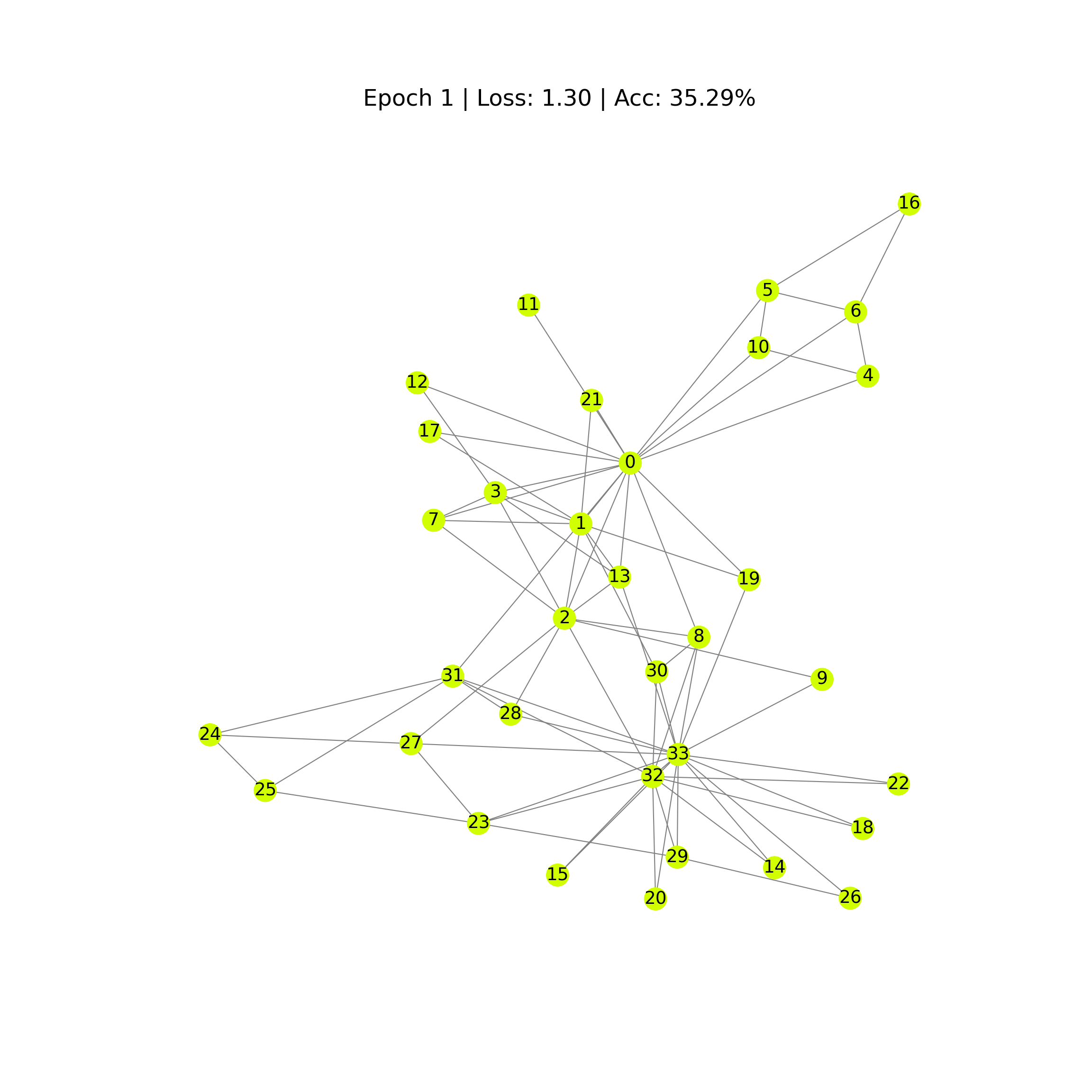
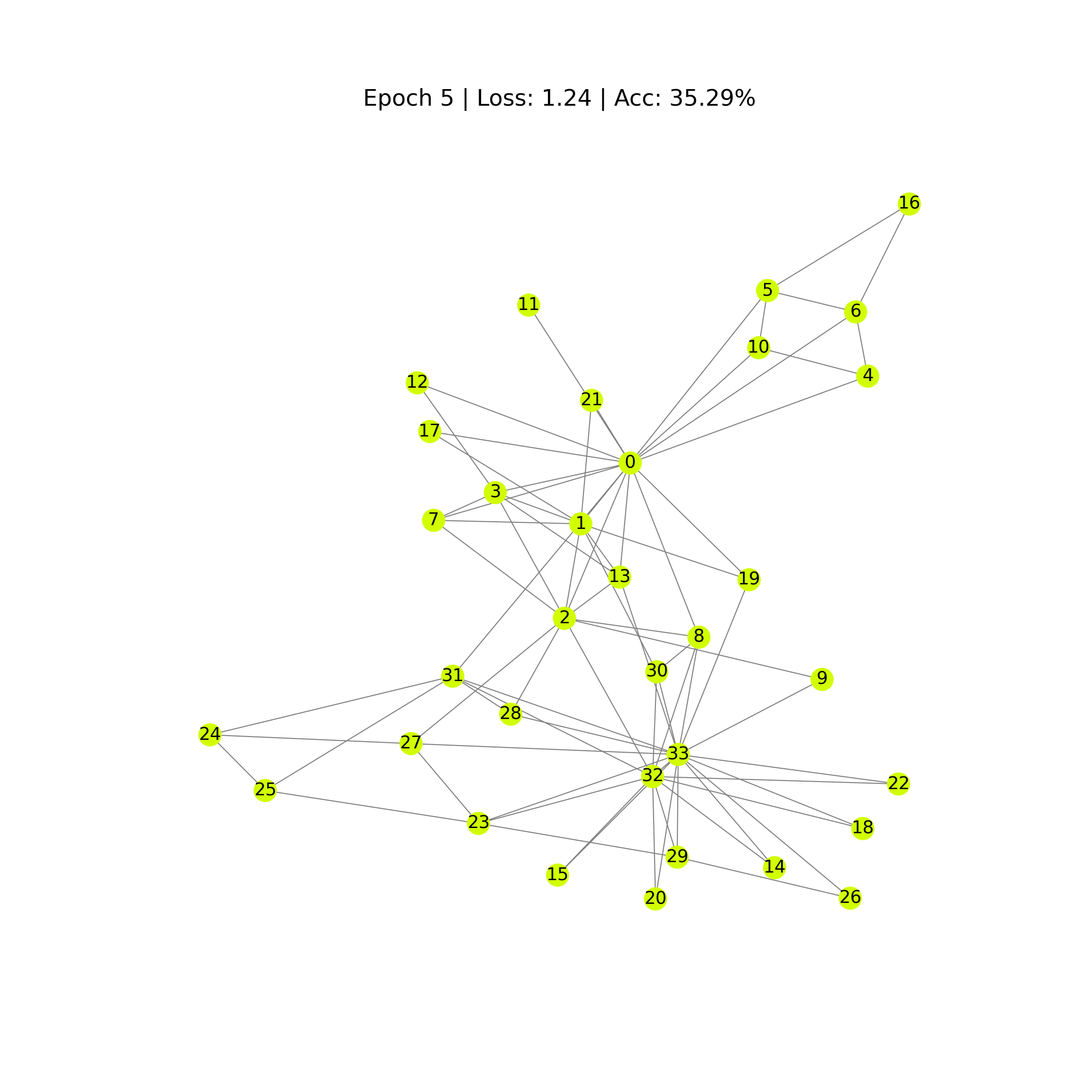
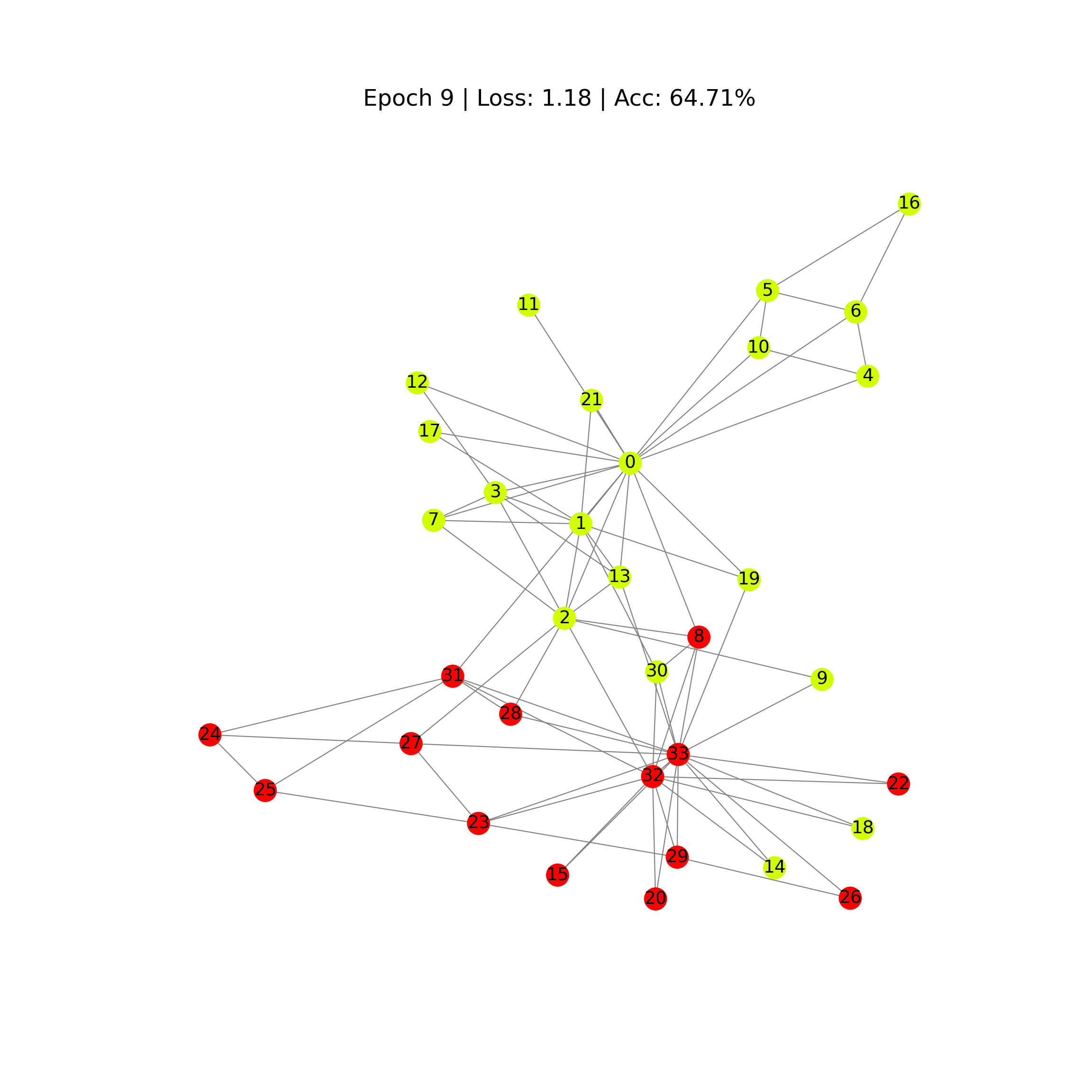
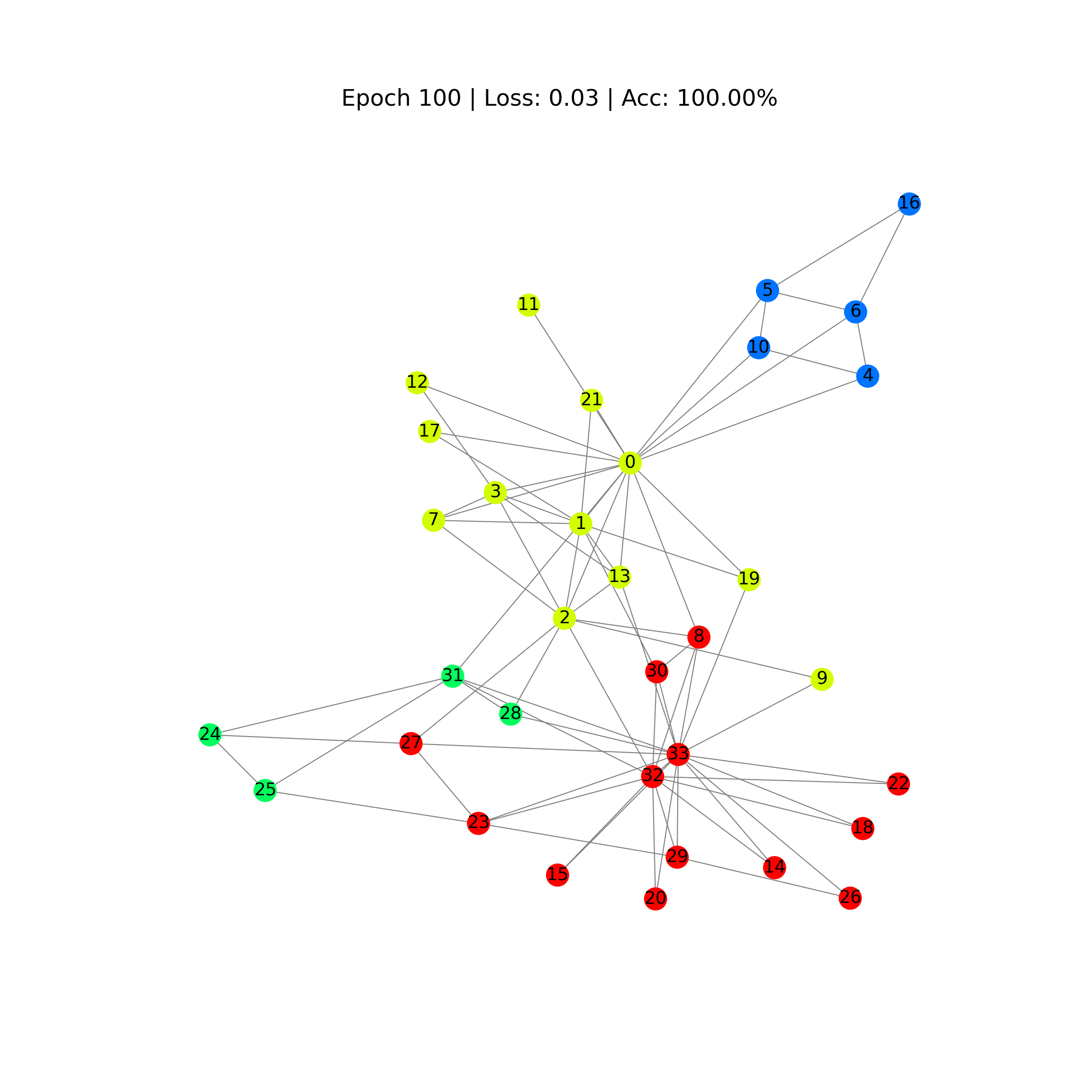
En las imágenes se aprecia como poco a poco, los pesos se van ajustando, a través de la información de la matriz de adyancias, para predecir las etiquetas de los nodos.
13.5 Tipos de problemas de GNN
El aprendizaje automático en grafos se presenta en diversas modalidades:
Aprendizaje Supervisado/Semi-supervisado:
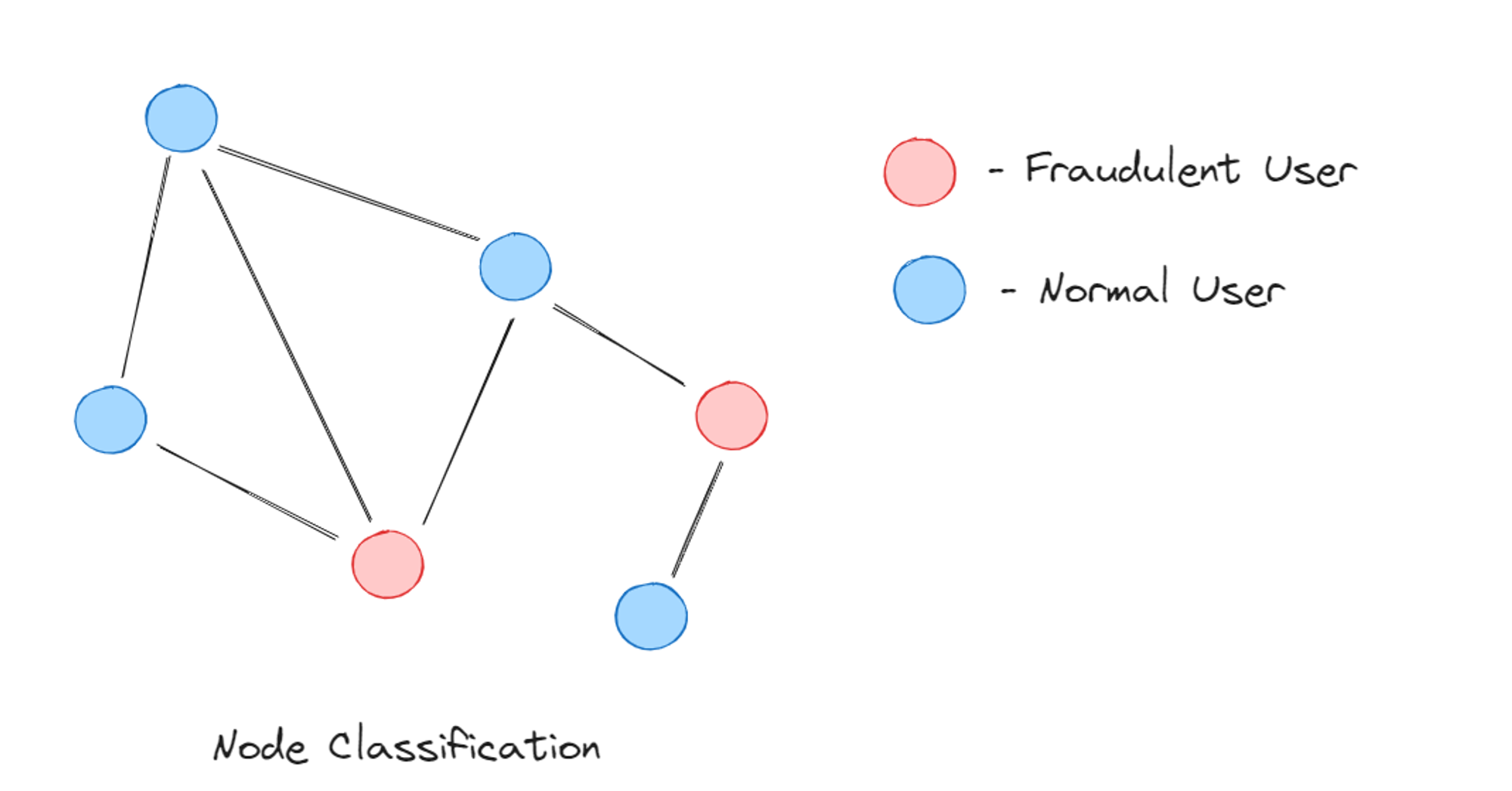
- Clasificación de Nodos (o Aristas): Nodos etiquetados → etiquetar otros nodos.
- Ejemplos: Marketing (orientado/segmentaciones), predicción de interfaces proteicas.
- Clasificación de Grafos: Grafos etiquetados → etiquetar nuevo grafo.
- Ejemplos: Clasificación de moléculas, predicción de la eficacia de fármacos.
- Clasificación de Nodos (o Aristas): Nodos etiquetados → etiquetar otros nodos.
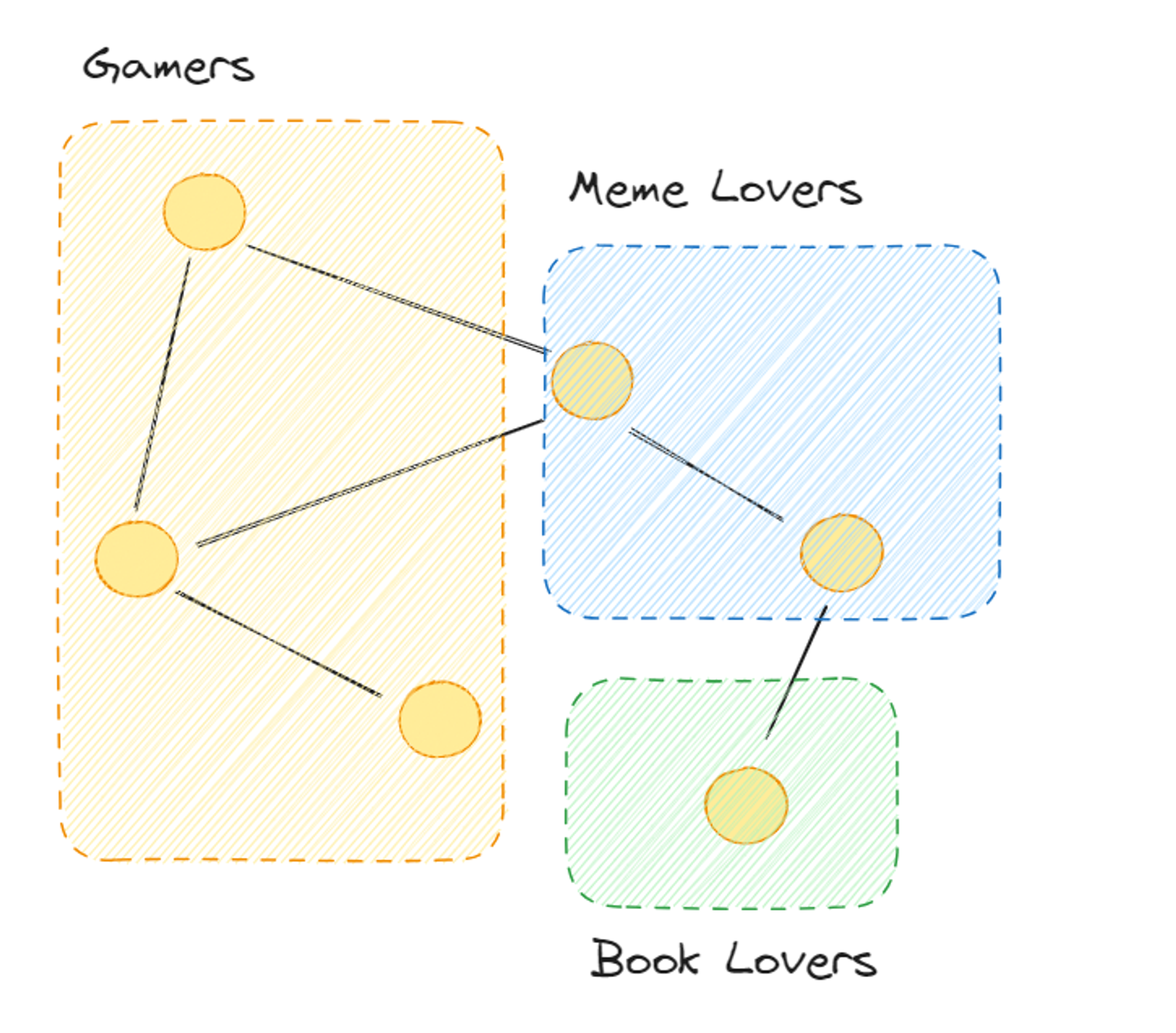
- Aprendizaje No Supervisado (y Semi-supervisado)
- Ejemplos:
- Detección de Comunidades: Un grafo → agrupar nodos
- Análisis de redes sociales.
- Ejemplos:
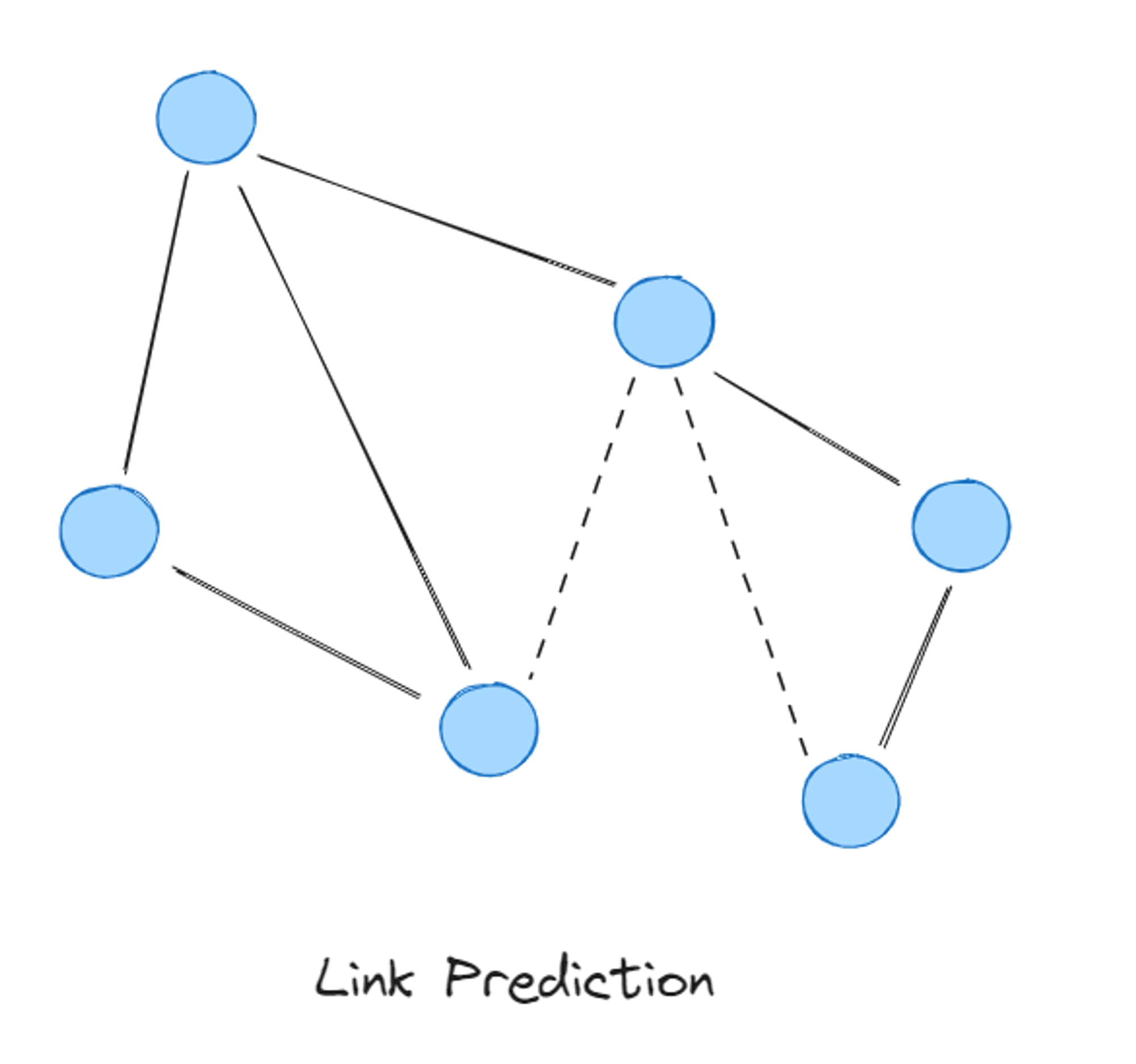
- Link prediction (o Vínculos): Un grafo → ¿posible nueva arista?
- Ejemplos: Sistemas de recomendación. Cabe mencionar que Uber usa modelos de este este estilo para hacer recomendaciones de comida https://www.uber.com/en-MX/blog/uber-eats-graph-learning/
- Otros tareas:
- Predicción (de nodo, de arista) en grafos dinámicos (simulación de sistemas físicos),
- Generación de gráficas (diseño de fármacos)
- Predicción de Tráfico: Google Maps hace estimaciones de condiciones de tráfico empleando Graph Nuera Networks https://deepmind.google/blog/traffic-prediction-with-advanced-graph-neural-networks/
13.6 ¿Existe un Teorema de Aproximación Univeral (TAU) para GNN’s?
Muchas pruebas del existentes del TAU para GNN son extensiones de del Teorema de Stone-Weierstrass,
Un tema a resolver en problema a resolver es si dos gráficas son isomórficas.
- Weisfeiler y Leman idearon una heurística que trata de determinar si dos gráficas son isomórficas entre si.
- Los resultados algoritmos son invariantes ante permutaciones de etiquetado de las gráficas
- En la práctica, es muy dificil encontrar gráficas isomórficas entre si.
Algunos resultados prueban la universalidad bajo ciertas condiciones:
- Maron et al. On the Universality of Invariant Networks (2019) “G-invariant networks are universal if high-order tensors are allowed (..)”
- Universal Invariant and Equivariant Graph Neural Network (2019) “GNNs are universal approximators in probability for node classification & regression tasks, as they can approximate any measurable function that satisfies the 1–WL equivalence on nodes”
13.7 Enfoques de aprendizaje transductivo e inductivo
Aprendizaje Transductivo: En este paradigma, el modelo se entrena considerando todo el grafo disponible, es decir, con todos los nodos y sus relaciones (aristas) presentes durante la fase de entrenamiento, incluso aquellos cuya informacion no se utiliza directamente para el cálculo de la función de pérdida.
Nota: Bajo dicho enfoque, un modelo aprende representaciones (embeddings) dependientes de la estructura completa del grafo, por lo que no puede generalizar a nodos o subgrafos no observados durante el entrenamiento.
Aprendizaje Inductivo: reservan conjuntos de datos de entrenamiento y prueba separados. El proceso de aprendizaje ingesta los datos de entrenamiento y, a continuación, el modelo aprendido se prueba utilizando los datos de prueba, que no ha observado antes en ninguna capacidad.
![]()